Java中ExecutorService和ThreadPoolExecutor运行原理
为什么要使用线程池
服务器应用程序中经常出现的情况是:单个任务处理的时间很短而请求的数目却是巨大的。
构建服务器应用程序的一个过于简单的模型应该是:每当一个请求到达就创建一个新线程,然后在新线程中为请求服务。实际上,对于原型开发这种方法工作得很好,但如果试图部署以这种方式运行的服务器应用程序,那么这种方法的严重不足就很明显。
每个请求对应一个线程(thread-per-request)方法的不足之一是:为每个请求创建一个新线程的开销很大;为每个请求创建新线程的服务器在创建和销毁线程上花费的时间和消耗的系统资源要比花在处理实际的用户请求的时间和资源更多。除了创建和销毁线程的开销之外,活动的线程也消耗系统资源(线程的生命周期!)。在一个JVM 里创建太多的线程可能会导致系统由于过度消耗内存而用完内存或“切换过度”。为了防止资源不足,服务器应用程序需要一些办法来限制任何给定时刻处理的请求数目。
线程池为线程生命周期开销问题和资源不足问题提供了解决方案。通过对多个任务重用线程,线程创建的开销被分摊到了多个任务上。其好处是,因为在请求到达时线程已经存在,所以无意中也消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。而且,通过适当地调整线程池中的线程数目,也就是当请求的数目超过某个阈值时,就强制其它任何新到的请求一直等待,直到获得一个线程来处理为止,从而可以防止资源不足。
线程池的创建
