SpringDataJpa多表操作的实现
数据库中的表存在着多种关系,一对一,一对多,多对多
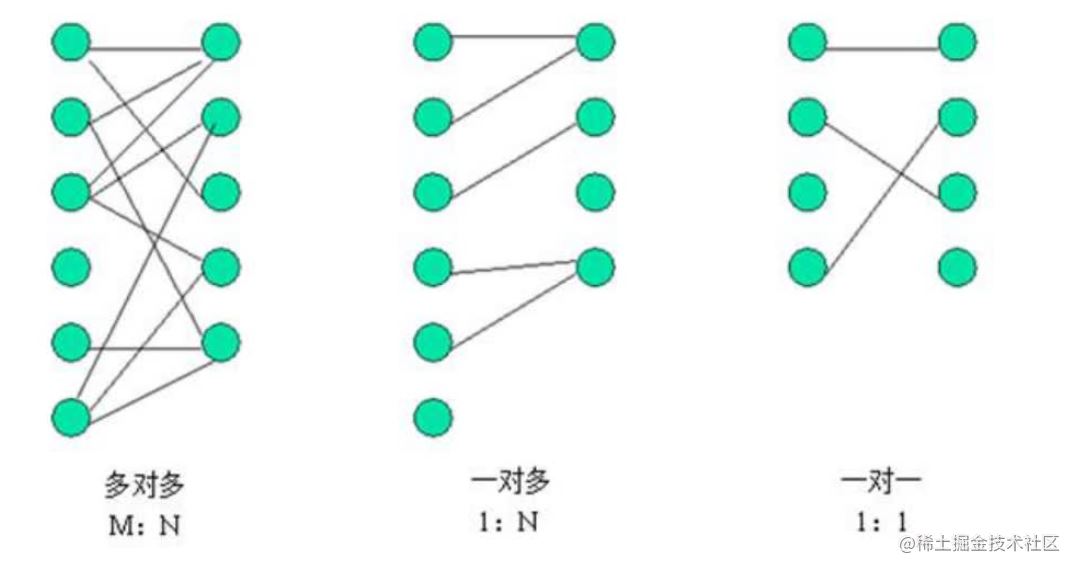
Jpa表关系分析步骤
开发过程中会有很多多表的操作,他们之间有着各种关系,在Jpa这种实现来了orm思想的框架中我们可以通过操作实体类来操作数据库,我们来连接下jap如何配置实体类来实现这种功能
- 确定表之间的关系
- 在数据库实现两个表的关系
- 在实体类种描述两个表的关系
- 配置数据库和实体类的关系映射
关联关系的注解
@OneToOne、@JoinColumn、@ManyToOne、@ManyToMany、@JoinTable、@OrderBy
@JoinColumn定义外键关联的字段名称
@Repeatable(JoinColumns.class)
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface JoinColumn {
//目标表的字段名,必填
String name() default "";
//本实体的字段名,非必填,默认是本表ID
String referencedColumnName() default "";
//外键字段是否唯一
boolean unique() default false;
//外键字段是否允许为空
boolean nullable() default true;
//是否跟随一起新增
boolean insertable() default true;
//是否跟随一起更新
boolean updatable() default true;
String columnDefinition() default "";
String table() default "";
ForeignKey foreignKey() default @ForeignKey(ConstraintMode.PROVIDER_DEFAULT);
}
用法:@JoinColumn主要配合@OneToOne、@ManyToOne、@OneToMany一起使用,单独使用没有意义。@JoinColumn定义多个字段的关联关系。
@OneToOne一对一关联关系
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface OneToOne {
//关系目标实体,非必填,默认该字段的类型。
Class targetEntity() default void.class;
//cascade级联操作策略
/*1.CascadeType.PERSIST级联新建
2.CascadeType.REMOVE级联删除
3.CascadeType.REFRESH级联刷新
4.CascadeType.MERGE级联更新
5.CascadeType.ALL四项全选
6.默认,关系表不会产生任何影响*/
CascadeType[] cascade() default {};
//数据获取方式EAGER(立即加载)/LAZY(延迟加载)
FetchType fetch() default FetchType.EAGER;
h()defaultEAGER;//是否允许为空
boolean optional() default true;
//关联关系被谁维护的。非必填,一般不需要特别指定。//注意:只有关系维护方才能操作两者的关系。被维护方即使设置了维护方属性进行存储也不会更新外键关联。1)mappedBy不能与@JoinColumn或者@JoinTable同时使用。2)mappedBy的值是指另一方的实体里面属性的字段,而不是数据库字段,也不是实体的对象的名字。既是另一方配置了@JoinColumn或者@JoinTable注解的属性的字段名称。
String mappedBy() default "";
//是否级联删除。和CascadeType.REMOVE的效果一样。两种配置了一个就会自动级联删除
boolean orphanRemoval() default false;
}
用法@OneToOne需要配合@JoinColumn一起使用。
举个例子使用@OneToOne和@JoinColumn注解
分析 一个学生对应一个班级,添加一个学生时同时添加班级
学生类
@Data
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String studentName;
@OneToOne(cascade = CascadeType.PERSIST)
@JoinColumn(name = "grade_id")
private Grade grade;
}
班级类
@Data
@Entity
public class Grade {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String gradeName;
/* @OneToOne(mappedBy = "grade")
private Student student;*/
}
接口
public interface StudentRepository extends JpaRepository<Student,Integer> {
}
测试类
@Test
public void test1(){
Grade grade = new Grade();
grade.setGradeName("一年级");
