C语言基础解析之分支与循环语句
- if语句:if(表达式)
// 括号里面放一个表达式
//表达式的结果如果为非零,表达式为真
//表达式结果如果为零,表达式为假
if语句可以单支,双支,多分支,还可以用大括号括起来之后执行多条语句,下图为双分支示例:
if(表达式)
语句;//每一个分号隔开的叫做一条语句
else
语句;//注意!无大括号直接写只能执行一条语句
下图为多分支示例:
if(表达式)//第一条语句也没有分号
语句;
else if(表达式);
语句;//注意else if语句结束要有分号
else if(表达式);
语句:
//此处省略若干个else if
else//此处便是最后一条语句了,无分号
语句;
下图为执行多条语句的示例:
if(表达式)
{
语句01;
语句02;
//....
}
//下面的可以单支,双支也可以多分支
悬空else问题
示例:
#include <stdio.h>
int main()
{
int a = 0;
int b = 2;
if(a == 1)
if (b == 2)
printf("hehe\n");
else
printf("haha\n");
return 0;
}
以上这段代码的打印结果大多数人可能第一眼看到之后,就会说屏幕上会打印 :haha,因为他们会认为:第六行的表达式判断之后,a是不等于1的,故表达式为假,执行else后面的语句。但是其实不然,else只于离他最近的那个 if 匹配,因此以上的代码的真实打印结果为:不打印。
所以好的代码书写风格可以大大减少不必要的误会
//正确的书写方式
if(a == 1)
if(b == 2)
printf("hehe\n");
else
printf("haha\n");
- switch语句
switch语句也是一种分支语句,多用于多分支的情况
switch语句的语法格式:
switch(整形表达式)//后面无需再放分号
{
case (整形常量表达式):
语句;
break;
//break是决定了程序走到该位置之后还要不要往下走
//有break直接跳出switch
//无break继续往下执行其他的case语句
//直至遇到break为止
}
要注意的细节:
(以代码为例)
#include <stdio.h>
int main()
{
int day = 0;
scanf("%d",&day);
switch (day)
{
case 1:
//以下略
}
return 0;
}
要注意的细节
(对照上图)
- 如果将第4行的代码改成:float day,那么改程序将无法继续执行,因为这样改完之后原来的day就被改为了浮点型,day传到第6行之后还是一个浮点型,而使用switch的语法明确规定:switch(),括号中要写整型常量表达式,必须为整型和常量
- 还有,如果在switch语句执行开头提前定义好一个整形变量,并给它赋值,之后再把这个变量放入case 的后面,此程序也是无法执行的。下图示例:
int n = 1;
switch (/*此处略*/)
{
case n:
//上面的操作一定会引起编译器的报错
//因为n本质上还是属于是一个变量
//case后根据语法规范必须为整形且常量
}
- 另外,如果case后面跟的满足整型,常量,并且是一个表达式的话,也是可以执行的下去的‘
//示例
case 1+0:
//这样写也是可以编译的
- 最后就是,如果case后面跟的是一个字符型也是能够编译过去的,因为字符也是属于整形的一种,字符以ascii码的形式储存在计算机之中的。
switch中的的default子句:
此子句适用于处理那些所有分支情况之外的输入
示例:
//多余的代码略写
int day = 0;
scanf("%d".&day);
switch(day)
{
case 1:
//case内的语句和break略写
case 2:
case 3:
case 4:
case 5:
case 6:
case 7:
default:
printf("输入错误\n");
break;
}
如上图所示,case语句之中只给出了七个分支来选择,但是如果输入者一不小心输入错误,没有输入1至7中的数(比如输入了一个9),那么程序最后就会不编译,为防止出现这种情况的发生,所以专门设计了一个default子句用来供那些别的错误情况进入,以给予输入者一个错误提示。另外,default子句不管放在开头还是结尾都没问题,但是我们一般默认放置句尾。
