掌握Android Handler消息机制核心代码
阅读前需要对handler有一些基本的认识。这里先简要概述一下:
一、handler基本认识
1、基本组成
完整的消息处理机制包含四个要素:
Message(消息):信息的载体MessageQueue(消息队列):用来存储消息的队列Looper(消息循环):负责检查消息队列中是否有消息,并负责取出消息Handler(发送和处理消息):把消息加入消息队列中,并负责分发和处理消息
2、基本使用方法
Handler的简单用法如下:
Handler handler = new Handler(){
@Override
public void handleMessage(@NonNull Message msg) {
super.handleMessage(msg);
}
};
Message message = new Message();
handler.sendMessage(message);
注意在非主线程中的要调用Looper.prepare()和 Looper.loop()方法
3、工作流程
其工作流程如下图所示:
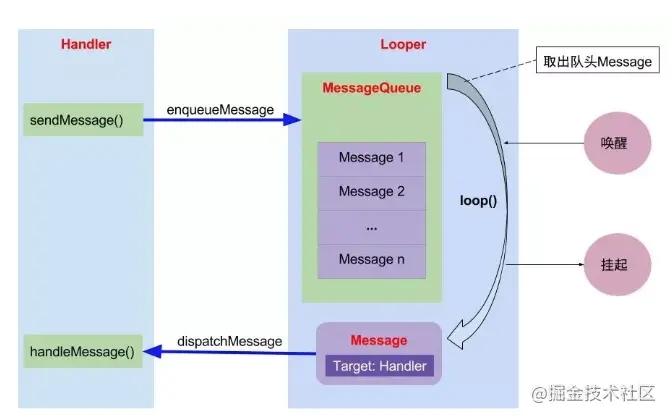
工作流程 从发送消息到接收消息的流程概括如下:
- 发送消息
- 消息进入消息队列
- 从消息队列里取出消息
- 消息的处理
下面就一折四个步骤分析一下相关源码:
二、发送消息
handle有两类发送消息的方法,它们在本质上并没有什么区别:
sendXxxx()
- boolean sendMessage(Message msg)
- boolean sendEmptyMessage(int what)
- boolean sendEmptyMessageDelayed(int what, long delayMillis)
- boolean sendEmptyMessageAtTime(int what, long uptimeMillis)
- boolean sendMessageDelayed(Message msg, long delayMillis)
- boolean sendMessageAtTime(Message msg, long uptimeMillis)
- boolean sendMessageAtFrontOfQueue(Message msg)
postXxxx()
- boolean post(Runnable r)
- boolean postAtFrontOfQueue(Runnable r)
- boolean postAtTime(Runnable r, long uptimeMillis)
- boolean postAtTime(Runnable r, Object token, long uptimeMillis)
- boolean postDelayed(Runnable r, long delayMillis)
- boolean postDelayed(Runnable r, Object token, long delayMillis)
这里不分析具体的方法特性,它们最终都是通过调用sendMessageAtTime()或者sendMessageAtFrontOfQueue实现消息入队的操作,唯一的区别就是post系列方法在消息发送前调用了getPostMessage方法:
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
需要注意的是:sendMessageAtTime()再被其他sendXxx调用时,典型用法为:
sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
若调用者没有指定延迟时间,则消息的执行时间即为当前时间,也就是立即执行。Handler所暴露的方法都遵循这种操作,除非特别指定,msg消息执行时间就为:当前时间加上延迟时间,本质上是个时间戳。当然,你也可以任意指定时间,这个时间稍后的消息插入中会用到。 代码很简单,就是讲调用者传递过来的Runnable回调赋值给message(用处在消息处理中讲)。 sendMessageAtTime()和sendMessageAtFrontOfQueue方法都会通过enqueueMessage方法实现消息的入栈:
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
代码很简单,主要有以下操作:
- 让
message持有发送它的Handler的引用(这也是处理消息时能找到对应handler的关键) - 设置消息是否为异步消息(异步消息无须排队,通过同步屏障,插队执行)
- 调用
MessageQueue的enqueueMessage方法将消息加入队列
三、消息进入消息队列
1、入队前的准备工作
enqueueMessage方法是消息加入到MessageQueue的关键,下面分段来分析一下:
boolean enqueueMessage(Message msg, long when) {
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
//...省略下文代码
}
