SpringBoot集成Sharding Jdbc使用复合分片的实践
最近主要的工作重心是数据库的容量规划。
随着业务的逐渐增大,原有保存在单表的数据量也日益增强。数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大。再加上物理服务器的资源有限(CPU、磁盘、内存、IO 等)。最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。换句话说需要合理的数据库架构来存放不断增长的数据,这个就是分库分表的设计初衷。目的就是为了缓解数据库的压力,大限度提高数据操作的效率。
数据库分库分表中间件是采用的 apache sharding。
1、Sharing JDBC 简介
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
ShardingSphere已经在2020年4月16日从Apache孵化器毕业,成为Apache顶级项目。
2、系统改造
因为我们公司属于第三方支付平台,这个改造的点可以分为两类:提供给商户调用的对接系统(比如收银台),系统内部调用的系统(支付引擎)。
- 收银台系统:核心功能是提供给商户提交交易订单,并且对这笔交易订单进行支付的支付订单
- 支付引擎:接收这个支付产品的请求,调用渠道,记账,结算等功能
数据源使用分库分表,在 Sharding JDBC 当中如果进行 修改、删除、查询操作中没有包含分片键就会进行全表扫描。所以在进行业务改造的时候对原有的数据库操作都进行了业务优化,基本改造后的所有的操作都使用了基于分片键进行操作(定时任务除外)。
2.1 对接外部系统的系统
首先讨论一下,提供给商户调用的系统。在进行下单操作的时候,商户必须传递商户号和外部订单号。对于外部订单号第三方支付系统无法控制,只需要商户每次传递过来的时候与历史的外部订单号不重复就可以了。所以这里就涉及到一张映射表,这个表的主要功能如下:
- 把商户的外部订单号映射成内部订单号
- 通过商户号与商户的外部订单号在数据库联合唯一达到幂等处理
- 保存商户请求的原始数据,做为请求凭证
这个时候对交易订单就依赖于外部映射表,把请求映射成内部订单号进行分片就可以了
2.2 内部系统间的调用
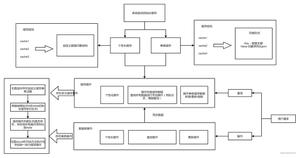
当商户下好了交易订单的时候,需要进行支付这个时候就产生了一笔支付订单。交易订单和支付订单是一对多的关系。当用户进行支付的时候会调用支付引擎,这个时候正常情况下一般会生成支付系统的支付订单。然后支付引擎会调用后续的渠道、结算、记账等系统,系统之间的调用图如下:
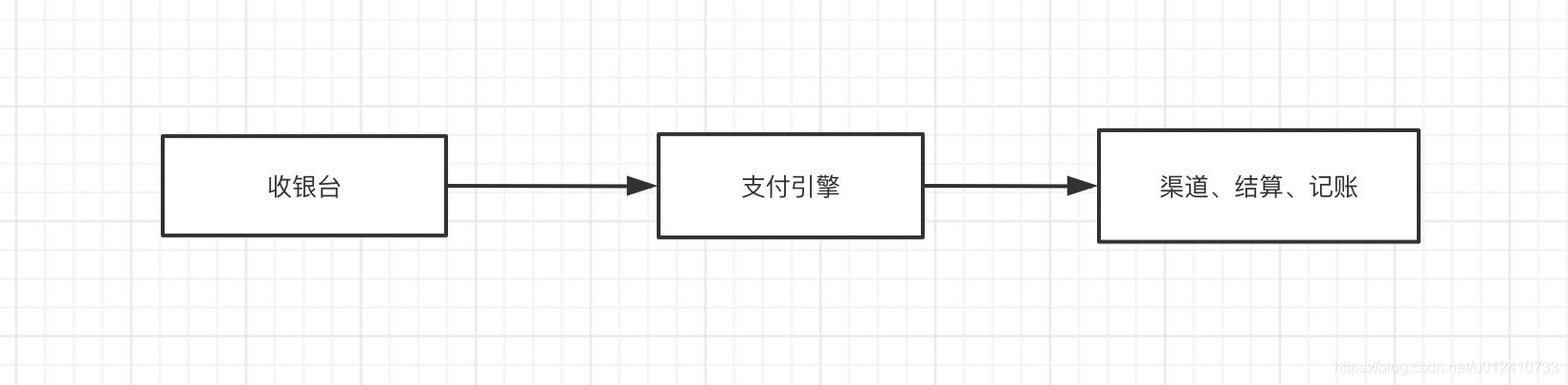
如果以支付系统的支付订单的订单号做为分片键时:
- 支付引擎的内部系统可以使用分片键查询,会路由到具体的库表当中,没有问题