循环语句:循环结构分为三种:while循环,for循环,do while循环
- while循环语法结构
while(//表达式,即判断循环执行的条件)
{
循环语句;
}
上面的表达式结果如果为真,即非0,那么循环执行
如果表达式结果为假,即为0 ,那么循环体不执行
注意事项:
如果在while循环中有break,那么该break用于调出当前所在的循环体
就是说只能跳一级,跳出它当前所在的循环。如果外面还有循环体,那照样还要继续执行下去
如果在while循环中有continue,那么continue的作用就是用于跳过continue后面的代码,直接到程序开头的判断部分,看要不要继续往下执行代码,示例如下:
//代码多余的部分略
while (i <= 10)
{
if(i == 5)
continue;
printf("%d ",i);
i++;
}
上面的代码打印结果就是 1234,然后后面就不打了
因为当i变为5的时候经 if 语句的判断为真,到continue处,又回到代码while循环判断的开头,看是否执行下一次的循环,判断之后可执行,又经if 来到continue处,又回到while处判断,可执行…如此往复下去,没有跳出这个死循环的可能。后面也不可能再去打印别的东西。
for循环的continue,是直接跳到for循环的表达式3之中,执行调整部分,由此可见while循环和for循环的continue是有一定区别的,while循环是完全有可能直接跳过调整部分的,因为调整部分有可能在他的下面的代码
譬如上面的代码块就是这样的。
- for循环语法结构
for(表达式1;表达式2;表达式3)
{
循环语句;
}
for循环其实是while循环的进一步改进,因为while循环的初始化部分(int i = 0),条件判断部分(while(i>10)),调整部分(i ++),这几个部分之间相隔有的时候会很远,如果需要改动的话就会很容易改动。
for循环中,表达式1用于给循环变量一个初始值(表达式 1,只会执行一次,往后就没用了,每次循环开始前变量保留着上一次的值,除非这个循环本身就在另一个循环之中,这样的话每次都会初始化一遍,所以一般情况下,再上来的时候循环变量只会走 表达式 2 判断一下和 表达式 3 自增一下,随后继续去执行下面的代码),表达式2用于判断,表达式3用于调整。
要注意的要点:尽量不要在循环体内改变循环变量,不然循环很容易失去控制,以下图代码块为例:
#include <stdio.h>
int main()
{
for(i=0; i<11; i++)
{
printf("%d",i);
i = 5;
}
return 0;
}
上述代码是一个连续打印6的一个死循环,因为每次走到第七行时,i 都会被赋值成 5。再上去到调整语句自增。
所以说循环内部千万不要改变循环变量。
其次要注意的要点:for循环的语句判断部分采用开区间,因为使用开区间的话不等号旁边表示的是循环的次数
代码的可读性更高。比如:i<11.
for循环的用法也是非常灵活的,三个表达式可以随意省略,但是判断表达式还是最好不要省略,因为极易造成死循环。下面再来看一个示例:
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
for(; i<3;i++)
for(; j<3; j++)
{
printf("hehe\n");
}
return 0;
}
此处按照正常的理解来说,第四五行应该已经对 i 和 j 进行了初始化,随后再去执行的时候,循环出三个 i ,每个 i 再分出来三个 j,所以总共应该打印应该是九个hehe。但事实上并不是这样,真正的执行的过程为:i 初始化为 0之后,i 加一,与 j 相关的循环执行三次,printf 也打印三次,但是之后 i 在加一次,在执行 j 循环时,j 的初始化是在循环之外的,因此 j 仍然是3,循环无法执行,在往后也一样是这样。所以最终只打印三次hehe。
for循环还可以使用两个变量循环变量来控制,例子如下:
int x ,y;
for(x = 0&&y = 0;x<10&&y<10;x++&&y++)
- do while循环
do
{
语句1;
语句2;
.......