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("thread-name").build();
//创建线程池
ExecutorService exc = new ThreadPoolExecutor(20, 20, 30000,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), namedThreadFactory);
/*
参数的意义
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
*/
线程的提交方法
在idea中,我们可以通过alt+7(注意不是F7)在左下角查看当前类的所有方法
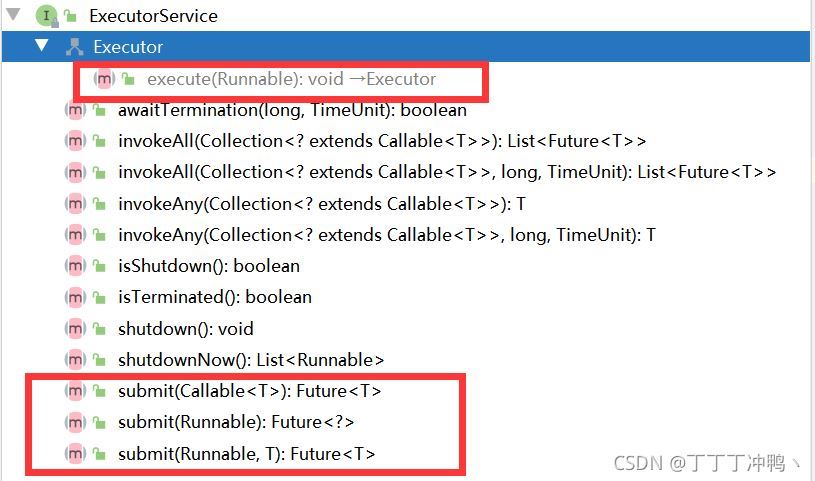
在图中我们可以看到ExecutorService有execute和submit两种方法,但是他并没有实现execute方法,所以方法是灰的
接下来我们看ExecutorService的实现类ThreadPoolExecutor
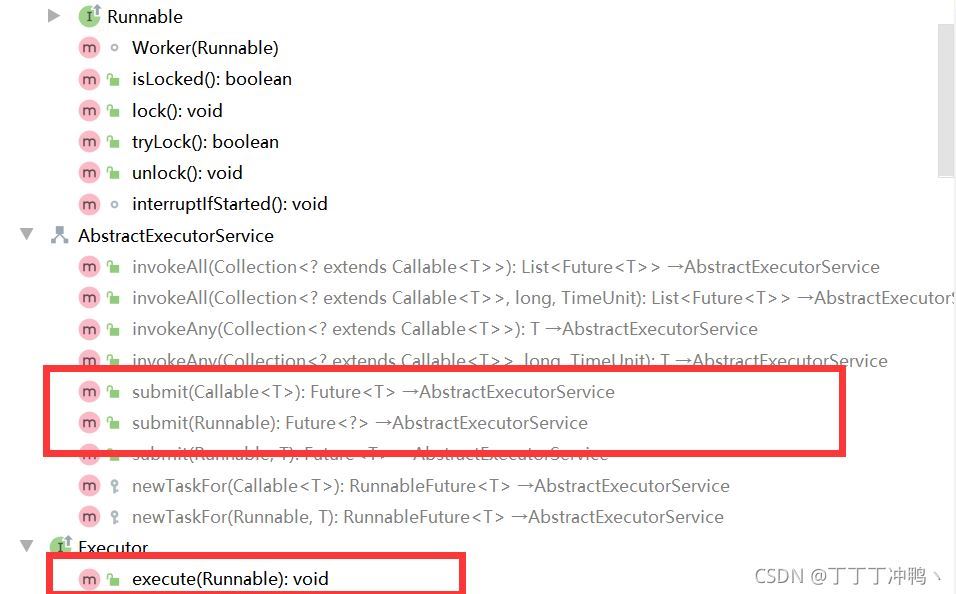
可以看到ThreadPoolExecutor 实现了execute这个方法,那接下来我们具体看execute和submit的方法
具体实现
在我第一次学习时,我就是这么简单来理解的
exc.submit() //提交有返回值 传入的为callable和runable 返回值为future
exc.execute() //提交无返回值 传入的为runable