- 渠道、结算、记账等系统如果涉及到回调支付引擎,在调用的时候会把支付引擎的支付单号传递给后续系统,如果进行回调操作时候,可以回传这个支付单号。会路由到具体的库表当中,没有问题
- 收银台需要根据交易的支付订单查询支付引擎生成的支付单。由于不是根据分片键查询,不能路由到具体的库中的具体表上,会进行全表扫描。就会有问题。
3、解决方案
首先想到的方案可以参考收银台系统,把收银台调用支付引擎看到外部调用。然后添加一张映射表,把收银台生成的支付流水号与支付引擎的支付单号关联起来。当收银台需要查询支付引擎时,可以先通过映射表查询到具体的支付单号,这样就可以进行分片键操作数据源了。这个方案存在一个问题存在以下几个问题:
引入了关联表,添加了系统复杂度进行数据查询的时候会两次查询,先查询映射表,然后再查询支付单
那么有没有其它方案呢?答案是肯定的。
我们来看一下收银台、支付引擎其实这两个系统在支付系统中是同一个纬度的。如果收银台的交易订单进行支付的时候,就会在支付引擎当中下一笔支付单。我们可以把交易单与支付单在同一个水平纬度上进行数据库拆分。
什么叫同一个纬度的数据库拆分呢?
其实就是收银台的支付订单进行分库分表之后,这条数据落在数据库里面的哪一个库,哪一张表就一定了。这个时候支付引擎就可以通过这个单号获取到具体的库表信息。这样就可以把支付引擎生成的的订单号带个具体的库表信息。然后在进行分库分表算法定义的时候根据支付引擎生成的订单号中带的库表信息路由到具体的库表中去了。就样就会解决上面的问题,不需要映射表。同时这种方案也会带来以下的问题:
- 数据上游与下游的分库分表必须一致
- 数据在进行再次扩容会有其它问题
经过讨论决定使用方案二。
4、代码实现
下面通过 Sharding jdbc 的复合分片简单的模拟代码实现。数据库、表准备:
数据库:
- order_0
- order_1
每个数据库的表:
tb_order_0
tb_order_1
tb_order_2
tb_order_3
tb_order_4
tb_order_5
tb_order_6
tb_order_7
# 逻辑表
create table tb_order
(
trade_master_no varchar(16),
pay_order_no varchar(16) ,
);
# 准备数据
# 分库分表规则是前一位代表库,后一位代表表,所以在 order_1.tb_order_1 中添加以下数据
insert into tb_order_1 values('11', '11'),
4.1 Sharding JDBC 配置
下面是针对订单表的 sharding jdbc 的分库分表配置,数据库连接池使用 Hikari 。分片规则:前一位代表库,后一位代表表。使用交易主单号(trade_master_no) 和 支付单号(pay_order_no) 作为复合分片。当查询条件中只要包含一个查询规则时就会路由到具体库表中。