这端代码很简单:判断message的target是否为空,为空则抛出异常。其中,target就是上文Handler.enqueueMessage里提到到Handler引用。 接下来下来开始判断和处理消息
boolean enqueueMessage(Message msg, long when) {
//...省略上文代码
synchronized (this) {
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
msg.markInUse();
msg.when = when;
//...省略下文代码
}
//...省略下文代码
}
首先加一个同步锁,接下来所有的操作都在synchronized代码块里运行 然后两个if语句用来处理两个异常情况:
- 判断当前
msg是否已经被使用,若被使用,则排除异常; - 判断消息队列(
MessageQueue)是否正在关闭,如果是,则回收消息,返回入队失败(false)给调用者,并打印相关日志
若一切正常,通过markInUse标记消息正在使用(对应第一个if的异常),然后设置消息发送的时间(机器系统时间)。 接下来开始执行插入的相关操作
2、将消息加入队列
继续看enqueueMessage的代码实现
boolean enqueueMessage(Message msg, long when) {
//...省略上文代码
synchronized (this) {
//...省略上文代码
//步骤1
Message p = mMessages;
boolean needWake;
//步骤2
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
//步骤3
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
//步骤4
return true;
}
首先说明MessageQueue使用一个单向链表维持着消息队列的,遵循先进先出的软解。 分析上面这端代码:
第一步:mMessages就是表头,首先取出链表头部。
第二步:一个判断语句,满足三种条件则直接将msg作为表头:
- 若表头为空,说明队列内没有任何消息,msg直接作为链表头部;
- when == 0 说明消息要立即执行(例如
sendMessageAtFrontOfQueue方法,但一般的发送的消息除非特别指定都是发送时的时间加上延迟时间),msg插入作为链表头部; when < p.when,说明要插入的消息执行时间早于表头,msg插入作为链表头部。
第三步:通过循环不断的比对队列中消息的执行时间和插入消息的执行时间,遵循时间戳小的在前原则,将消息插入和合适的位置。
第四步:返回给调用者消息插入完成。
需要注意代码中的needWake和nativeWake,它们是用来唤醒当前线程的。因为在消息取出端,当前线程会根据消息队列的状态进入阻塞状态,在插入时也要根据情况判断是否需要唤醒。
接下来就是从消息队列中取出消息了
四、从消息队列里取出消息
依旧是先看看准备准备工作
1、准备工作
在非主线程中使用Handler,必须要做两件事
Looper.prepare():创建一个LoopLooper.loop():开启循环
我们先不管它的创建,直接分段看啊循环开始的代码:首先是一些检查和判断工作,具体细节在代码中已注释
public static void loop() {
//获取loop对象
final Looper me = myLooper();
if (me == null) {
//若loop为空,则抛出异常终止操作
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
if (me.mInLoop) {
//loop循环重复开启
Slog.w(TAG, "Loop again would have the queued messages be executed"
+ " before this one completed.");
}
//标记当前loop已经开启
me.mInLoop = true;
//获取消息队列
final MessageQueue queue = me.mQueue;
//确保权限检查基于本地进程,
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
final int thresholdOverride =
SystemProperties.getInt("log.looper."
+ Process.myUid() + "."
+ Thread.currentThread().getName()
+ ".slow", 0);
boolean slowDeliveryDetected = false;
//...省略下文代码
}
2、loop中的操作
接下来就是循环的正式开启,精简关键代码:
public static void loop() {
//...省略上文代码
for (;;) {
//步骤一
Message msg = queue.next();
if (msg == null) {
//步骤二
return;
}
//...省略非核心代码
try {
//步骤三
msg.target.dispatchMessage(msg);
//...
