
MySQL必备基础之分组函数 聚合函数 分组查询详解
一、简单使用
SUM:求和(一般用于处理数值型)
AVG:平均(一般用于处理数值型)
MAX:最大(也可以用于处理字符串和日期)
MIN:最小(也可以用于处理字符串和日期)
COUNT:数量(统计非空值的数据个数)
以上分组函数都忽略空NULL值的数据
SELECT SUM(salary) AS 和,AVG(salary) AS 平均,MAX(salary) AS 最大,MIN(salary) AS 最小,COUNT(salary) AS 数量
FROM employees;

二、搭配DISTINCT去重
(以上函数均可)
SELECT SUM(DISTINCT salary) AS 和,AVG(DISTINCT salary) AS 平均,COUNT( DISTINCT salary) AS 去重数量,COUNT(salary) AS 不去重数量
FROM employees;

三、COUNT()详细介绍
#相当于统计行数方式一
SELECT COUNT(*)
FROM employees;
#相当于统计行数方式二,其中1可以用其他常量或字段替换
SELECT COUNT(1)
FROM employees;
效率问题:
MYISAM存储引擎下,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)高
因此一般用COUNT(*)统计行数
四、分组查询
#其中[]内为可选
SELECT 分组函数,列表(要求出现在 GROUP BY 的后面)
FROM 表
[WHERE 筛选条件]
GROUP BY 分组列表
[ORDER BY 子句]
示例:
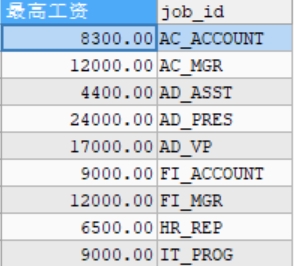
#查询每个工种的最高工资
SELECT MAX(salary) AS 最高工资,job_id
FROM employees
GROUP BY job_id;
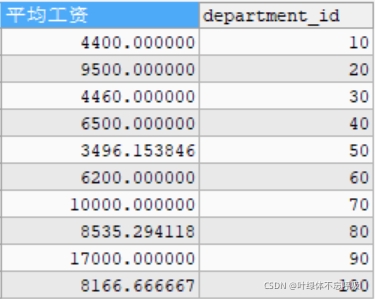
#查询每个部门中,邮箱包含a的员工的平均工资(分组前的筛选)
SELECT AVG(salary) AS 平均工资,department_id
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;
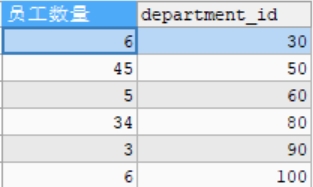
#查询部门员工数量大于2的部门的员工数量(分组后的筛选)
#使用HAVING
SELECT COUNT(*) AS 员工数量,department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>2;
#按照多字段
SELECT COUNT(*) AS 员工数量,job_id,department_id
FROM employees
GROUP BY job_id,department_id;
#完整结构
SELECT AVG(salary) AS 平均工资,department_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING AVG(salary)>9000
ORDER BY AVG(salary) DESC;
到此这篇关于MySQL必备基础之分组函数 聚合函数 分组查询详解的文章就介绍到这了,更多相关MySQL 分组函数 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 MySQL必备基础之分组函数 聚合函数 分组查询详解 的全部内容, 来源链接: utcz.com/p/231634.html








