MySQL在线DDL工具 gh-ost的原理解析
一.简介
gh-ost基于 golang 语言,是 github 开源的一个 DDL 工具,是 GitHub's Online Schema Transmogrifier/Transfigurator/Transformer/Thingy 的缩写,意思是 GitHub 的在线表定义转换器。
1.1 原理
主要实现原理,首先建两张表,一张_gho的影子表,gh-ost会将原表数据以及增量数据都应用到这个表,最后会将这个表和原表做次表名切换,另一张是_ghc表,这个表是存放changelog的数据,包括信号标记,心跳等。其次,gh-ost会开两个goroutine,一个用于拷贝原表数据,一个用于apply增量的binlog到_gho表,并且两个goroutine的并行在跑的,也就是不用关心数据是先拷贝过去还是先apply binlog过去。因为这里会对insert语句做调整,首先我们拷贝的insert into会改写成insert ignore into,而binlog内insert into会改写成replace into,这样可以很好的支持两个goroutine的并行。但这样的调整能适用所有的DDL吗?答案是否定的。最后,当原表数据全部拷贝完成后,gh-ost会进入到表交换阶段,采用更加安全的原子交换。
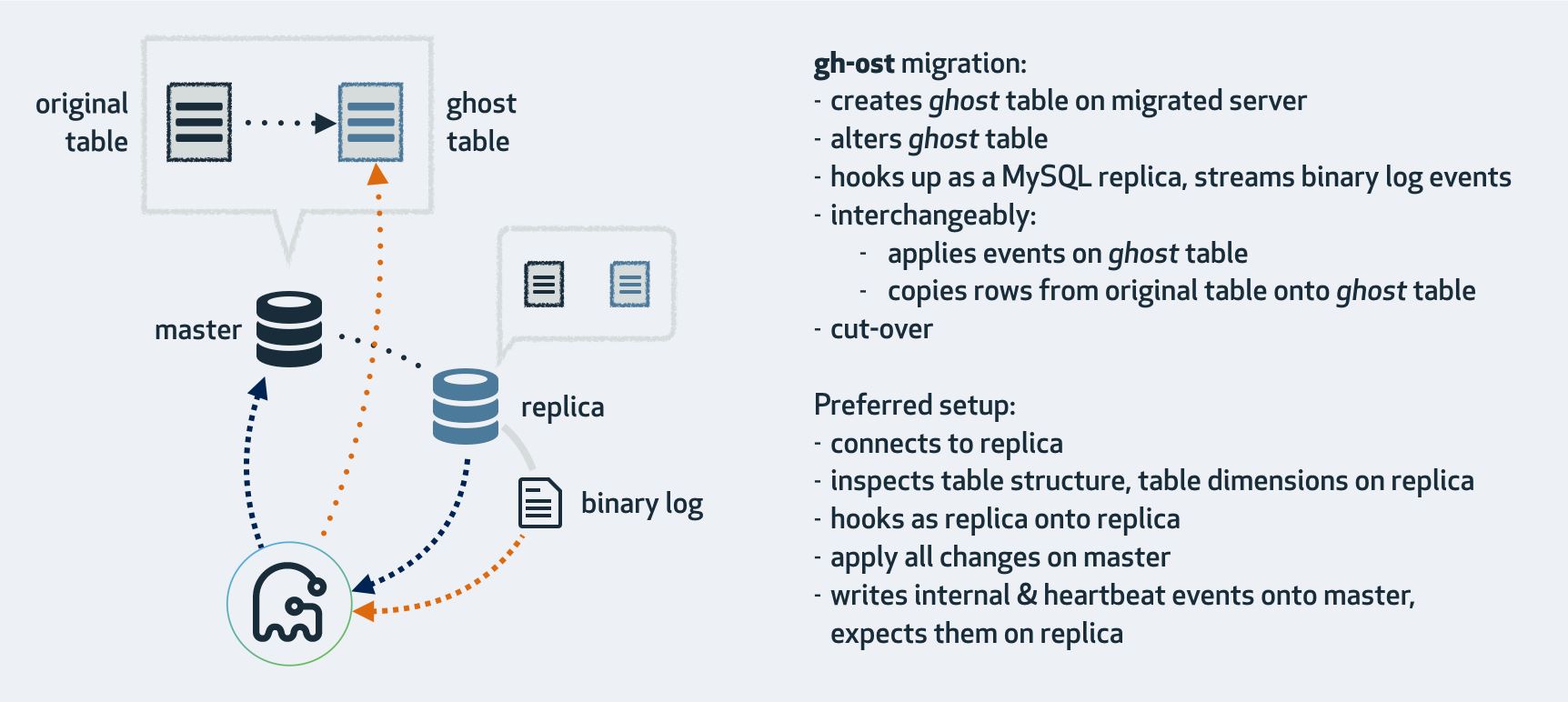
1.2 过程
1. 检查有没有外键和触发器。
2. 检查表的主键信息。
3. 检查是否主库或从库,是否开启log_slave_updates,以及binlog信息
4. 检查gho和del结尾的临时表是否存在
5. 创建ghc结尾的表,存数据迁移的信息,以及binlog信息等
---以上校验阶段
6. 初始化stream的连接,添加binlog的监听
---以下迁移阶段
7. 创建gho结尾的临时表,执行DDL在gho结尾的临时表上
8. 开启事务,按照主键id把源表数据写入到gho结尾的表上,再提交,以及binlog apply。
---以下cut-over阶段
9. lock源表,rename 表:rename 源表 to 源_del表,gho表 to 源表。
10. 清理ghc表。
1.3 特性
1. 无触发器:通过分析binlog日志的形式来监听表中的数据变更。
2. 轻量级:由于没有使用触发器,因此在操作的过程中对主库的影响是最小的,也不用担心并发和锁。
3. 可暂停:所有的写操作都是由gh-ost控制的,当限速的时候,gh-ost可以暂停向主库写入数据,创建一个内部的tracking表,以最小的系统开销向这个表中写入心跳事件。
4. 动态可控:gh-ost 可以通过 unix socket 文件或者TCP端口(可配置)的方式来监听请求,操作者可以在命令运行后更改相应的参数。
5. 可审计:使用程序接口可以获取 gh-ost 的状态,报告当前的进度,主要参数的配置以及当前服务器 的标示等等。
6. 可测试:gh-ost內建支持测试功能,通过使用--test-on-replica参数来指定: 它可以在从库上进行变更操作,在操作结束时gh-ost将会停止复制,交换表,反向交换表,保留2个表并保持同步,停止复制。可以在空闲时候测试和比较两个表的数据情况。
1.4 github地址
https://github.com/github/gh-ost/
二.测试环境:
2.1 测试服务器
主库:110.119.120.231
从库:110.119.120.230
2.2 安装
cd /usr/local/src/
wget https://github.com/github/gh-ost/releases/download/v1.0.48/gh-ost-binary-linux20190214020851.tar.gz
tar xzvf gh-ost-binary-linux-20190214020851.tar.gz -C /usr/local/
ln -s /usr/local/gh-ost /usr/bin/gh-ost
2.3 创建用户
create user ghost@'110.%' identified by 'ghost';
grant ALL PRIVILEGES on *.* to ghost@'110.%';
flush privileges;
2.4 命令参数
Usage of gh-ost:
--aliyun-rds:是否在阿里云数据库上执行。true
