Java算法实战之排一亿个随机数
前言
插入排序狭义上指的是简单插入排序(选择集合,比较大小,插入元素),广义上还应该包括希尔排序(分治思想)及其两种实现方式,
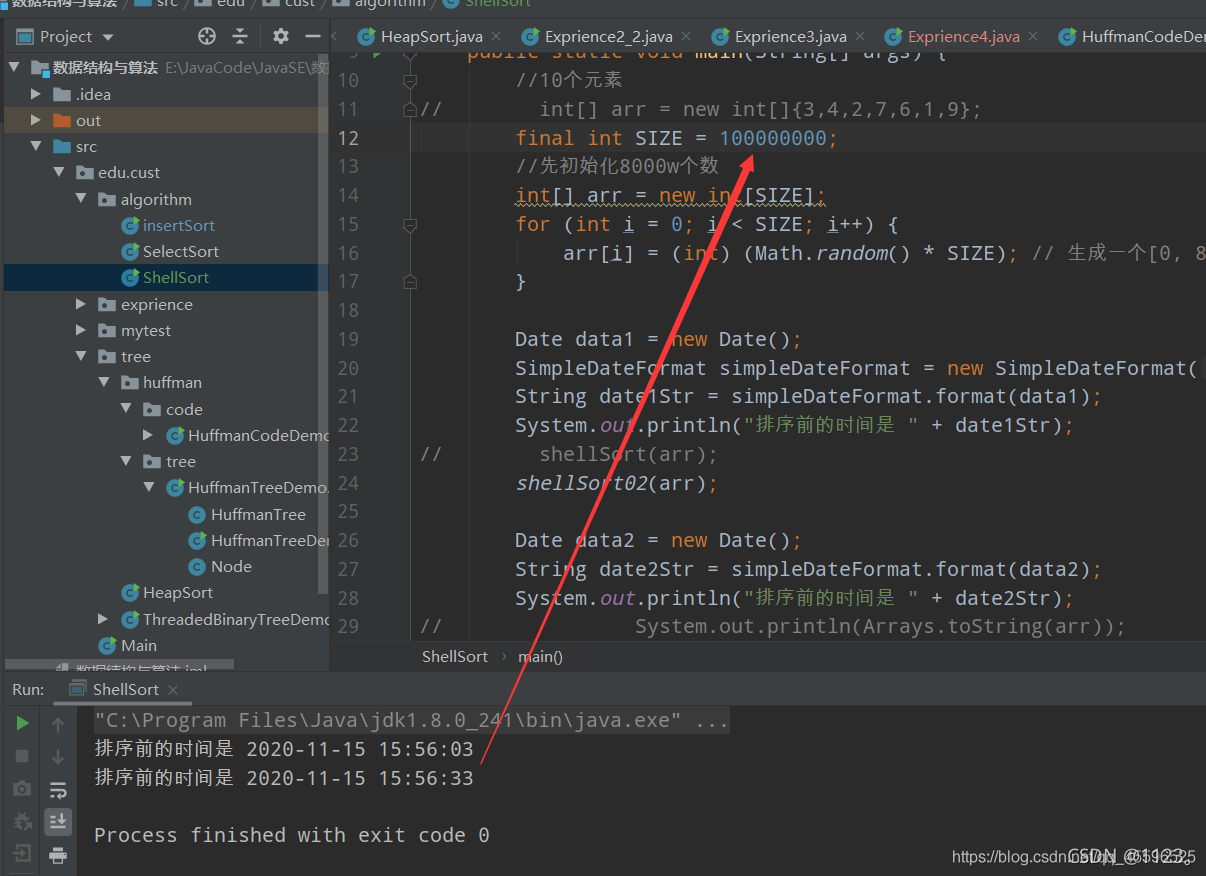
最激动人心的是 , 希尔排序(移位法)的效率奇高, 在本地调试中,一亿 个随机数仅需30S即可排完 (不同机器可能结果不同) ,在数据量较大时效率是比堆排序要高的
结果在希尔排序移位法的第3点中 , 可以直接跳转查看
下面将介绍这几种排序方式及其同异点
提示:以下是本篇文章正文内容,下面案例可供参考
一、直接插入排序
1. 图解插排
思路 : 字面意义,插入是将某一元素按某种规则放入到特定集合中 ,因此我们需要将序列划分成为两块 ,一部分为有序集合, 另一部分为待排序集合
图解 :