Student student = new Student();
student.setStudentName("张三");
student.setGrade(grade);
studentRepository.save(student);
}
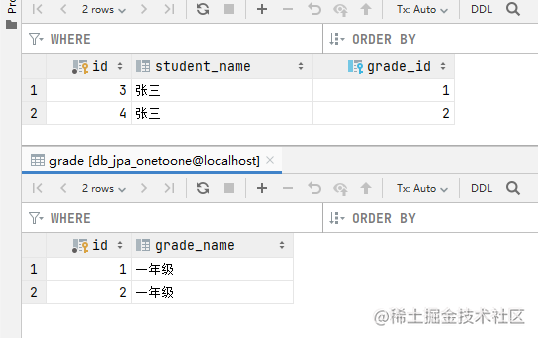
测试结果
这两个数据我用的一个是配置了一方关联,只在Student类里配置了班级信息,还有一条是配置了双向关联,Grade类里边被注释掉的部分,具体使用哪个,根据具体的业务需求
@OneToMany一对多& @ManyToOne多对一
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface OneToMany {
Class targetEntity() default void.class;
//cascade级联操作策略:(CascadeType.PERSIST、CascadeType.REMOVE、CascadeType.REFRESH、CascadeType.MERGE、CascadeType.ALL)
CascadeType[] cascade() default {};
//数据获取方式EAGER(立即加载)/LAZY(延迟加载)
FetchType fetch() default FetchType.LAZY;
//关系被谁维护,单项的。注意:只有关系维护方才能操作两者的关系。
String mappedBy() default "";
//是否级联删除。和CascadeType.REMOVE的效果一样。两种配置了一个就会自动级联删除
boolean orphanRemoval() default false;
}
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface ManyToOne {
Class targetEntity() default void.class;
CascadeType[] cascade() default {};
FetchType fetch() default FetchType.EAGER;
boolean optional() default true;
}
@OneToMany一对多& @ManyToOne多对一的源码,FetchType一个是FetchType.LAZY;一个是 FetchType.EAGER;
实体类
现在实现一对多的例子,一个班有多个学生,新增班级时新增多个学生
@Entity
@Data
public class Grade {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String gradeName;
@OneToMany(mappedBy = "grades",cascade = CascadeType.ALL)
private List<Student> students;
}
@Entity
@Data
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String studentName;
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name="grades_id")
private Grade grades;
}
接口
public interface GradeRepository extends JpaRepository<Grade , Integer> {
}
测试类
@Test
public void test1(){
Grade grade = new Grade();
grade.setGradeName("一年级一班");
ArrayList<Student> students = new ArrayList<>();
Student student = new Student();
student.setStudentName("张三");
student.setGrades(grade);
Student student1 = new Student();
student1.setStudentName("李四");
student1.setGrades(grade);
students.add(student);
students.add(student1);
grade.setStudents(students);
gradeRepository.save(grade);
}
结果

@OrderBy关联查询的时候的排序
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface OrderBy {
/***要排序的字段,格式如下:
orderby_list::=orderby_item[,orderby_item]
orderby_item::=[property_or_field_name][ASC|DESC]
字段可以是实体属性,也可以数据字段,默认ASC。*/
String value() default "";
}
@OneToMany(mappedBy = "grades",cascade = CascadeType.ALL)
@OrderBy("studentName DESC ")
private List<Student> students;
@JoinTable关联关系表
@ManyToMany多对多