--allow-master-master:是否允许gh-ost运行在双主复制架构中,一般与-assume-master-host参数一起使用
--allow-nullable-unique-key:允许gh-ost在数据迁移依赖的唯一键可以为NULL,默认为不允许为NULL的唯一键。如果数据迁移(migrate)依赖的唯一键允许NULL值,则可能造成数据不正确,请谨慎使用。
--allow-on-master:允许gh-ost直接运行在主库上。默认gh-ost连接的从库。此外,单实例上DDL,单个实例相当于主库,需要开启--allow-on-master参数和ROW模式。
--alter string:DDL语句
--approve-renamed-columns ALTER:如果你修改一个列的名字,gh-ost将会识别到并且需要提供重命名列名的原因,默认情况下gh-ost是不继续执行的,除非提供-approve-renamed-columns ALTER。
--ask-pass:MySQL密码
--assume-master-host string:为gh-ost指定一个主库,格式为”ip:port”或者”hostname:port”。在这主主架构里比较有用,或则在gh-ost发现不到主的时候有用。
--assume-rbr:确认gh-ost连接的数据库实例的binlog_format=ROW的情况下,可以指定-assume-rbr,这样可以禁止从库上运行stop slave,start slave,执行gh-ost用户也不需要SUPER权限。
--check-flag
--chunk-size int:在每次迭代中处理的行数量(允许范围:100-100000),默认值为1000。
--concurrent-rowcount:该参数如果为True(默认值),则进行row-copy之后,估算统计行数(使用explain select count(*)方式),并调整ETA时间,否则,gh-ost首先预估统计行数,然后开始row-copy。
--conf string:gh-ost的配置文件路径。
--critical-load string:一系列逗号分隔的status-name=values组成,当MySQL中status超过对应的values,gh-ost将会退出。-critical-load Threads_connected=20,Connections=1500,指的是当MySQL中的状态值Threads_connected>20,Connections>1500的时候,gh-ost将会由于该数据库严重负载而停止并退出。
Comma delimited status-name=threshold, same format as --max-load. When status exceeds threshold, app panics and quits
--critical-load-hibernate-seconds int :负载达到critical-load时,gh-ost在指定的时间内进入休眠状态。 它不会读/写任何来自任何服务器的任何内容。
--critical-load-interval-millis int:当值为0时,当达到-critical-load,gh-ost立即退出。当值不为0时,当达到-critical-load,gh-ost会在-critical-load-interval-millis秒数后,再次进行检查,再次检查依旧达到-critical-load,gh-ost将会退出。
--cut-over string:选择cut-over类型:atomic/two-step,atomic(默认)类型的cut-over是github的算法,two-step采用的是facebook-OSC的算法。
--cut-over-exponential-backoff
--cut-over-lock-timeout-seconds int:gh-ost在cut-over阶段最大的锁等待时间,当锁超时时,gh-ost的cut-over将重试。(默认值:3)
--database string:数据库名称。
--debug:debug模式。
--default-retries int:各种操作在panick前重试次数。(默认为60)
--discard-foreign-keys:该参数针对一个有外键的表,在gh-ost创建ghost表时,并不会为ghost表创建外键。该参数很适合用于删除外键,除此之外,请谨慎使用。