}while(判断语句);
//判断语句旁边的的分号千万不能少,不然的话语法就过不去了
do while循环执行方式很简单,就是什么都不管直接先去执行括号内的语句,执行完了再去判断还要不要继续走下去,所以说do while 最少都能执行一次
do while 语句中的 continue 与 break 的用法
continue:直接跳过它下面的语句至最后的那个判断语句,然后再从头开始
break:直接就是调出所在的那个循环不执行了
示例:
do
{
if(i == 5)
continue;
printf("%d ",i);
i++;
}while(i<=10);
最终打印结果就是: 1234,因为当代码中 i 走到 5 的时候,第5 行的continue 就会开始执行,使其跳转到第8 行进行判断,判断为真,跳到开头的第4行,继续执行,再继续跳转…所以从 i 变成 5 开始,这段代码就变成了死循环。
此外,如果第 5 行的语句被改成了 break 就会直接跳出所在的循环,直接去执行第 9 行的语句
循环练习题
- 题目一(阶乘)
//计算n的阶乘
#include <stdio.h>
int main()
{
int ret = 1;
int i = 0;
int n = 0;
scanf("%d",&n);
for(i = 1; i<=n; i++)
{
ret *= i;
}
printf("%d",ret);
return 0;
}
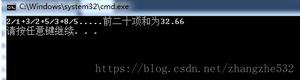
- 题目二(阶乘和)
//计算 1!+2!+3!+.....+10!
//只写出了核心步骤
int ret = 1;
int i,sum = 0;
int n = 1;
for(n=1; n<11; n++)
{
ret = 1;
//ret每次都必须要重新赋值
//不然里面会保留上一次的阶乘值
//致使我们无法形成阶乘相加的效果
for(i = 1; i<=n; i++)
//注意,这里的 i ,每次都会初始化一次
//因为这个i的循环本身,就是在循环里面
{
ret *= i;
}
sum += ret;
}
return 0;
上面这段代码写出来,思路非常的加单粗暴,就是要有各个不同的阶乘,那么就用 n 来控制,要有阶乘,那么就用 i 来控制。但是这种思路用来解决阶乘相加的问题其实效率过低,因为每次当代码走到第14行的时候 ,每次要算阶乘的时候总是会出现一个问题,就是每一次阶乘前面总是会把上一次的阶乘重算一遍,再乘上一个最新更新的 i ,这样非常浪费时间
图解上面这段代码的缺陷:
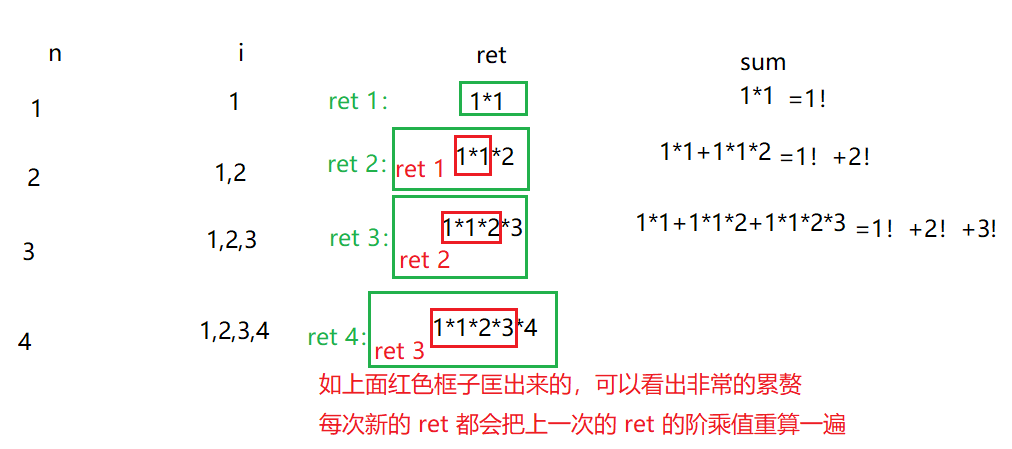
所以说我们可以这样想,可不可以更高效地利用数据,比如:1! 用完不要扔掉,再给他乘以一个 2,
变成 2!,同理 2!也不要扔掉,再给他乘以一个 3,最后把他们相加放到 sum 里面就行了。
//计算 1!+2!+3!+......+10!