ComplexShardingJDBCConfig.java
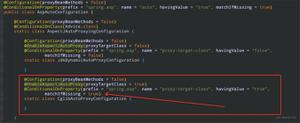
@Configuration
public class ComplexShardingJDBCConfig {
@Bean
public DataSource getShardingDataSource(HikariCommonConfig commonConfig) throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getShardingMessageTableRuleConfiguration());
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("order_0", createDataSource(datasourceOne(commonConfig)));
dataSourceMap.put("order_1", createDataSource(datasourceTwo(commonConfig)));
Properties properties = new Properties();
properties.setProperty(ShardingPropertiesConstant.SQL_SHOW.getKey(), "true");
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, properties);
}
private TableRuleConfiguration getShardingMessageTableRuleConfiguration() {
TableRuleConfiguration shardingMessageConfiguration = new TableRuleConfiguration("tb_order", "order_${0..1}.tb_order_${0..7}");
shardingMessageConfiguration.setDatabaseShardingStrategyConfig(messageDatasourceShardingStrategyConfig());
shardingMessageConfiguration.setTableShardingStrategyConfig(messageTableShardingStrategyConfig());
return shardingMessageConfiguration;
}
private ComplexShardingStrategyConfiguration messageDatasourceShardingStrategyConfig(){
return new ComplexShardingStrategyConfiguration("trade_master_no,pay_order_no", new OrderDatasourceComplexKeysShardingAlgorithm());
}
private ShardingStrategyConfiguration messageTableShardingStrategyConfig() {
return new ComplexShardingStrategyConfiguration("trade_master_no,pay_order_no", new OrderTableComplexKeysShardingAlgorithm());
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.ds1")
public HikariConfig datasourceOne(HikariCommonConfig commonConfig){
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setMinimumIdle(commonConfig.getMinimumIdle());
hikariConfig.setIdleTimeout(commonConfig.getIdleTimeout());
hikariConfig.setMaximumPoolSize(commonConfig.getMaximumPoolSize());
hikariConfig.setPoolName(commonConfig.getPoolName());
hikariConfig.setMaxLifetime(commonConfig.getMaxLifetime());
hikariConfig.setConnectionTimeout(commonConfig.getConnectionTimeout());
hikariConfig.setConnectionTestQuery(commonConfig.getConnectionTestQuery());
return hikariConfig;
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.ds2")
public HikariConfig datasourceTwo(HikariCommonConfig commonConfig){
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setMinimumIdle(commonConfig.getMinimumIdle());
hikariConfig.setIdleTimeout(commonConfig.getIdleTimeout());
hikariConfig.setMaximumPoolSize(commonConfig.getMaximumPoolSize());
