Spring Data JPA 实体类中常用注解说明
javax.persistence 介绍
Spring Data JPA 采用约定大于配置的思想,默认了很多东西
JPA是存储业务实体关联的实体来源,它显示定义了如何定义一个面向普通Java对象(POJO)作为实体,以及如何与管理关系实体提供一套标准
javax.persistence位于hibernate-jpa-**.jar 包里面
jpa类层次结构:
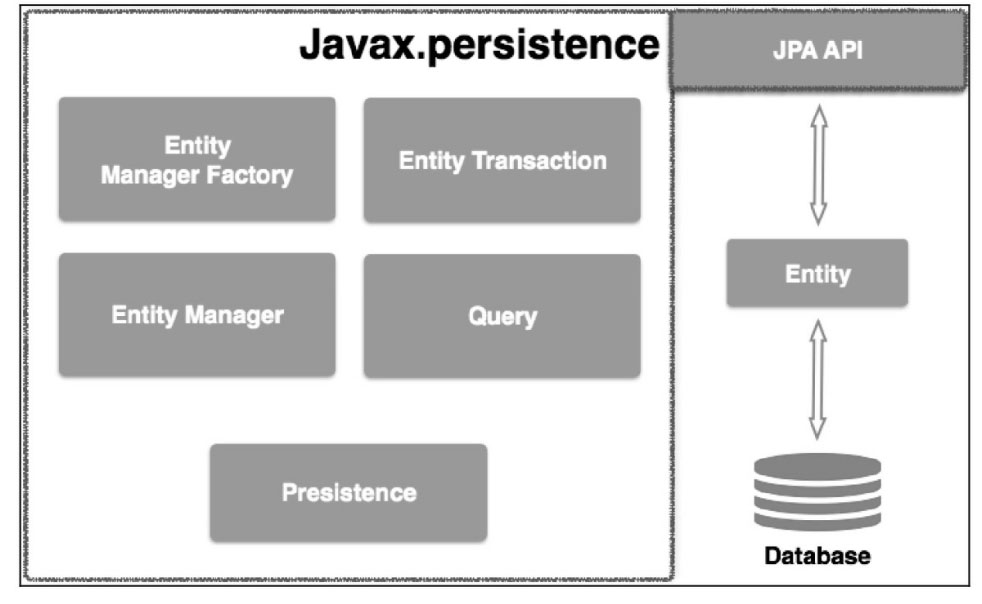
JPA类层次结构的显示单元:
| 单元 | 描述 |
| EntityManagerFactory | 一个EntityManager的工厂类,创建并管理多个EntityManager实例 |
| EntityManager | 一个接口,管理持久化操作的对象,工厂原理类似工厂的查询实例 |
| Entity | 实体是持久性对象,是存储在数据库中的记录 |
| EntityTransaction | 与EntityManager是一对一的关系,对于每一个EntityManager的操作由EntityTransaction类维护 |
| Persistence | 这个类包含静态方法来获取EntityManagerFactory实例 |
| Query | 该接口由每个JPA供应商实现,能够获得符合标准的关系对象 |
基本注解
@Entity
@Entity定义对象将会成为被JPA管理的实体,将映射到指定的数据库表
public @interface Entity {
String name() default "";
}
@Table
@Table指定数据库的表名
public @interface Table {
// 表的名字,可选,默认实体类名为表的名称(驼峰命名规则)
String name() default "";
// 此表的catlog,可选
String catalog() default "";
// 此表所在的schema,可选
String schema() default "";
// 唯一性约束,只有在创建表的时候有用,默认不需要
UniqueConstraint[] uniqueConstraints() default {};
// 索引,只有创建表的时候有用,默认不需要
Index[] indexes() default {};
}
@Id
定义属性为数据库中的主键,一个实体必须有一个
@IdClass
@IdClass利用外部类的联合主键
public @interface IdClass {
// 联合主键的类
Class value();
}
- 作为联合主键类,需要满足以下要求:
- 必须实现Serializable
- 必须有默认的public无参构造方法
- 必须覆盖equals和hashCode方法(EntityManager通过find方法查找Entity时是根据equals来判断的)
用法:
(1)假设user_article表中的联合主键是 title 与create_user_id,联合主键类代码如下:
@Data
public class UserArticleKey implements Serializable {
private String title;
private Long createUserId;
public UserArticleKey() {
}
public UserArticleKey(String title, String content, Long createUserId) {
this.title = title;
this.createUserId = createUserId;
}
}
(2)user_article表实体类如下:
@Entity
@IdClass(value = UserArticleKey.class)
@Data
public class UserArticle {
private Integer id;
@Id
private String title;
@Id
private Long createUserId;
}
(3) repository 类如下:
public interface ArticleRepository extends JpaRepository<UserArticle, UserArticleKey> {
}
(4)调用代码如下:
@Test
public void testUnionKey(){
Optional<UserArticle> userArticle = this.articleRepository.findById(new UserArticleKey("新闻",1L));
if (userArticle.isPresent()){
System.out.println(userArticle.get());
}
}
@GenerateValue
主键生成策略
public @interface GeneratedValue {
// Id 的生成策略
GenerationType strategy() default GenerationType.AUTO;
// 通过 Sequence生成Id, 常见Oracle生成规则,需要配合@SequenceGenerator使用
String generator() default "";
}
GenerationType
public enum GenerationType {
// 通过表产生主键,框架由表模拟序列产生主键(有益于数据库移植)
TABLE,
// 通过序列产生主键,通过@SequenceGenerator注解指定序列名,不支持MySQL
SEQUENCE,
// 采用数据ID自增长,一般用于MySQL
IDENTITY,
// JPA自动适配的策略,默认选项
AUTO;
private GenerationType() {
}
}
@Basic
属性是到数据表的字段的映射,实体类上的字段没有注解时默认为@Basic
public @interface Basic {
// 可选,默认为立即加载(EAGER),LZAY延迟加载(应用在大字段上)
FetchType fetch() default FetchType.EAGER;
// 可选,设置这个字段是否可为null,默认 true
boolean optional() default true;
}
@Transient