} catch (Exception exception) {
//...省略非核心代码
} finally {
//...省略非核心代码
}
//步骤四
msg.recycleUnchecked();
}
}
分步骤分析上述代码:
步骤一:从消息队列MessageQueue中取出消息(queue.next()可能会造成阻塞,下文会讲到)
步骤二:如果消息为null,则结束循环(消息队列中没有消息并不会返回null,而是在队列关闭才会返回null,下文会讲到)
步骤三:拿到消息后开始消息的分发
步骤四:回收已经分发了的消息,然后开始新一轮的循环取数据
2.1 MessageQueue的next方法
我们先只看第一步消息的取出,其他的在稍后小节再看,queue.next()代码较多,依旧分段来看
Message next() {
//步骤一
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
//步骤二
int pendingIdleHandlerCount = -1;
//步骤三
int nextPollTimeoutMillis = 0;
//...省略下文代码
}
第一步:如果消息循环已经退出并且已经disposed之后,直接返回null,对应上文中Loop通过queue.next()取消息拿到null后退出循环
第二部:初始化IdleHandler计数器
第三部:初始化native需要用的判断条件,初始值为0,大于0表示还有消息等待处理(延时消息未到执行时间),-1则表示没有消息了。
继续分析代码:
Message next() {
//...省略上文代码
for(;;){
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
//...省略下文代码
}
}
这一段比较简单:
开启一个无限循环
nextPollTimeoutMillis != 0表示消息队列里没有消息或者所有消息都没到执行时间,调用nativeBinder.flushPendingCommands()方法,在进入阻塞之前跟内核线程发送消息,以便内核合理调度分配资源
再次调用native方法,根据nextPollTimeoutMillis判断,当为-1时,阻塞当前线程(在新消息入队时会重新进入可运行状态),当大于0时,说明有延时消息,nextPollTimeoutMillis会作为一个阻塞时间,也就是消息在多就后要执行。
继续看代码:
Message next() {
//...省略上文代码
for(;;){
//...省略上文代码
//开启同步锁
synchronized (this) {
final long now = SystemClock.uptimeMillis();
//步骤一
Message prevMsg = null;
Message msg = mMessages;
//步骤二
if (msg != null && msg.target == null) {
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
//步骤三
if (msg != null) {
//步骤四
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
//步骤五
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
//步骤六
nextPollTimeoutMillis = -1;
}
}
//...省略下文IdleHandler相关代码
}
}
分析一下代码:
第一步:获取到队列头部
第二步:判断当前消息是否为同步消息(异步消息的target为null),开启循环直到发现同步消息为止
第三步:判断消息是否为null,不为空执行第四步,为空执行第六步;
第四步:判断消息执行的时间,如果大于当前时间,给前文提到的nextPollTimeoutMillis赋新值(当前时间和消息执行时间的时间差),在这一步基本完成了本次循环所有的取消息操作,如果当前消息没有到达执行时间,本次循环结束,新循环开始,就会使用上文中提到的nativePollOnce(ptr, nextPollTimeoutMillis) ;方法进入阻塞状态
第五步:从消息队列中取出需要立即执行的消息,结束整个循环并返回。
第六部:消息队列中没有消息,标记nextPollTimeoutMillis,以便下一循环进入阻塞状态
剩下的代码就基本上是IdleHandler的处理和执行了,在IdleHandler小节里进行讲解,这里就不展开说明了。
五、消息的处理
还记得上文中loop方法中的msg.target.dispatchMessage(msg) ;吗? 消息就是通过dispatchMessage方法进行分发的。其中target是msg所持有的发送它的handler的引用,它在发送消息时被赋值。 dispatchMessage的源码如下:
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
代码很简单,通过判断Message是否有Runable来决定是调用callback还是调用handleMessage方法,交给你定义的Handler去处理。需要注意的是,callback虽然是一个Runable,但是它并没有调用run方法,而是直接执行。这说明它并没有开启新的线程,就是作为一个方法使用(如果一开始Handler使用kotlin写的话,此处或许就是一个高阶函数了)。
六、其他关键点
上面讲完了消息处理的主流程,接下来讲一下主流程之外的关键点源码
1、 Loop的创建
还记得上文中的说到的在非主线程中的要调用Looper.prepare()和 Looper.loop()方法吗?这两个方法可以理解为初始化Loop和开启loop循环,而主线程中无需这么做是因为在app启动的main方法中,framework层已经帮我们做了。我们分别来看这两个方法:
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
这里首先使用了一个静态的ThreadLocal确保Loop的唯一性,同时做到线程隔离,使得一个线程有且只有一个Loop实例。接着初始化Loop,同时创建MessageQueue (quitAllowed设置是否允许退出)。在这一步实现了Loop和消息队列的关联。
需要注意的是,Loop的构造方式是私有的,我们只能通过prepare 区创建,然后通过myLooper方法去获取。
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