--dml-batch-size int:在单个事务中应用DML事件的批量大小(范围1-100)(默认值为10)
--exact-rowcount:准确统计表行数(使用select count(*)的方式),得到更准确的预估时间。
--execute:实际执行alter&migrate表,默认为noop,不执行,仅仅做测试并退出,如果想要ALTER TABLE语句真正落实到数据库中去,需要明确指定-execute
--exponential-backoff-max-interval int
--force-named-cut-over:如果为true,则'unpostpone | cut-over'交互式命令必须命名迁移的表
--force-table-names string:在临时表上使用的表名前缀
--heartbeat-interval-millis int:gh-ost心跳频率值,默认为500
--help
--hooks-hint string:任意消息通过GH_OST_HOOKS_HINT注入到钩子
--hooks-path string:hook文件存放目录(默认为empty,即禁用hook)。hook会在这个目录下寻找符合约定命名的hook文件来执行。
--host string :MySQL IP/hostname
--initially-drop-ghost-table:gh-ost操作之前,检查并删除已经存在的ghost表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-old-table:gh-ost操作之前,检查并删除已经存在的旧表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-socket-file:gh-ost强制删除已经存在的socket文件。该参数不建议使用,可能会删除一个正在运行的gh-ost程序,导致DDL失败。
--master-password string :MySQL 主密码
--master-user string:MysQL主账号
--max-lag-millis int:主从复制最大延迟时间,当主从复制延迟时间超过该值后,gh-ost将采取节流(throttle)措施,默认值:1500s。
--max-load string:逗号分隔状态名称=阈值,如:'Threads_running=100,Threads_connected=500'. When status exceeds threshold, app throttles writes
--migrate-on-replica:gh-ost的数据迁移(migrate)运行在从库上,而不是主库上。
--nice-ratio float:每次chunk时间段的休眠时间,范围[0.0…100.0]。0:每个chunk时间段不休眠,即一个chunk接着一个chunk执行;1:每row-copy 1毫秒,则另外休眠1毫秒;0.7:每row-copy 10毫秒,则另外休眠7毫秒。
--ok-to-drop-table:gh-ost操作结束后,删除旧表,默认状态是不删除旧表,会存在_tablename_del表。
--panic-flag-file string:当这个文件被创建,gh-ost将会立即退出。
--password string :MySQL密码
--port int :MySQL端口,最好用从库
--postpone-cut-over-flag-file string:当这个文件存在的时候,gh-ost的cut-over阶段将会被推迟,数据仍然在复制,直到该文件被删除。
--quiet:静默模式。
--replica-server-id uint : gh-ost的server_id
--replication-lag-query string:弃用
--serve-socket-file string:gh-ost的socket文件绝对路径。
--serve-tcp-port int:gh-ost使用端口,默认为关闭端口。
--skip-foreign-key-checks:确定你的表上没有外键时,设置为'true',并且希望跳过gh-ost验证的时间-skip-renamed-columns ALTER
--skip-renamed-columns ALTER:如果你修改一个列的名字(如change column),gh-ost将会识别到并且需要提供重命名列名的原因,默认情况下gh-ost是不继续执行的。该参数告诉gh-ost跳该列的数据迁移,让gh-ost把重命名列作为无关紧要的列。该操作很危险,你会损失该列的所有值。