但是我发现为什么submit可以执行callable,又执行runable?这不是两个不同的创建线程的方式吗?我点进去了ThreadPoolExecutor类,但是在其中没有找到submit方法,于是我按了alt+7
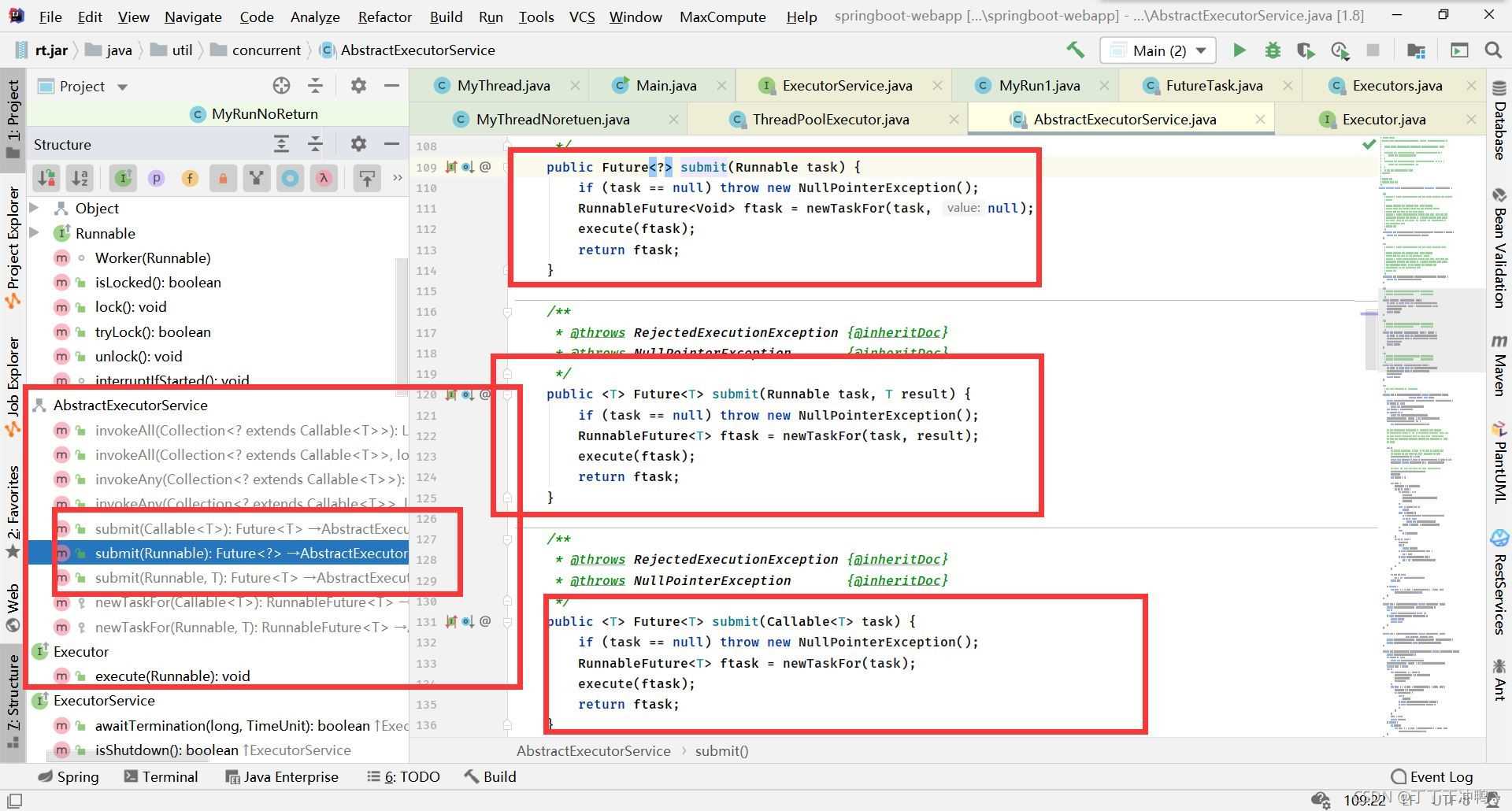
在AbstractExecutorService类中发现了submit方法
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
在代码中我们可以看到,三个方法都是用这个代码来统一实现的,
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
不同的是,当使用submit而传入的是runable接口时,会多一个返回值的参数,如果没有这个参数则会在newTaskFor中多加一个null参数,我们再进入newTaskFor方法
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
同样存在两个方法,一个是为了接收runable,一个接收callable,但是这次都是使用了new FutureTask来传入,因为FutureTask可以运行二者
我们知道Thread实现了Runable接口可以实现线程,但关于为什么FutureTask可以运行Callable接口
首先,在下面代码中可以看到FutureTask实现了RunnableFuture,RunnableFuture实现了Runnable,所以可以用过Thread来运行start