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface ManyToMany {
Class targetEntity() default void.class;
CascadeType[] cascade() default {};
FetchType fetch() default FetchType.LAZY;
String mappedBy() default "";
}
@ManyToMany表示多对多,和@OneToOne、@ManyToOne一样也有单向双向之分,单项双向和注解没有关系,只看实体类之间是否相互引用。主要注意的是当用到@ManyToMany的时候一定是三张表。
a案例
一个年级有多个老师,一个老师管多个年级
实体类
@Entity
@Data
public class Grade {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer gradeid;
private String gradeName;
//配置年级和老师之间的多对多关系
//1.声明多对多的关系@ManyToMany(targetEntity = Teacher.class)
//2.配置中间表
/* @JoinTable(name = "grade_teacher", 中间表表名
joinColumns = @JoinColumn(name = "grade_id" 外键名
,referencedColumnName = "gradeid"参照的主表的主键名
),
中间表字段名,在当前表的外键
inverseJoinColumns = @JoinColumn(name = "tecacher_id",referencedColumnName = "teacherid"))
*/
@ManyToMany(targetEntity = Teacher.class,cascade = CascadeType.ALL)//对方的实体字节码
//中间表名,
@JoinTable(name = "grade_teacher",
//外键名,
joinColumns = @JoinColumn(name = "grade_id",referencedColumnName = "gradeid"),
inverseJoinColumns = @JoinColumn(name = "tecacher_id",referencedColumnName = "teacherid"))
private List<Teacher> teachers;
}
@Data
@Entity
public class Teacher {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer teacherid;
private String teacherName;
@ManyToMany(mappedBy = "teachers")
private List<Grade> grades;
}
接口
public interface GradeRepository extends JpaRepository<Grade , Integer> {
}
测试类
@Test
@Transactional
@Commit()
public void test2(){
//配置两个年级
Grade grade = new Grade();
grade.setGradeName("一年级");
Grade grade2 = new Grade();
grade2.setGradeName("二年级");
//创建3个老师
Teacher teacher = new Teacher();
teacher.setTeacherName("张老师");
Teacher teacher2 = new Teacher();
teacher2.setTeacherName("王老师");
Teacher teacher3 = new Teacher();
teacher3.setTeacherName("李老师");
//给一年级赛3个老师
ArrayList<Teacher> teachers = new ArrayList<>();
teachers.add(teacher);
teachers.add(teacher2);
teachers.add(teacher3);
grade.setTeachers(teachers);
//给2年级赛2个老师
ArrayList<Teacher> teachers1 = new ArrayList<>();
teachers1.add(teacher2);
teachers1.add(teacher3);
grade2.setTeachers(teachers1);
gradeRepository.save(grade);
gradeRepository.save(grade2);
}
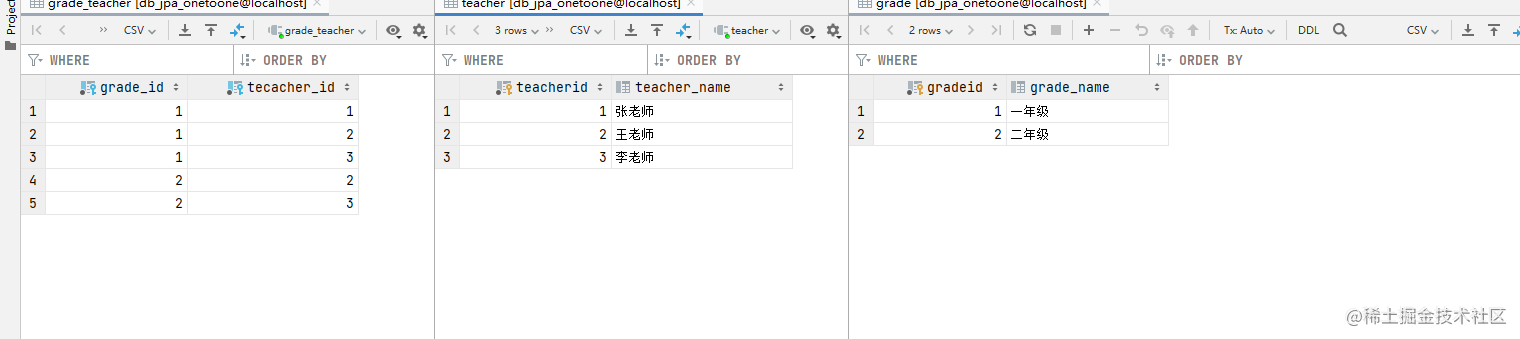
测试结果
到此这篇关于SpringDataJpa多表操作的实现的文章就介绍到这了,更多相关SpringDataJpa多表操作内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 SpringDataJpa多表操作的实现 的全部内容, 来源链接: utcz.com/p/250702.html