--stack:添加错误堆栈追踪。
--switch-to-rbr:让gh-ost自动将从库的binlog_format转换为ROW格式。
--table string:表名
--test-on-replica:在从库上测试gh-ost,包括在从库上数据迁移(migration),数据迁移完成后stop slave,原表和ghost表立刻交换而后立刻交换回来。继续保持stop slave,使你可以对比两张表。
--test-on-replica-skip-replica-stop:当-test-on-replica执行时,该参数表示该过程中不用stop slave。
--throttle-additional-flag-file string:当该文件被创建后,gh-ost操作立即停止。该参数可以用在多个gh-ost同时操作的时候,创建一个文件,让所有的gh-ost操作停止,或者删除这个文件,让所有的gh-ost操作恢复。
--throttle-control-replicas string:列出所有需要被检查主从复制延迟的从库。
--throttle-flag-file string:当该文件被创建后,gh-ost操作立即停止。该参数适合控制单个gh-ost操作。-throttle-additional-flag-file string适合控制多个gh-ost操作。
--throttle-http string
--throttle-query string:节流查询。每秒钟执行一次。当返回值=0时不需要节流,当返回值>0时,需要执行节流操作。该查询会在数据迁移(migrated)服务器上操作,所以请确保该查询是轻量级的。
--timestamp-old-table:在旧表名中使用时间戳。 这会使旧表名称具有唯一且无冲突的交叉迁移
--tungsten:告诉gh-ost你正在运行的是一个tungsten-replication拓扑结构。
--user string :MYSQL用户
--verbose
--version
三. 操作模式
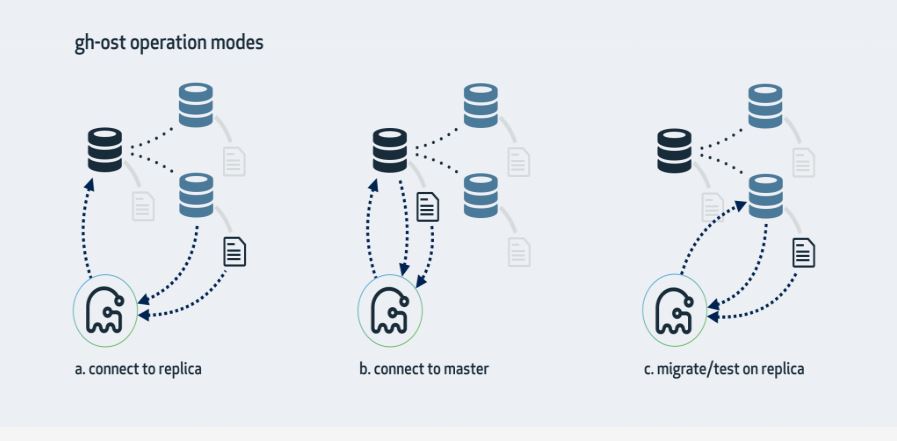
模式一 连上从库,在主库上修改
这是gh-ost 默认的工作模式,它会查看从库情况,找到集群的主库并且连接上去。修改操作的具体步骤是:
1、在主库上读写行数据;
2、在从库上读取二进制日志事件,将变更应用到主库上;
3、在从库上查看表格式、字段、主键、总行数等;
4、在从库上读取 gh-ost 内部事件日志(比如心跳);
5、在主库上完成表切换。
如果你的主库的日志格式是 SBR,工具也可以正常工作。但从库就必须配成启用二进制日志(log_bin, log_slave_updates)并且设置 binlog_format=ROW ( gh-ost 是读取从库的二进制文件)。
使用示例:
# gh-ost --initially-drop-old-table --initially-drop-ghost-table --user="ghost" --password="ghost" --host=110.119.120.230 --port=3306 --database="test" --table="t1" --verbose --alter="ADD COLUMN y1 varchar(10),add column y2 int not null default 0 comment 'test' " --assume-rbr --execute
参数含义:
--initially-drop-old-table:gh-ost操作之前,检查并删除已经存在的旧表。
--initially-drop-ghost-table:gh-ost操作之前,检查并删除已经存在的ghost表。
--verbose:执行过程输出日志
--assume-rbr:确认gh-ost连接的数据库实例binlog_format=ROW的情况下,可以指定-assume-rbr,这样可以避免从库上运行stop slave,start slave,执行gh-ost的用户也不需要SUPER权限。
模式二 直接在主库上修改
如果没有从库,或者不想在从库上操作,那直接用主库也是可以的。gh-ost 就会在主库上直接做所有的操作。仍然可以在上面查看主从复制延迟。
1)主库必须产生 Row 格式的二进制日志