为了方便理解,我们就按最最最特殊的4321序列来举例,
根据上述的思路 ,我们需要将序列划分为两部分, 为了编码方便,我们将第一个元素假设为有序集合, 那么我们的循环应当是从第2个元素开始的,也就是3
为避免后面操作把3覆盖掉了 , 我们选择一个临时变量来保存3.也就是上文的 val=arr[1] ,
由于是对数组继进行操作 , 我们同时也需要获取有序集合的最后一个元素的索引作为游标
当游标不越界 , 且待插入的值小于游标指示位置时(上图的4<3) , 我们将元素4后移 , 游标前移,继续检查集合中的其它元素是否也小于待插入的元素, 直到游标越界
上图由于集合内只有一个4, 游标前移越界了, 因此循环终止. 下一轮比较开始执行
2. 代码实现
public static void insertSort(int[]arr){
for(int i = 1 ; i < arr.length; i++){
int val = arr[i];
int valIndex = i - 1; //游标
while(valIndex >= 0 && val < arr[valIndex]){ //插入的值比游标指示的值小
arr[valIndex + 1] = arr[valIndex];
valIndex--; //游标前移
}
arr[valIndex+1] = val;
}
}
1234567891011
3.性能检测与时空复杂度
实际运行80w个数据耗时1分4秒(非准确值,每台机器可能都不一样)

直接插排在排序记录较少, 关键字基本有序的情况下效率较高
时间复杂度 :
关键字比较次数 : KCN=(n^2)/2 总移动次数 : RMN= (n^2)/2
因此时间复杂度约为 O(N^2)
二、希尔排序(交换法)
1. 思路图解

2. 代码实现
public static void shellSort(int[] arr){ //交换法
int tmp = 0;
for(int gap = arr.length / 2 ; gap > 0 ; gap /= 2){
for(int i = gap ; i < arr.length ; i++){ //先遍历所有数组
for(int j = i - gap ; j >= 0 ; j -= gap){//开启插入排序
if(arr[ j ] > arr[ gap + j ]){ //可以根据升降序修改大于或小于
tmp = arr[gap + j];
arr[j+gap] = arr[j];
arr[j] = tmp;
}
}
}
System.out.println(gap);
System.out.println(Arrays.toString(arr));
}
}
12345678910111213141516
这里最难理解的应该是第三个for循环,j = i - gap, 表示小组内的第一个元素,即j=0,
当小组内的第一个元素大于第二个元素时(由于是逻辑上的分类,第二个元素的索引应当是第一个元素的所有值+增量gap) , 交换两者,反之j-=gap,继续比较或跳出循环 ,
如此往复将所有小组都遍历完之后 , 缩小增量(即gap/=2) , 然后继续上述步骤, 直到增量gap为1时, 序列排序结束
3. 时间复杂度
希尔排序的时间复杂度取决于增量序列的函数 , 需要具体问题具体分析,并不是一个确定的值,这也是第四点需要讨论的问题
4. 关于增量的选择
上述我们在做排序的时候增量缩减选用的时gap/=2的模型, 这并不是最优的选择 , 关于增量的选取 , 属于数学界尚未解决的一个问题
但是可以确定的是, 通过大量的实验证明 ,当n->无穷大时, 时间复杂度可以减少到 :

在下一点, 移位法中 , 我们也做了几个实验 , 可以肯定的时,对于一定规模内(如800w~1亿) 的计算, 希尔排序的速度远远超过了堆排序, 至少在笔者的电脑上是这样的
三、希尔排序(移位法)
交换法的速度比移位法慢很多 ,因此更多的是使用地移位法,并且移位法相较于交换法, 更"像"插入排序
1. 思路
思路其实就是上述两种排序的结合 , 将分组 与 插入的优点结合到一起, 效率非常高
体现的就是分治的思路,将一个较大序列切割成若干较小序列

2. 代码实现
public static void shellSort02(int[] arr){ //移位法
for(int gap = arr.length/2 ; gap > 0 ; gap /= 2){ //分组
for(int i = gap ; i < arr.length ; i++){ //遍历
int valIndex = i;
int val = arr[valIndex];
if(val < arr[valIndex-gap]){ //插入的值小于组内另一个值
while(valIndex - gap >=0 && val < arr[valIndex-gap]){ //开始插排
// 插入
arr[valIndex] = arr[valIndex-gap];
valIndex -= gap; //让valIndex = valIndex-gap (游标前移)
}
}
arr[valIndex] = val;
}
}
}
12345678910111213141516
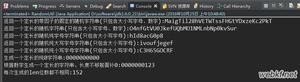
3. 实验结果


总结
到此这篇关于Java算法实战之排一亿个随机数的文章就介绍到这了,更多相关Java一亿个随机数内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Java算法实战之排一亿个随机数 的全部内容, 来源链接: utcz.com/p/250885.html