public class FutureTask<V> implements RunnableFuture<V>
public interface RunnableFuture<V> extends Runnable, Future<V>
FutureTask<Integer> futureTask = new FutureTask(callableTask);
Thread thread = new Thread(futureTask);
thread.start();
而Thread中的start又是调用的接口中的run方法,但是Callable明明没有run方法啊,这就要看FutureTask中的run方法了
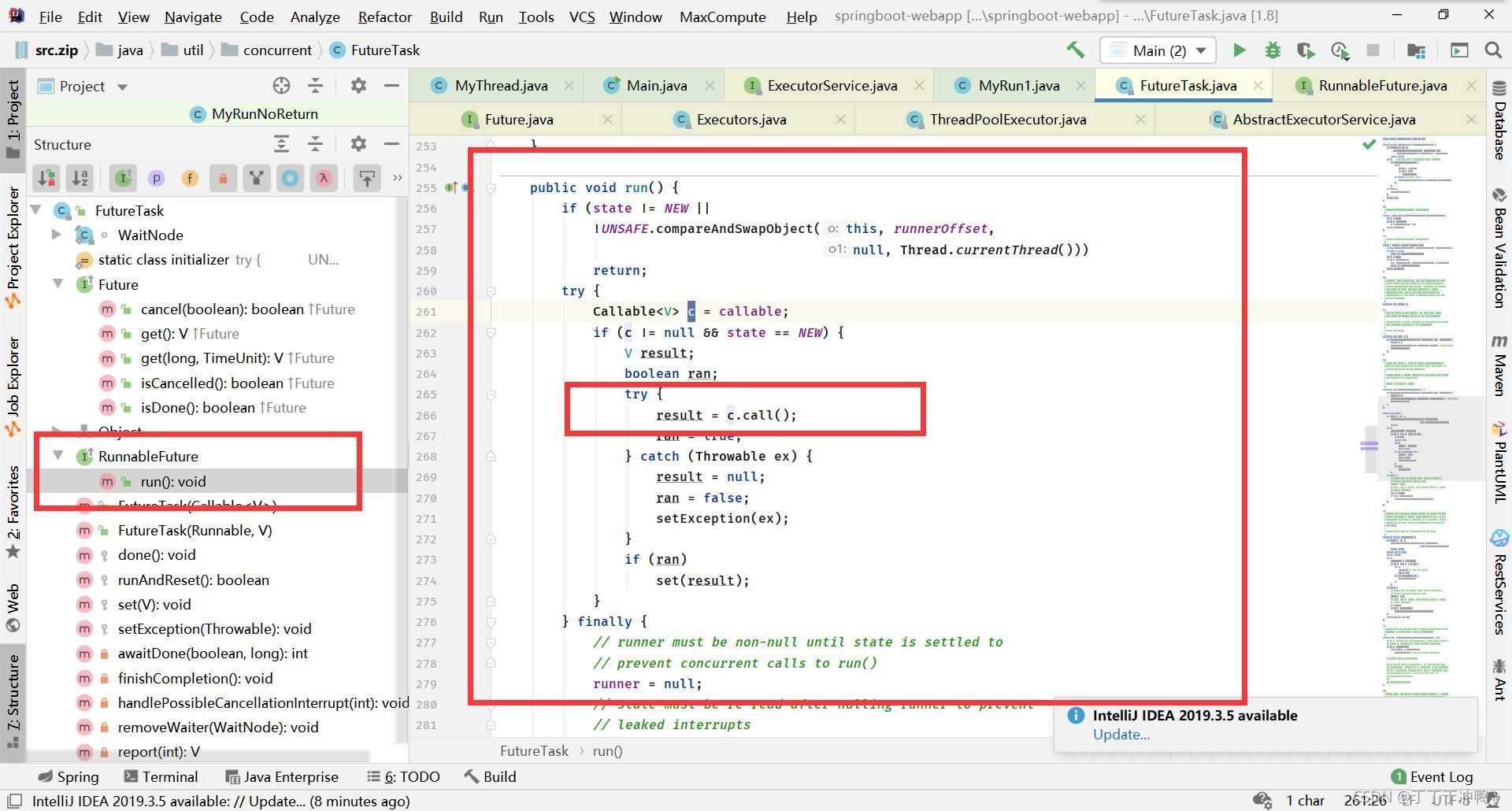
在这个FutureTask的run方法中,调用的是Callable的call方法,所以得以运行,并且将返回值另外保存了,关于异步返回值的原理下次再说。
回到new FutureTask(callable);的代码中
我们接着点进去看源码
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
对于第一个传入callable的我们已经知道了原理,就是FutureTask如何通过Thread运行Callable的。
那么对于第二个传入Runable的代码又是个什么东西?
this.callable = Executors.callable(runnable, result);
好,我们再点进去看源码,进入了一个Executors,这个类没有任何的实现与继承,真是太好了,看方法