ThreadLocal.get源码:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
可以看到,每个Thread都持有一个ThreadLocalMap ,它和HashMap使用相同的数据结构,使用ThreadLocal作为key值,value就是Loop实例。不难发现:我们只能获取到当前线程的Loop实例。
Loop也提供了主线程中初始化的办法prepareMainLooper ,但是这个方法明确说明不允许调用,只能由系统自己调用。 这基本上就是Loop创建的关键了,也是在这里完成了Loop和消息队列以及线成之间的关联。
2、Handler的创建
Handler的构造函数有以下几个:
- public Handler()
- public Handler(Callback callback)
- public Handler(Looper looper)
- public Handler(Looper looper, Callback callback)
- public Handler(boolean async)
- public Handler(Callback callback, boolean async)
- public Handler(Looper looper, Callback callback, boolean async)
其中第一个和第二个已经被废弃了,实际上第1~5个构造方法都是通过调用public Handler(Callback callback, boolean async)或public Handler(Looper looper, Callback callback, boolean async)实现的,它们的源码如下:
public Handler(@NonNull Looper looper, @Nullable Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public Handler(@Nullable Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
//注意这个异常,loop不能为空的,首先要Looper.prepare();
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
两个方法最大的区别就是一个使用传递过来的loop,一个直接使用当前线程的loop,然后就是相同的一些初始化操作了。这里就出现了一个关键点handler处理消息所处的线程和创建它的线程无关,而是和创建它时loop的线程有关的。
这也是Handler能实现线程切换的原因所在: handler的执行跟创建handler的线程无关,跟创建looper的线程相关,假如在子线程中创建一个Handler,但是Handler相关的Looper是主线程的,那么如果handler执行post一个runnable,或者sendMessage,最终的handle Message都是在主线程中执行的。
3、Message的创建、回收和复用机制
我们可以直接使用new关键字去创建一个Message:
Message message = new Message(); 但是这种做法并不被推荐,官方提供了以下几个方法供用户创建message:
这些方法除了形参有些区别,用来给message不同的成员变量赋值之外,本质上都是通过 obtain()来创建Message:
public static final Object sPoolSync = new Object();
Message next;
private static Message sPool;
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}
这端代码很简单,Message内部维持了一个单线链表,使用sPool作为头部,用来存储Message实体。可以发现,每次调用者需要一个新的消息的时候,都会先从链表的头部去取,有消息就直接返回。没有消息才会创建一个新的消息。
那么这个链表是在何时插入消息的呢?接下来看Message的回收:
public static final Object sPoolSync = new Object();
private static final int MAX_POOL_SIZE = 50;
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
该方法在每次消息从MessageQueue 队列取出分发时都会被调用,就是在上文提到的Loop.loop()方法里。 代码也很简单,首先将Message的成员变量还原到初始状态,然后采用头插法将回收后的消息插入到链表之中(限制了最大容量为50)。而且插入和取出的操作,都是使用的同一把锁,保证了安全性。
注意插入和取出都是对链表的头部操作,这里和消息队列里就不太一样了。虽然都是使用单向链表,回收时使用头插和头取,先进后出,是个栈。而在MessageQueue里是个队列,遵循先进先出的原则,而且插入的时候是根据消息的状态确定位置,并没有固定的插入节点。
这是一个典型的享元模式,最大的特点就是复用对象,避免重复创建导致的内存浪费。这也是为什么android官方推荐使用这种方式创建消息的原因:就是为了提高效率减少性能开销。
4、 IdleHandler
IdleHandler 的定义很简单,就是一个定义在MessageQueue里的接口:
public static interface IdleHandler {
boolean queueIdle();
}
根据官方的解释,在 Looper循环的过程中,每当消息队列出现空闲:没有消息或者没到任何消息的执行时间需要滞后执行的时候,queueIdle 方法就会被执行,而其返回的布尔值标识IdleHandler 是永久的还是一次性的:
ture:永久的,一旦空闲,就会执行false:一次性的,只有第一次空闲时会执行
它的使用方法如下:
Looper.getMainLooper().getQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override
public boolean queueIdle() {
return true;
}
});
看一下addIdleHandler 的实现
private final ArrayList<IdleHandler> mIdleHandlers = new ArrayList<IdleHandler>();
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}
代码很简单,就是一个List来保存接口的实现。那么它是怎么实现在出现空闲时调用呢?