//优化后的核心步骤
for(n=1; n<11; n++)
{
ret *= n;
sum += ret;
}
优化后的图解:
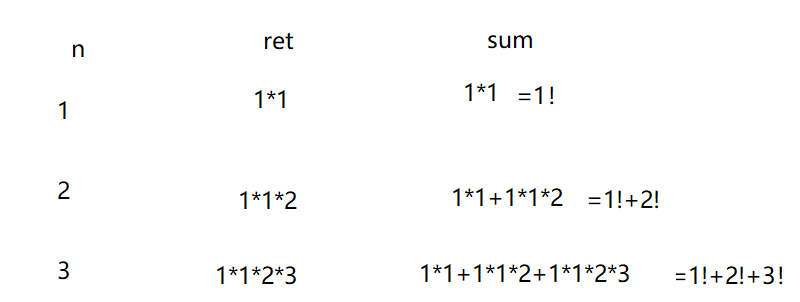
可以对照其对应的代码块,不难发现,这个效果一个循环就搞定了,利用率还非常高
- 题目三(二分查找)
//在一个有序数组中查找具体的某个数
//有序,即排好序的,如果从前往后找的话效率过低
//此题使用二分查找法
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int k = 7;//此处为要查找的元素
int sz = size of(arr)/size of(arr[0]);
//上面这行是用来计算出数组里面的元素个数
int left = 0;
int right = sz - 1;
while(left <= right)
{
int mid = (left + right)/2;
if(arr[mid] < k)
{
left = mid + 1;
}
else if(arr[mid] > k)
{
right = mid - 1;
}
else
{
printf("找到了,下标为:%d\n",mid);
break;
}
}
if(left > right)
{
printf("找不到\n");
}
return 0;
}
使用二分查找法去寻找数可以大大提高查找效率,其原理非常简单:就是先算出数组中的元素个数,然后将查找时移动的右下标(right)初始值表示出来(即:数组元素个数减一),其次左下标(left)的初始值赋 0 (因为数组元素下标是从 0 开始的),然后表示出 mid ,就是左右下标的平均值,再用这个平均值去和要去查找的数 k 去比较,如果 mid 比 k 大,mid减一并将值赋给left,实现左值的更新,若 mid 比 k 小,mid 减一赋给 right,实现右值的更新,由此不断循环往复左右值相距越来越近,若能实现左右值相等,则查找的数是存在的,若逼近到最后直至左右值交叉,则说明要查找的数不存在。图示如下:
- [
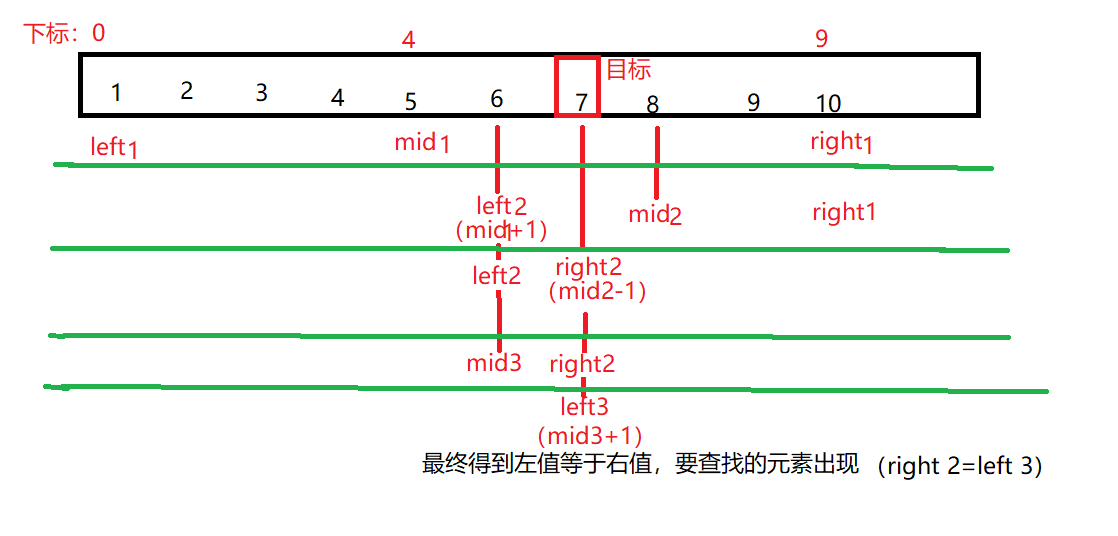
https://imgtu.com/i/gm5KGF
- 题目四(两边往中间渐变)
//编写多个字符从两端向中间移动
//其实就是一串字符从两端向中间移动
//每次露出左数第一个未知和右数第一个未知
#include <stdio.h>
#include <string.h>
#include <windows.h>
int main()
{
char arr1[] = "welcome to world";
char arr2[] = "################";
int left = 0;
int right = strlen (arr1)-1;
printf("%s\n", arr2);
while(left <= right)
{
arr2[left] = arr1[left];
arr2[right] = arr1[right];
Sleep(1000);//此处s必须大写,这里起到休眠1秒的作用
system("cls");//此处起到闪屏的动态作用
left++;
right++;
printf("%s",arr2);
}
return 0;
}
这道题目的原理和二分查找法类似,不再赘述。
此外还要注意的是:strlen()用于求字符串的长度,即里面含有几个字符
sizeof()用于求数组所占的内存空间的大小
- 题目五(密码登录)
//模拟密码登录的情景,只允许登录三次
//三次都不对,则退出程序
#include <stdio.h>
#include <string.h>
int main()
{
int i = 0;
char password[20] = { 0 };
for (i = 0; i < 3; i++)
{
printf("请输入密码:> ");
scanf("%s", password);//数组名本身就是地址,不是需要再用取地址符
if (strcmp(password, "123456") == 0)//if后别加分号!!(淦,找了一个下午的bug)