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}
哦豁,又将Runable传入了一个RunnableAdapter类,真复杂,就要看看到底多少层,看这个名字,Adapter,适配器?大概知道里面会有什么操作了,我们再点进去看源码
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
这是Executors中的一个内部类,它实现了Callable接口,我依稀记得传入的是一个Runable接口,原来在这个类中,将Callable的call方法重写了,其中调用了Runable的run方法,并且具有返回值,还记得这个result吗,在最初的AbstractExecutorService中,对于传入Runable的submit方法有两个,有参数则传递,无参数则传入为null,
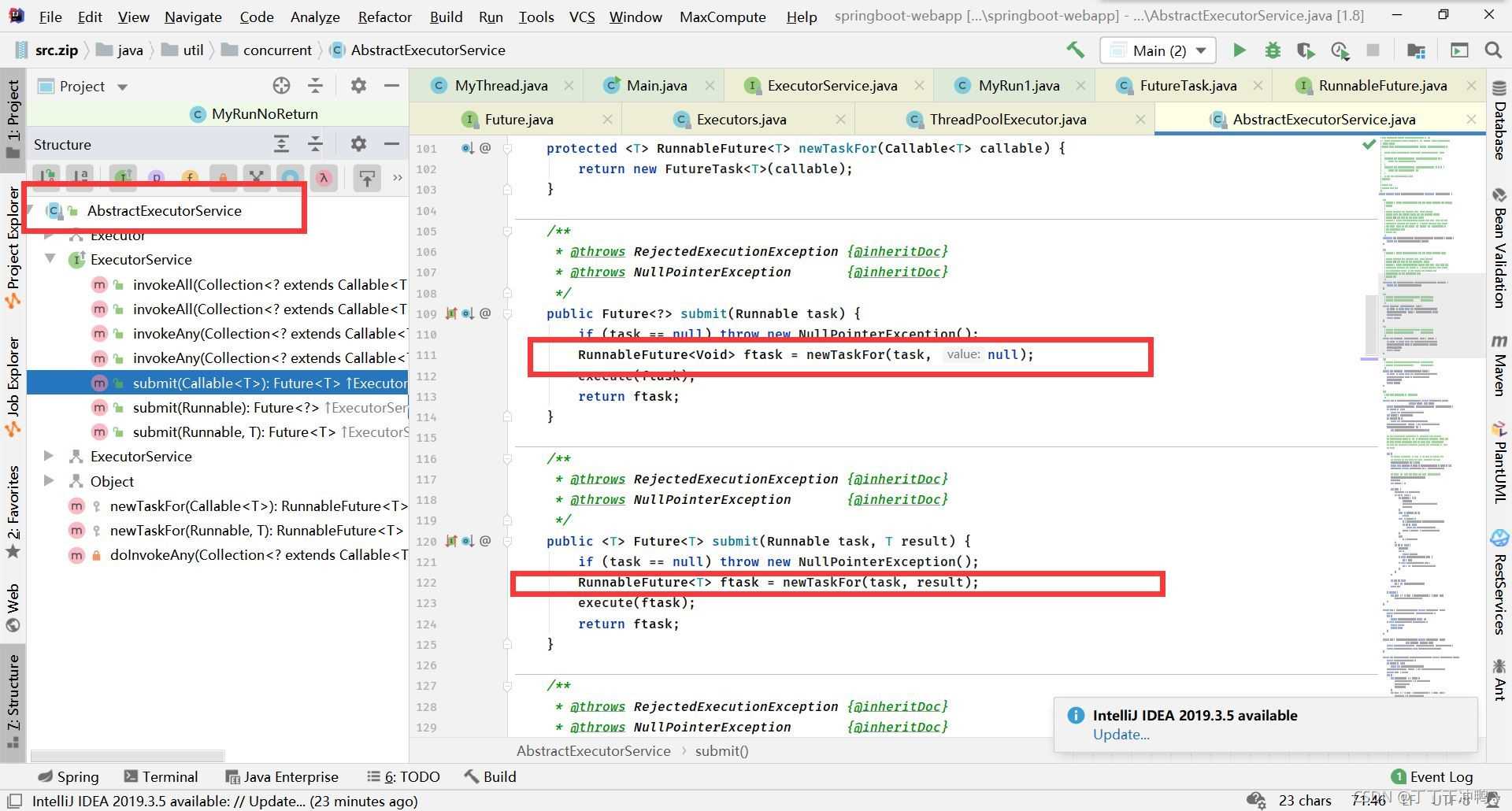
总结1
至此,就了解到了为什么submit又可以传入Runable也可以传入Callable。
接下来稍微说一下如何运行。
ThreadPoolExecutor运行原理
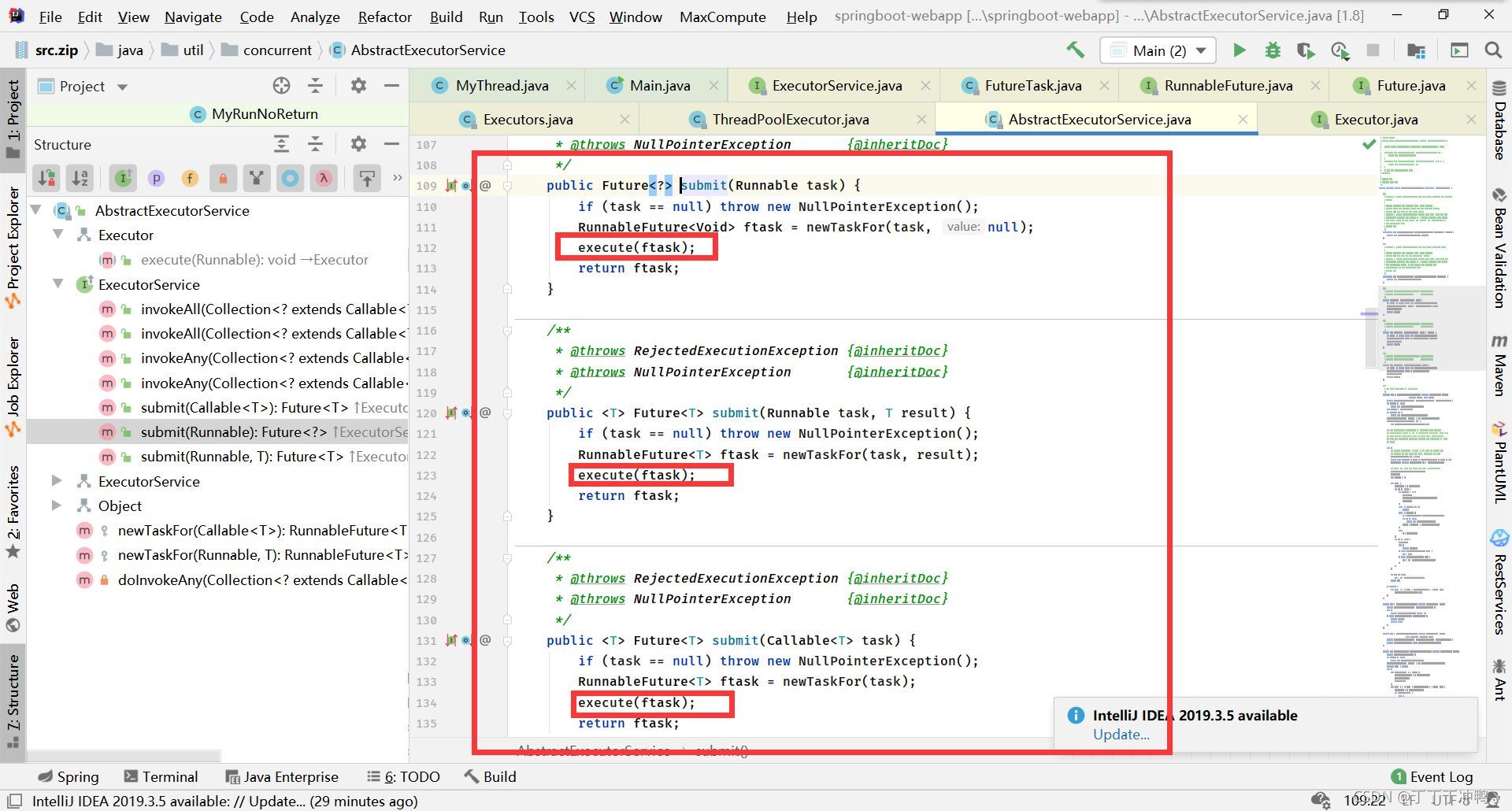
细心的小伙伴发现了,说好的submit,竟然又用execute
进入execute方法,直接用ctrl点击无效,我们打开ThreadPoolExecutor中,按alt+7,左下角execute是亮的,方法是在这里实现的
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
先是判断线程池数量,在判断传入线程状态,满足条件就使用addWorker,不满足就reject拒绝
进入addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
这里又是一堆条件验证,都是核心代码,最后通过一个内置类worker来获取线程实例,然后加锁继续验证,条件都满足时,t.start(),终于可以运行
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
---
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
---
workerAdded = true;
---
if (workerAdded) {
t.start();
---
总结2
至此,整个流程都已说明,关于Callable和Future完成异步返回值的原理,下次再说
到此这篇关于Java中ExecutorService和ThreadPoolExecutor运行原理的文章就介绍到这了,更多相关Java ExecutorService ThreadPoolExecutor内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Java中ExecutorService和ThreadPoolExecutor运行原理 的全部内容, 来源链接: utcz.com/p/248385.html