表示该属性并非一个到数据库表的字段的映射,表示非持久化属性,与@Basic作用相反,JPA映射的时候会忽略@Transient标记的字段
@Column
定义属性对应数据库中的列名
public @interface Column {
// 是语句库中表的列名, 默认字段名和属性名一样, 可选
String name() default "";
// 是否唯一,默认 false, 可选
boolean unique() default false;
// 是否允许空, 默认 true, 可选
boolean nullable() default true;
// 执行insert操作的时候是否包含此字段,默认 true, 可选
boolean insertable() default true;
// 执行update操作的时候是否包含此字段,默认 true, 可选
boolean updatable() default true;
// 该字段在数据库中的实际类型
String columnDefinition() default "";
// 当映射多个表时,指在哪张表的字段,默认为主表
String table() default "";
// 字段长度,字段类型为VARCHAR时有效
int length() default 255;
// 精度,当字段类型为double时候, precision表示数值总长度
int precision() default 0;
// 精度, 当字段类型为double时候, scale表示小数位数
int scale() default 0;
}
@Temporal
用来设置Date 类型的属性映射到对应精度的字段
@Temporal(Temporal.DATE)映射为日期@Temporal(Temporal.TIME)映射为日期(只有时间)@Temporal(Temporal.TIMESTAMP)映射为日期(日期+时间)
@Enumerated
映射menu枚举类型的字段
源码:
public @interface Enumerated {
// 映射枚举的类型
EnumType value() default EnumType.ORDINAL;
}
public enum EnumType {
// 映射枚举字段的下标
ORDINAL,
// 映射枚举的name
STRING;
}
如果使用 ORDINAL 在数据库中则会存储 0,1,2,3 这是一个索引值,这个索引值是由enum中元素的位置决定,如果enum中元素位置出现不正确的变动
很可能与数据库中的数据无法对应,建议使用 STRING
用法:
@Entity(name = "t_user")
@Data
@Table
public class SystemUser implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Basic
private String uname;
private String email;
private String address;
@Enumerated(EnumType.STRING)
@Column(name = "user_gender")
private Gender sex;
public enum Gender{
MALE("男性"),
FEMALE("女性")
;
private String value;
Gender(String value) {
this.value = value;
}
}
}
@Lob
映射成数据库支持的大对象类型
Clob(Character Large Objects)类型是长字符串类型java.sql.Clob、Character[]、char[]和String将被映射为Clob类型Blob(Binary Large Objects)类型是字节型,java.sql.Blob,Byte[]、byte[]和实现了Serializable接口的类型将被映射为Blob类型Clob、Blob占用内存空间较大,一般配合@Basic(fetch=FetchType.LAZY)将其设置为延迟加载
@NamedNativeQueries、@NamedNativeQuerie、@SqlResultSetMappings、@SqlResultSetMapping、@ColumnResult
这几个注解一般配合使用,实际情况中不会自定义这些配置
@NamedNativeQueries({
@NamedNativeQuery(
name = "getUsers",
query = "select id,title,create_user_id,create_date from user_article order by create_date desc",
resultSetMapping = "userArticleMap"
)
})
@SqlResultSetMappings({
@SqlResultSetMapping(
name = "userArticleMap",
entities = {},
columns = {
@ColumnResult(name = "id"),
@ColumnResult(name = "title"),
@ColumnResult(name = "createUserId"),
@ColumnResult(name = "createDate"),
}
)
})
@Entity
@IdClass(value = UserArticleKey.class)
@Data
public class UserArticle {
@Column
private Integer id;
@Id
private String title;
@Id
private Long createUserId;
private Date createDate;
}
关联关系注解
@JoinColumn 定义外键关联的字段名称
主要配合 @OneToOne、@ManyToOne、@OneToMany一起使用,单独使用没有意义
@JoinColumns 定义多个字段的关联关系
public @interface JoinColumn {
// 目标表的字段名,必填
String name() default "";
// 本实体类的字段名, 非必填, 默认本表ID
String referencedColumnName() default "";