2)启动 gh-ost 时必须用--allow-on-master 选项来开启这种模式
# gh-ost --initially-drop-old-table --initially-drop-ghost-table --user="ghost" --password="ghost" --host="110.119.120.231" --port=3306 --database="test" --table="t2" --verbose --alter="add column test_field varchar(256) default '';" --exact-rowcount --serve-socket-file=/tmp/gh-ost.t2.sock --panic-flag-file=/tmp/ghost.panic.t2.flag --postpone-cut-over-flag-file=/tmp/ghost.postpone.t2.flag --allow-on-master --execute
参数含义:
--exact-rowcount:准确统计表行数(使用select count(*)的方式),得到更准确的预估时间。
--serve-socket-file:gh-ost的socket文件绝对路径。如:--serve-socket-file=/tmp/gh-ost.t1.sock 创建socket文件进行监听,通过接口进行参数调整,当执行操作的过程中发现负载、延迟上升了,不得 不终止操作,重新配置参数,如 chunk-size,然后重新执行操作命令,可以通过scoket接口进行动态 调整。
#暂停
echo throttle | socat - /tmp/gh-ost.t1.sock
#恢复
echo no-throttle | socat - /tmp/gh-ost.t1.sock
修改限速参数:
echo chunk-size=1500 | socat - /tmp/gh-ost.t1.sock
echo max-lag-millis=2000 | socat - /tmp/gh-ost.t1.sock
echo max-load=Thread_running=30 | socat - /tmp/gh-ost.t1.sock
--panic-flag-file:这个文件被创建,会立即终止正在运行的gh-ost,临时文件清理需要手动进行。
--postpone-cut-over-flag-file:当这个文件存在的时候,gh-ost的cut-over阶段将会被推迟,数据仍 然在复制,但并不会切换表,直到该文件被删除。
--allow-on-master:允许gh-ost直接运行在主库上。
模式三 在从库上修改和测试
这种模式会在从库上做修改,所有操作都是在从库上做的,不会对主库产生任何影响。在操作过程中, gh-ost 也会不时地暂停,以便从库的数据可以保持最新。
--test-on-replica 表明操作只是为了测试目的。在进行最终的切换操作之前,复制会被停止。原始表和临时表会相互切换,再切换回来,最终相当于原始表没被动过。主从复制暂停的状态下,可以检查和对比这两张表中的数据(若不想stop slave,可添加参数--test-on-replica-skip-replica-stop)。
# gh-ost --initially-drop-old-table --initially-drop-ghost-table --user="ghost" --password="ghost" --host=110.119.120.230 --port=3306 --database="test" --table="t3" --verbose --alter="ADD COLUMN abc1 varchar(10),add column abc2 int not null default 0 comment 'test' " --test-on-replica --assume-rbr --execute
rds限制:
1. 用户没有 Super 权限,因此使用过程中要加上--assume-rbr,gh-ost 会认为 binlog 本身就是 row 模式,不会再去修改。阿里云RDS上的binlog 默认也是 row 模式,所以不存在问题。
2. 其它权限,主要是REPLICATION SLAVE,REPLICATION CLIENT可以拉取 binlog ,也可以获得。