还记得在上文MessageQueue的next方法中省略的代码吗?
Message next() {
//...省略不相关代码
//步骤一
int pendingIdleHandlerCount = -1; // -1 只存在第一次迭代中
for (;;) {
//...省略不相关代码
//步骤二
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
//步骤三
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
//步骤四
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
//步骤五
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
//步骤六
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
//步骤七
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
//步骤八
pendingIdleHandlerCount = 0;
}
}
接下来分步骤分析一下代码:
第一步:在取消息的循环开始前创建局部变量pendingIdleHandlerCount用来记录IdleHandler的数量,只在循环开始时为-1;
第二步:当没有取到Message消息(没有消息或者没有可立即执行的消息,也没有进去阻塞状态)或者消息需要延后执行,为pendingIdleHandlerCount 赋值记录IdleHandler的数量;
第三步:判断IdleHandler的数量,如果没有IdleHandler,则直接结束当前循环,并标记循环可进入挂起状态。
第四步:判断是否是第一次,初始化IdleHandler 的List
第五步:开始遍历所有的IdleHandler
第六步:依次执行IdleHandler 的queueIdle方法
第七部:根据各IdleHandler 的queueIdle的返回值判断IdleHandler 是永久的还是一次性的,将非永久的从数组里移除;
第八步:修改IdleHandler 的数量信息pendingIdleHandlerCount ,避免IdleHandler 重复执行。
这就是IdleHandler 的核心原理,它只在消息队列为空时,或者消息队列的头部消息为延时消息时才会被触发。当消息队列头部为延时消息时,它只会触发一次哦。在前文中取消息的小节中我们讲过:延时消息在结束当前循环后进入下一路循环会触发阻塞。
5、Handler在Framework层的应用
不知道你有没有想过为什么Android在主线程里直接帮你调用了Looper.prepare()和 Looper.loop()方法,难道只是为了你使用方便吗?这岂不是有点杀鸡用牛刀的感觉?
事实上远没有这么简单,如果你看一下framework的源码你就会发现,整个android app的运转都是基于Handler进行的。四大组件的运行,它们生命周期也是基于Handler事件模型进行的,以及点击事件等。这一切均是由Android系统框架层产生相应的message再交由一个Handler进行处理的。这个Handler就是ActivityThread内部类H,贴一段它的代码截图

可以看到,四大组件的生命周期甚至内存不足,都有handler在参与。
这也解释了为什么在主线程执行耗时任务会导致UI卡顿或者ANR:因为所有主线程也就是UI线程的逻辑代码都是在组件的生命周期里执行的,而生命周期又受到Handler的事件体系的控制,当在任意生命周期做中执行耗时操作,这会导致消息队列MessageQueue中后面的消息无法得到及时的处理,就会造成延迟,直至视觉上的卡顿,严重的则会进一步触发ANR的发生。
到此这篇关于掌握Android Handler消息机制核心代码的文章就介绍到这了,更多相关Android Handler消息机制核心代码内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 掌握Android Handler消息机制核心代码 的全部内容, 来源链接: utcz.com/p/243965.html