hikariConfig.setPoolName(commonConfig.getPoolName());
hikariConfig.setMaxLifetime(commonConfig.getMaxLifetime());
hikariConfig.setConnectionTimeout(commonConfig.getConnectionTimeout());
hikariConfig.setConnectionTestQuery(commonConfig.getConnectionTestQuery());
return hikariConfig;
}
private HikariDataSource createDataSource(HikariConfig hikariConfig) {
HikariDataSource sharding = new HikariDataSource();
BeanUtils.copyProperties(hikariConfig, sharding);
return sharding;
}
}
数据库分片规则:
public class OrderDatasourceComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> shardingValue) {
Map<String, Collection<String>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
if(columnNameAndShardingValuesMap.containsKey("trade_master_no")){
Collection<String> tradeMasterNos = columnNameAndShardingValuesMap.get("trade_master_no");
String tradeMasterNo = tradeMasterNos.iterator().next();
String datasourceSuffix = tradeMasterNo.substring(0, 1);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
if(columnNameAndShardingValuesMap.containsKey("pay_order_no")){
Collection<String> payOrderNos = columnNameAndShardingValuesMap.get("pay_order_no");
String payOrderNo = payOrderNos.iterator().next();
String datasourceSuffix = payOrderNo.substring(0, 1);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
throw new UnsupportedOperationException();
}
}
数据库中的表分片规则:
public class OrderTableComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> shardingValue) {
Map<String, Collection<String>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
if(columnNameAndShardingValuesMap.containsKey("trade_master_no")){
Collection<String> tradeMasterNos = columnNameAndShardingValuesMap.get("trade_master_no");
String tradeMasterNo = tradeMasterNos.iterator().next();
String datasourceSuffix = tradeMasterNo.substring(1, 2);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
if(columnNameAndShardingValuesMap.containsKey("pay_order_no")){
Collection<String> payOrderNos = columnNameAndShardingValuesMap.get("pay_order_no");
String payOrderNo = payOrderNos.iterator().next();
String datasourceSuffix = payOrderNo.substring(1, 2);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
throw new UnsupportedOperationException();
}
}
4.2 数据源操作类
这里使用 Mybatis 操作数据源,当然使用其它 ORM 框架操作数据源 sharding jdbc 也是支持的。
public interface OrderMapper {
int countByExample(OrderExample example);
int deleteByExample(OrderExample example);
int insert(Order record);
int insertSelective(Order record);