// 外键字段是否唯一, 可选
boolean unique() default false;
// 外键字段是否允许为空, 可选
boolean nullable() default true;
// 是否跟随一起新增, 可选
boolean insertable() default true;
// 是否跟随一起更新, 可选
boolean updatable() default true;
// 生成DDL的时候使用的SQL片段 可选
String columnDefinition() default "";
// 包含列的表的名称 , 可选
String table() default "";
// 外键约束类别, 默认为 默认约束行为, 可选
ForeignKey foreignKey() default @ForeignKey(ConstraintMode.PROVIDER_DEFAULT);
}
@OneToOne 一对一关联关系
public @interface OneToOne {
// 关系目标实体, 默认为void.class, 可选
Class targetEntity() default void.class;
// 级联操作策略, PERSIST(级联新增)、REMOVE(级联删除)、REFRESH(级联刷新)、MERGE(级联更新)、ALL(全选)
// 默认表不会产生任何影响
CascadeType[] cascade() default {};
// 数据获取方式,EAGER(立即加载)、LAZY(延迟加载)
FetchType fetch() default EAGER;
// 是否允许空
boolean optional() default true;
// 关联关系被谁维护,非必填,一遍不需要特别指定
// mappedBy不能与@JoinColumn或者@JoinTable同时使用
// mappedBy的值是指另一方的实体里面属性的字段,而不是数据库字段,也不是实体的对象的名字,即另一方配置了@JoinColumn或者@JoinTable注解的属性的字段名称
String mappedBy() default "";
// 是否级联删除,和CascadeType.REMOVE 效果一样,任意配置一种即可生效
boolean orphanRemoval() default false;
}
用法:
@OneToOne
// name 为当前实体对应数据库表中的字段名
// referencedColumnName 为 SystemUser 实体中@Id标记的字段对应的数据库字段名
@JoinColumn(name = "create_user_id",referencedColumnName = "id")
private SystemUser createUser = new SystemUser();
双向关联:
@OneToOne(mappedBy = "createUser")
private UserArticle article = new UserArticle();
等价于mappedBy:
@OneToOne
@JoinColumn(name = "user_article_id",referencedColumnName = "id")
private UserArticle article = new UserArticle();
@OneToMany 与 @ManyToOne 一对多与多对一关联关系
OneToMany与ManyToOne可以相对存在,也可只存在一方
public @interface OneToMany {
Class targetEntity() default void.class;
// 级联操作策略
CascadeType[] cascade() default {};
// 数据获取方式
FetchType fetch() default LAZY;
// 关系被谁维护,单项的
String mappedBy() default "";
// 是否级联删除
boolean orphanRemoval() default false;
}
public @interface ManyToOne {
Class targetEntity() default void.class;
// 级联操作策略
CascadeType[] cascade() default {};
// 数据获取方式
FetchType fetch() default LAZY; // 关联是否可选。如果设置,若要为false,则必须始终存在非null关系。
boolean optional() default true;
}
@ManyToOne 映射的是一个实体对象
@Entity
@Data
public class UserArticle {
@Column
private Integer id;
@Id
private String title;
@ManyToOne(cascade = CascadeType.ALL,fetch = FetchType.EAGER)
@JoinColumn(name = "create_user_id",referencedColumnName = "id")
private SystemUser systemUser = new SystemUser();
private Date createDate;
}
@OneToMany 映射的是一个是列表
@Entity(name = "t_user")
@Data
@Table
public class SystemUser implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Basic
private String uname;
private String email;
private String address;
@Enumerated(EnumType.STRING)
private Gender sex;
@OneToMany
// name 当前表id
// create_user_id 目标表的关联字段
@JoinColumn(name = "id",referencedColumnName = "create_user_id")
private List<UserArticle> articleList = new ArrayList<>();