{
printf("登陆成功\n");
break;
}
else
{
printf("登陆失败,请重新输入!\n");
}
}
if (i == 3)
{
printf("三次错误,退出程序\n");
}
return 0;
}
此处的 strcmp(字符串 1,字符串 2)是用于对比字符串的内容是否一致,如果一致,strcmp 返回一个 0 ,这也是为什么 if 里面判断其是否等于 0。如果不一致,有两种情况:字符串 1 大于字符串 2 ,返回值大于 0 ;字符串 1 小于字符串 2,返回值小于 0 。此外,strcmp 的比较方法是:字符串上的每一位逐个比较,比较对应位置上字符的 ASCII 码值,不是比较字符串的长度,一旦对应位置上的字符大小分出高下,那么两个字符也立刻分出高下,不管后面的字符或大或小或长或短。下面用图示来解释:

- 题目六(猜数字游戏)
//写一个猜数字游戏
//游戏要求如下:
//1.自动产生一个 1-100 之间的随机数
//2.猜数字
// a.猜对了,就恭喜你游戏结束
// b.你猜错了,会告诉你猜大了,还是猜小了
//3.游戏会一直玩,除非退出游戏
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void menu()//menu函数的功能就是去实现一个菜单界面
{
printf("-------------------\n");
printf("-----1.玩游戏------\n");
printf("-----2,退出游戏----\n");
printf("-------------------\n");
}
void game()//game函数的功能就是去实现游戏的基本操作和随机数的产生
{
int ret = 0;
int guess = 0;
ret = rand() % 100 + 1;//此处就是生成随机数的关键,rand的用法可以去MSDN去查
//还有题目要求是1-100的随机数所以rand返回值必须模上100.随机数就可以被限定在0-99再加1,就是1-100
while (1)//这个while实现的就是猜数字的的过程
{
printf("请猜一个数:> \n");
scanf("%d", &guess);
if (guess < ret)//这里就是要让guess这个猜的值和我们随机生成的数来做比较
{
printf("猜小了\n");
}
else if(guess > ret )
{
printf("猜大了\n");
}
else
{
printf("恭喜你,猜对了\n");
break;
}
}
}
int main()
{
srand((unsigned int)time(NULL));//这里和上面的rand相联系,是rand语法规定的一部分,这里的作用来给生成的随机数一个起点
//里面的那个time()是个时间戳,就是用现在的时间和计算机的起始时间换算出一个随机数
//因为srand里面必须要填上一个随机数所以用时间就是再好不过的了
//还有就是srand的语法规定里面的数必须是无符号整形所以(unsigned int)用来强制改变数的类型
int input = 0;
do //此处使用do while循环就是要保证不管玩不玩先进去选择
{
menu();
printf("请按菜单要求输入一个数:> ");
scanf("%d", &input);
switch (input)
{
case 1:
game();
break;
case 0:
printf("退出游戏\n");
break;
defult ://此处的的defult 的作用也很关键。它可以防止玩家输入其他数字进入到while()的判断之中被误判为真
printf("输入错误,请重输\n");
}
} while (input);//此处用input来判断是很巧妙的,因为选择上input的只有0和1去供你选择,若为0便是假 跳出循环
system("pause"); //若为 1便是真,继续循环
//选择 0 的时候程序便会跳到67行终止
return 0;
}
- goto语句
