hive从mysql导入数据量变多的解决方案
原始导数命令:
bin/sqoop import -connect jdbc:mysql://192.168.169.128:3306/yubei -username root -password 123456 -table yl_city_mgr_evt_info --split-by rec_id -m 4 --fields-terminated-by "\t" --lines-terminated-by "\n" --hive-import --hive-overwrite -create-hive-table -delete-target-dir -hive-database default -hive-table yl_city_mgr_evt_info
原因分析:可能是mysql中字段里面有'\n'等分隔符,导入hive时默认以'n'作换行符,导致hive中的记录数变多。
解决方法:
导入数据时加上--hive-drop-import-delims选项,会删除字段中的\n,\r,\01。
最终导数命令:
bin/sqoop import -connect jdbc:mysql://192.168.169.128:3306/yubei -username root -password 123456 -table yl_city_mgr_evt_info --split-by rec_id -m 4 --hive-drop-import-delims --fields-terminated-by "\t" --lines-terminated-by "\n" --hive-import --hive-overwrite -create-hive-table -delete-target-dir -hive-database default -hive-table yl_city_mgr_evt_info
参考官方文档:https://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
补充:Sqoop导入MySQL数据到Hive遇到的坑
1.sqoop导入到HDFS
1.1执行sqoop job,会自动更新last value
# sqoop 增量导入脚本
bin/sqoop job --create sqoop_hdfs_test02 -- import \
--connect jdbc:mysql://localhost:3306/pactera_test \
--username root \
--password 123456 \
--table student \
--target-dir /user/sqoop/test002/ \
--fields-terminated-by "\t" \
--check-column last_modified \
--incremental lastmodified \
--last-value "2018-12-12 00:03:00" \
--append
说明:--append 参数是必须的,要不然第二次运行job 会报错,如下:

至此,sqoop job 已建设完毕!
2.Hive创建表,并读取sqoop导入的数据
create external table if not exists student_hive (SId int,Sname string ,Sage string,Ssex string , last_modified Timestamp)
row format delimited fields terminated by '\t' location 'hdfs://node01:8020/user/sqoop/test002/';
注意:此处hive中时间的格式为timestamp,设置为date DB数据无法正常加载。
第一次全量加载,整条路线完全OK,hive表可以查询到数据。
-----------------------重点分割线-----------------------
* sqoop lastmodified格式的增量加载,会将last-value 保存为job执行的系统时间,若测试数据库的check-column 小于当前系统时间(即上一个job的last-value),则数据将不被加载。
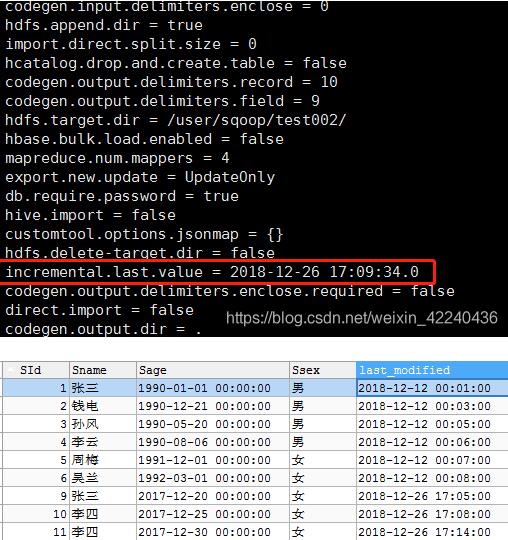
如SId=6 就没有被加载,遂改为今日时间(2018-12-26 17:05)进行数据测试,数据成功被加载!哟呵!!
总结:
使用lastmodified格式,进行sqoop增量导入时,
1.注意--append的使用;
2.last-value为job运行的系统时间,在数据测试时,要保证数据的准确,数据的自增长。
3.一切皆有定数,查看资料,准确定位自己系统遇到的问题
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
以上是 hive从mysql导入数据量变多的解决方案 的全部内容, 来源链接: utcz.com/p/230873.html