public enum Gender{
MALE("男性"),
FEMALE("女性")
;
private String value;
Gender(String value) {
this.value = value;
}
}
}
@OrderBy 排序关联查询
与@OneToMany一起使用
public @interface OrderBy {
/**
* 要排序的字段格式如下:
* orderby_list::= orderby_item [,orderby_item]*
* orderby_item::= [property_or_field_name] [ASC | DESC]
* 字段可以是实体属性,也可以是数据字段,默认ASC
*/
String value() default "";
}
用法:
@OneToMany
@JoinColumn(name = "id",referencedColumnName = "create_user_id")
@OrderBy("createDate DESC") // createDate 是 UserArticle 的实体属性
private List<UserArticle> articleList = new ArrayList<>();
@JoinTable 关联关系表
对象与对象之间有关联关系表的时候就用到,@JoinTable, 与@ManyToMany一起使用
public @interface JoinTable {
// 中间关联关系表名
String name() default "";
// 表的 catalog
String catalog() default "";
// 表的 schema
String schema() default "";
// 主连接表的字段
JoinColumn[] joinColumns() default {};
// 被连接表的字段
JoinColumn[] inverseJoinColumns() default {};
// 主连接外键约束类别
ForeignKey foreignKey() default @ForeignKey(PROVIDER_DEFAULT);
// 被连接外键约束类别
ForeignKey inverseForeignKey() default @ForeignKey(PROVIDER_DEFAULT);
// 唯一约束
UniqueConstraint[] uniqueConstraints() default {};
// 表的索引
Index[] indexes() default {};
}
用法:
@Entity
// 主连接表 blog
public class Blog {
@ManyToMany
@JoinTable(
name = "blog_tag_relation", // 关系表名称
joinColumns = @JoinColumn(name = "blog_id",referencedColumnName = "id"), // 主连接表配置
inverseJoinColumns = @JoinColumn(name = "tag_id",referencedColumnName = "id") // 被连接表配置
)
// tag 是被连接表
private List<Tag> tags = new ArrayList<>();
}
关于双向多对多:
双向多对多需要建立 @JoinTable的实体里, 在被连接表中的@ManyToMany中使用mappedBy="BlogTagRelation"进行配置
LeftJoin 与 Inner Join 可以提高查询效率
当使用@ManyToMany、@ManyToOne、@OneToMany、@OneToOne关联时候,SQL真正执行的时候,由一条主表查询和N条子表查询组成
会产生N+1问题
为了简单的提高查询效率,使用EntityGraph可以解决N+1条SQL的问题
@EntityGraph
@EntityGraph、@NamedEntityGraph用来提高查询效率(很好的解决了N+1条SQL的问题),两者需要配合使用,缺一不可
实体类:
@NamedEntityGraph(
name = "Blog.tags", attributeNodes = {
@NamedAttributeNode("tags")
}
)
@Entity
// 主连接表 blog
public class Blog {
@ManyToMany
@JoinTable(
name = "blog_tag_relation", // 关系表名称
joinColumns = @JoinColumn(name = "blog_id", referencedColumnName = "id"), // 主连接表配置
inverseJoinColumns = @JoinColumn(name = "tag_id", referencedColumnName = "id") // 被连接表配置
)
// tag 是被连接表
private List<Tag> tags = new ArrayList<>();
}
repository:
public interface BlogRepository extends JpaRepository<Blog,Long> {
@Override
@EntityGraph(value = "Blog.tags")
List<Blog> findAll();
}
关于关系查询的一些注意事项
所有注解要么全配置在字段上,要么配置在get方法上,不能混用,会无法启动
所有的关联都是支持单向关联和双向关联的,JSON序列化的时候使用双向注解会产生死循环,需要手动转化一次或使用@JsonIgnore
在所有的关联查询中,表一般是不需要简历外键索引的,@mappedBy的使用需要注意
级联删除比较危险,建议考虑清楚或完全掌握
不同的关联关系的配置,@JoinColumn里面的name,referencedColumnName代表的意思是不一样的
当配置这些关联关系的时候建议直接在表上把外键关系简历好,然后用开发工具直接生成,这样可以减少调试时间
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
以上是 Spring Data JPA 实体类中常用注解说明 的全部内容, 来源链接: utcz.com/p/250912.html