3、无法连接到备库拉取binlog。备库通常对用户来说是透明的,所以gh-ost需要直接连接到主库上 去,这可能会增大对主库的负载。使用的时候需要增加--allow-on-master,--assume-master-host。 官方推荐的方式也是连接到其中一个备库,因为会有一些压力较大的SELECT操作,放在备库是最好的。
4、阿里云数据库上执行,需要增加一个参数--aliyun-rds。 目前用户使用的话,记得加上以下几个参数: --allow-on-master --assume-rbr --assume-master-host --aliyun-rds
四.gh-ost与pt-osc对比
4.1 pt-osc的简单介绍
pt-osc之工作流程
1、检查更改表是否有主键或唯一索引,是否有触发器
2、检查修改表的表结构,创建一个临时表,在新表上执行ALTER TABLE语句
3、在源表上创建三个触发器分别对于INSERT UPDATE DELETE操作
4、从源表拷贝数据到临时表,在拷贝过程中,对源表的更新操作会写入到新建表中
5、将临时表和源表rename(需要元数据修改锁,需要短时间锁表)
6、删除源表和触发器,完成表结构的修改。
pt-osc之工具限制
1、源表必须有主键或唯一索引,如果没有工具将停止工作
2、如果线上的复制环境过滤器操作过于复杂,工具将无法工作
3、如果开启复制延迟检查,但主从延迟时,工具将暂停数据拷贝工作
4、如果开启主服务器负载检查,但主服务器负载较高时,工具将暂停操作
5、当表使用外键时,如果未使用--alter-foreign-keys-method参数,工具将无法执行
6、只支持Innodb存储引擎表,且要求服务器上有该表1倍以上的空闲空间。
那么gh-ost对比pt-osc具体有哪些优势呢?下面先简单介绍下它的两个最核心的特性。
4.2 Triggerless
在gh-ost出现之前第三方MySQL DDL工具均采用触发器的方式进行实现,包括percona的pt-osc,Facebook的OSC等等。而gh-ost采用的机制和他们完全不同:它通过MySQL binlog来同步数据,gh-ost本身注册为一个fake slave,可以从集群中的master或者slave上拉取binlog,并实时解析,将变更表的所有DML操作都重新apply到影子表上面。因此对于发布期间变更表上发生的DML操作,可以完全避免由于触发器而产生的性能开销,以及锁的争抢。
除此之外,一般我们选择目标发布机器通常会选择集群中slave节点,而slave一般不会承载业务,这样binlog解析的开销也不会落在提供业务的master上面,而仅仅是一次异步的DML语句重放。
4.3 Dynamically controllable
另一个最重要的特性是动态调控,这是此前其他第三方开源工具所不具备的。
之前通过pt-osc发布时,命令执行后参数就没法修改,除非停止重来。假设发布进行到90%,突然由于其他各种原因导致服务器负载上升,为不影响业务,只能选择将发布停掉,等性能恢复再重来。
通过pt-osc发布的表都是很大的表,耗时较长,所以遇到这类场景很尴尬。因此发布中参数如果可动态调控将变得非常重要。gh-ost另外实现了一个socket server,我们可以在发布过程中,通过socket和发布进程进行实时交互,它可以支持实时的暂停,恢复,以及很多参数的动态调整,来适应外界变化。
五.参考文献
1.gh-ost原理
https://www.cnblogs.com/mysql-dba/p/9901589.html
2.技术分享 | gh-ost 在线 ddl 变更工具
https://zhuanlan.zhihu.com/p/83770402
3.干货 | 携程数据库发布系统演进之路
https://blog.csdn.net/ctrip_tech/article/details/108395676
4.MySQL在线DDL gh-ost 使用说明
https://www.cnblogs.com/zhoujinyi/p/9187421.html
5.MySQL--pt-osc工具学习
https://www.cnblogs.com/TeyGao/p/7160421.html
到此这篇关于MySQL在线DDL工具 gh-ost的文章就介绍到这了,更多相关MySQL在线DDL gh-ost内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 MySQL在线DDL工具 gh-ost的原理解析 的全部内容, 来源链接: utcz.com/p/231075.html