List<Order> selectByExample(OrderExample example);
int updateByExampleSelective(@Param("record") Order record, @Param("example") OrderExample example);
int updateByExample(@Param("record") Order record, @Param("example") OrderExample example);
}
4.3 分片测试类
通过 Spring boot 定义一个 Controller,使用 Order 对象查询。即可以使用交易单号也可以使用支付单号查询。
@Getter
@Setter
public class Order {
private String tradeMasterNo;
private String payOrderNo;
}
@RestController
@RequestMapping("order")
public class OrderController {
@Resource
private OrderDao orderDao;
@RequestMapping("query")
public Order query(@RequestBody Order order) {
Order orderInDB = orderDao.queryOrder(order);
return orderInDB;
}
}
4.4 测试结果
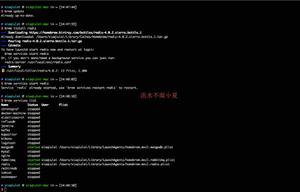
由于我们在 sharing jdbc 配置当中配置了数据库查询 SQL,我们只需要观察是不是只打印了一条数据库操作语句就可以判断之前的结论是否正确。
通过 Postman 使用交易单号查询:
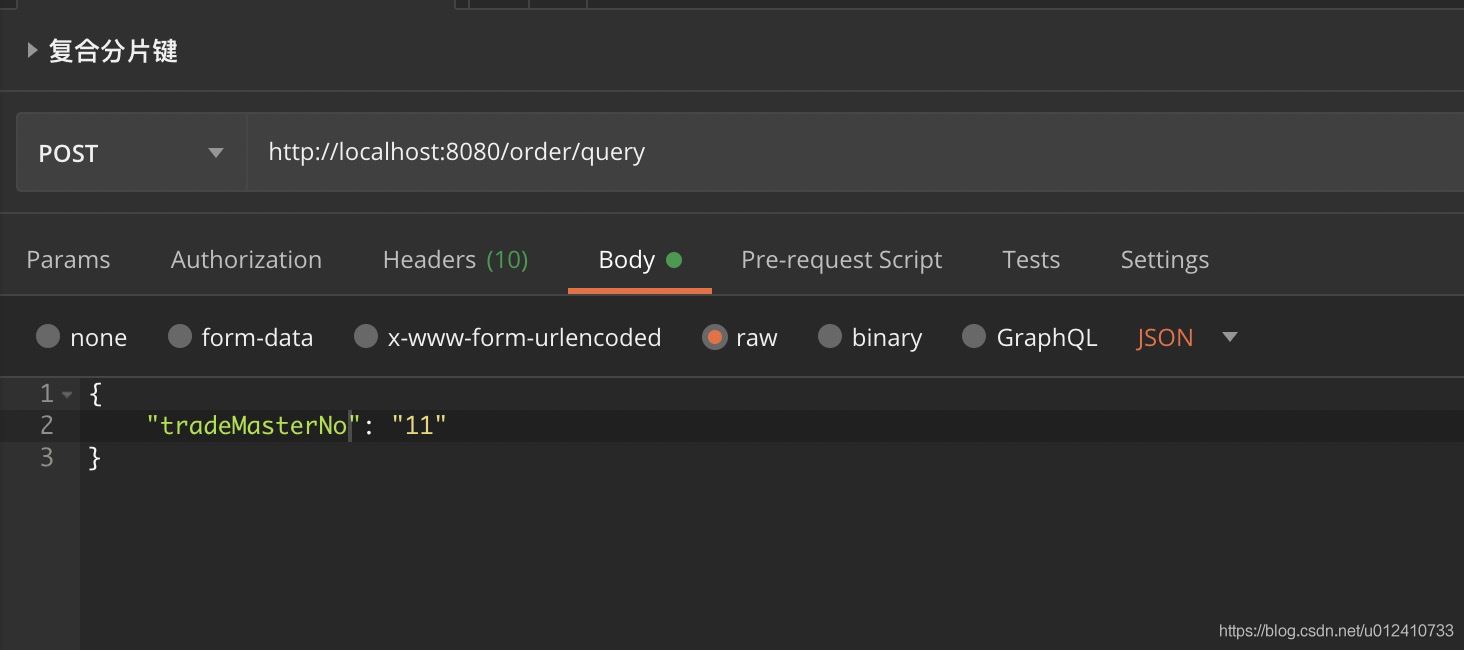
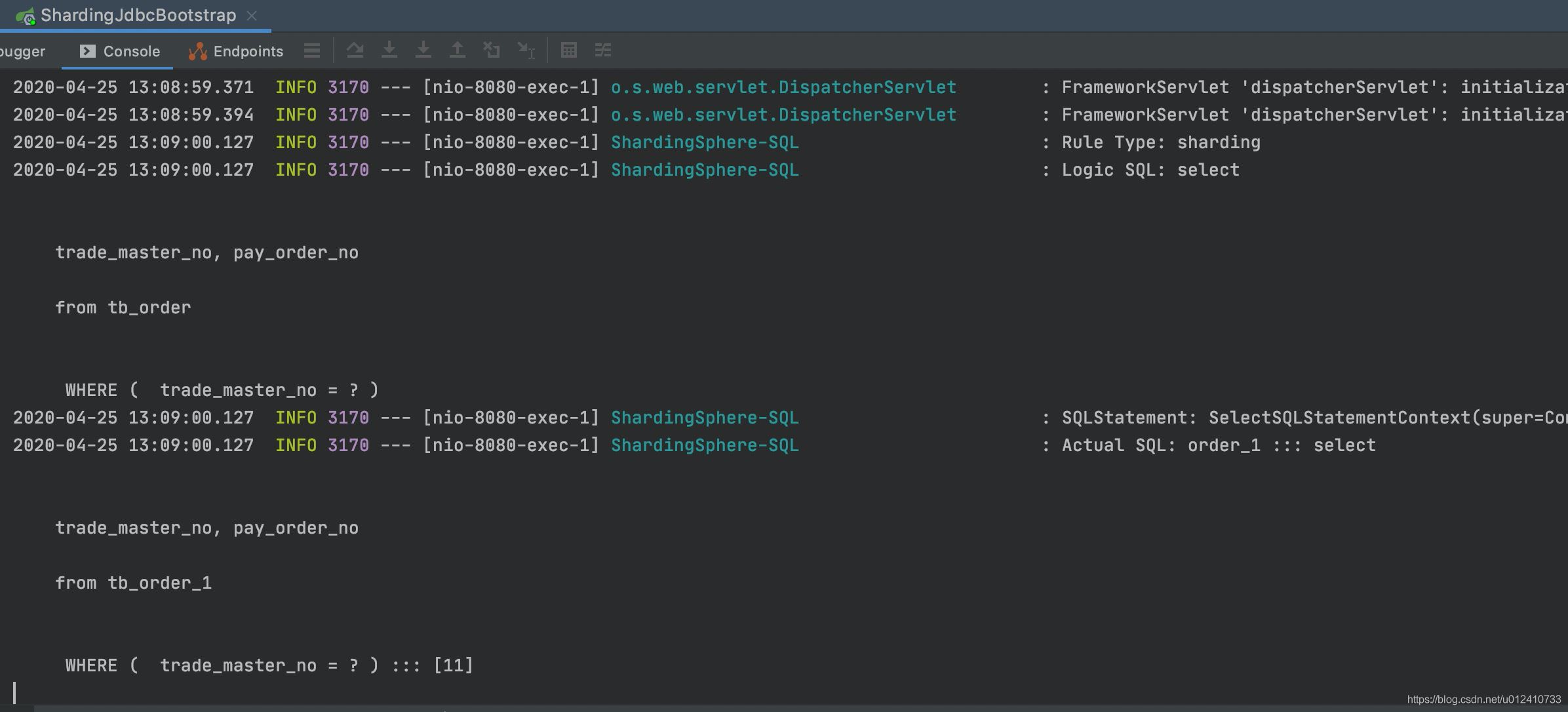
控制台打印:
然后通过 Postman 使用支付单号查询:
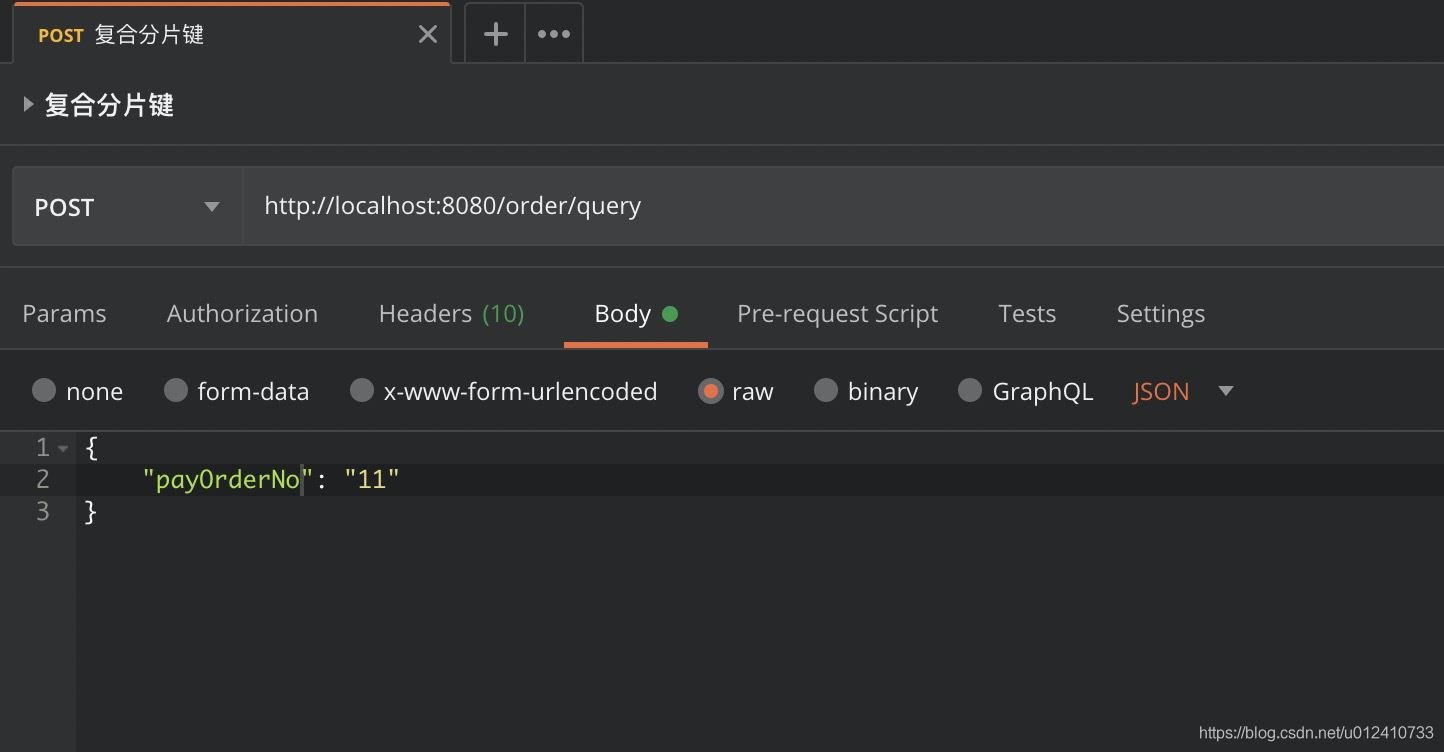
控制台打印:
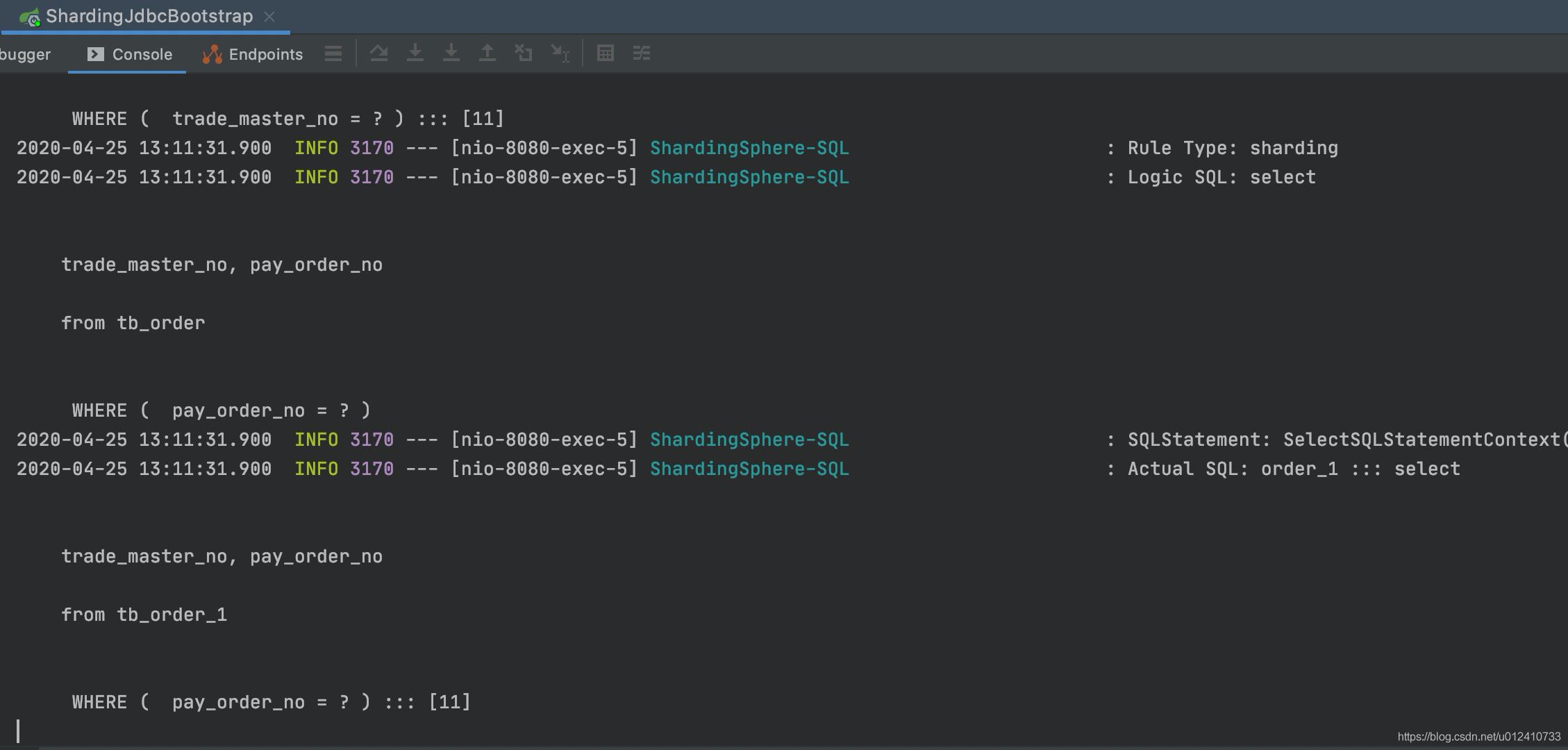
它们查询都是路由到具体的库表当中,说明我们的方案是可以的。
参考文章:
Sharding-JDBC 官网
到此这篇关于SpringBoot集成Sharding Jdbc使用复合分片的实践的文章就介绍到这了,更多相关SpringBoot集成Sharding Jdbc复合分片内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 SpringBoot集成Sharding Jdbc使用复合分片的实践 的全部内容, 来源链接: utcz.com/p/249360.html