goto语句在C语言可以改变程序的进程顺序,只要在想跳转的地方做个标记,然后程序走到对应的goto语句处就会跳转到标记处重新开始执行。(感觉有点像《火影忍者》里面波风水门的飞雷神)但是写程序的时候要小心,goto语句有可能导致程序混乱产生bug。另外,goto语句不可以跨函数跳跃。
#include <stdio.h>
int main()
{
flag://这里就是标记的地方,一开始程序进去忽略这个东西
printf("hehe\n");
printf("haha\n");
goto flag;//这里就是让程序跳转到标记处的语句
return 0;
}
- getchar与putchar用法
下图为示例:
#include<stdio.h>
int main()
{
int ch = getchar();
//getchar是用来接收键盘上输入的字符
//之后将接受的字符转化为ASCII码值存放起来
//由前面的存储类型是int也是可以看出来的
//总之,用法是和scanf是差不多的
putchar(ch);
//putchar把接收到的字符打印出来
//原理和printf差不多
return 0;
}
此外还要注意的是:getchar获取一个字符如果失败了,那么他就会返回一个EOF
EOF 翻译过来就是:文件终止(end of file)
#include <stdio.h>
int main()
{
int ch = 0;
while((ch = getchar())!=EOF)
//上面条代码就是让getchar读取一个数
//判断它有没有读取错误,若对的话则循环
{
putchr(ch);
}
return 0;
}
上面的这段代码的效果即输入什么就打印什么,可以不停地输,不停地打
例:输 a 则打 a,输 b 则打 b。
如果想要循环停止的话,那么就可以输入一个:ctrl 加 z ,其原理其实就是给 getchar 输入一个错误字符
让他终止,返回一个 EOF。
getchar 接收字符的原理:getchar 和 电脑键盘之间有一个缓冲区,该缓冲区用于存放键盘上输入的东西,此外getchar 只要是缓冲区里面的东西一律照收不误,包括回车,回车如果输入进去就会被缓冲区理解为一个 \n ,所以上述代码的输入和打印形式为:
a //这里先给他一个a ,再打了一个回车
a
b
b
就是说,getchar 先读取了 a ,随后 a被打印,之后又读取一个 \n 由此 b 只能在第三行开始输入,以此类推…
getchar 与putchar的实际应用:
实例如下图:
#include <stdio.h>
int main()
{
int password[20] = {};
printf("请输入密码:> ");
scanf("%s", password);
printf("请确认密码:> ");
int tmp = 0;
while ((tmp = getchar()) != '\n')
{
;
}
int ch = getchar();
if (ch == 'Y')
{
printf("确认成功\n");
}
else
{
printf("确认失败\n");
}
return 0;
}
上面的一段的代码写的是一个输入密码并确认的函数,具体分析:
首先我们创建一个数组,用于存放输入的字符串,之后创建一个 tmp ,用循环来消耗 scanf 拿不走的字符串,就是让while里面的getchar在读到 \n 之前,一直用上面代码块中的第11行的空语句来来消耗那些没用的(就是说getchar读入,但不会进行操作),即空格剩下的 (空格)abcdef \n,因为如果不去消耗的话,第13行的getchar将直接读取 6 后面的那个空格,然后自动默认走else 后面的分支,随后在屏幕上直接打印 :确认失败。由此可见,getchar 的作用非常直白,只是在读取的时候看到缓冲区有什么就读什么。
[

到此这篇关于C语言基础解析之分支与循环语句的文章就介绍到这了,更多相关C语言 分支与循环语句内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 C语言基础解析之分支与循环语句 的全部内容, 来源链接: utcz.com/p/247265.html