php微信公众号开发之校园图书馆
本文实例为大家分享了php微信公众号图书馆的具体代码,供大家参考,具体内容如下
图书来源:山东理工大学图书馆书目检索系统
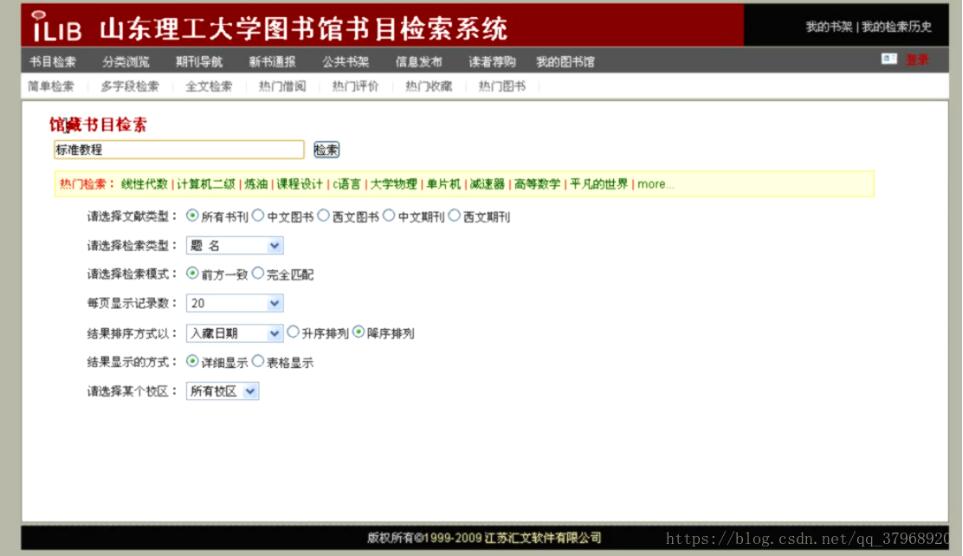
搜索书名返回是xml格式数据:

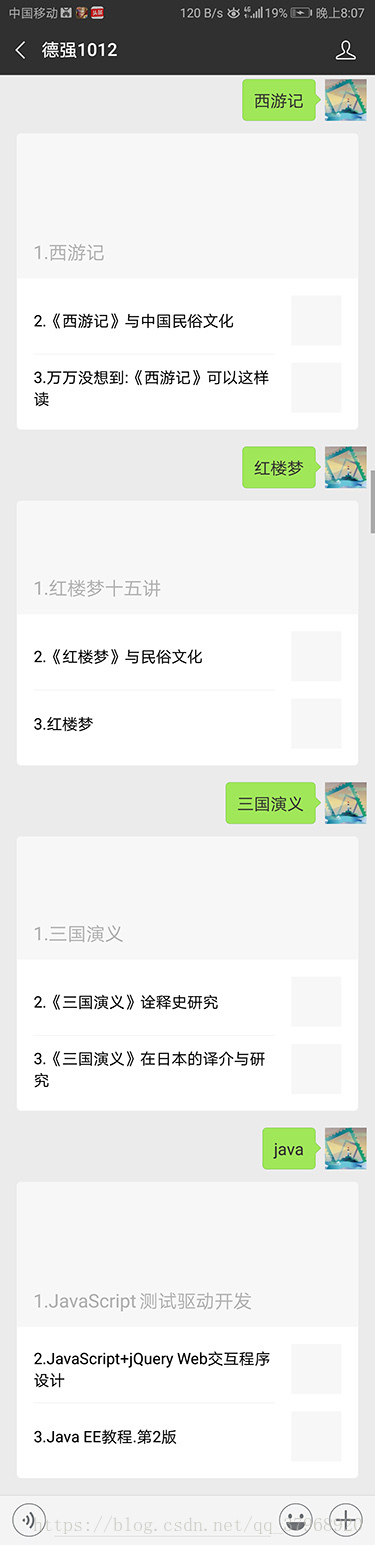
核心代码如下:
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>3</ArticleCount>
<Articles>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[s]]></Description>
<PicUrl><![CDATA[url]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[s]]></Description>
<PicUrl><![CDATA[url]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[s]]></Description>
<PicUrl><![CDATA[url]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
</Articles>
<FuncFlag>1</FuncFlag>
</xml>";
$url="http://222.206.65.12/opac/search_rss.php?dept=ALL&title={$keyword}&doctype=ALL&lang_code=ALL&match_flag=forward&displaypg=20&showmode=list&orderby=DESC&sort=CATA_DATE&onlylendable=no";
$fa=file_get_contents($url);
$f=simplexml_load_string($fa);
$da1=$f->channel->item[0]->title;
$da2=$f->channel->item[1]->title;
$da3=$f->channel->item[2]->title;
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time,$da1,$da2,$da3);
echo $resultStr;
index.php整体代码如下:
<?php
/**
* wechat php test
*/
//define your token
define("TOKEN", "weixin");
$wechatObj = new wechatCallbackapiTest();
$wechatObj->responseMsg();
class wechatCallbackapiTest
{
public function valid()
{
$echoStr = $_GET["echostr"];
//valid signature , option
if($this->checkSignature()){
echo $echoStr;
exit;
}
}
public function responseMsg()
{
//get post data, May be due to the different environments
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
//extract post data
if (!empty($postStr)){
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>3</ArticleCount>
<Articles>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[s]]></Description>
<PicUrl><![CDATA[url]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[s]]></Description>
<PicUrl><![CDATA[url]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[s]]></Description>
<PicUrl><![CDATA[url]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
</Articles>
<FuncFlag>1</FuncFlag>
</xml>";
$url="http://222.206.65.12/opac/search_rss.php?dept=ALL&title={$keyword}&doctype=ALL&lang_code=ALL&match_flag=forward&displaypg=20&showmode=list&orderby=DESC&sort=CATA_DATE&onlylendable=no";
$fa=file_get_contents($url);
$f=simplexml_load_string($fa);
$da1=$f->channel->item[0]->title;
$da2=$f->channel->item[1]->title;
$da3=$f->channel->item[2]->title;
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time,$da1,$da2,$da3);
echo $resultStr;
}else {
echo "";
exit;
}
}
private function checkSignature()
{
$signature = $_GET["signature"];
$timestamp = $_GET["timestamp"];
$nonce = $_GET["nonce"];
$token = TOKEN;
$tmpArr = array($token, $timestamp, $nonce);
sort($tmpArr);
$tmpStr = implode( $tmpArr );
$tmpStr = sha1( $tmpStr );
if( $tmpStr == $signature ){
return true;
}else{
return false;
}
}
}
?>
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
以上是 php微信公众号开发之校园图书馆 的全部内容, 来源链接: utcz.com/p/222304.html