react自动化构建路由的实现
序
在使用react-router-dom在编写项目的时候有种感觉就是,使用起来非常的方便,但是若是维护起来,那便是比较麻烦了,因为各大路由分散在各个组件中. 所以我们就会想到,使用react-router-dom中提供的config模式来编写我们的路由,这样写的好处就是我们可以将逻辑集中在一处,配置路由比较方便
项目地址
https://gitee.com/d718781500/autoRouter
1.路由集中式
我们先将下列数据定义在/src/router/index.js中
在react的路由官方文档中就提供了配置集中式路由的案例,大致是这样的仿照vue的路由,生成一个配置文件,预期是这样的
//需要一个路由的配置,它是一个数组
import Discover from "../pages/Discover"
import Djradio from "../pages/Discover/Djradio"
import Playlist from "../pages/Discover/Playlist"
import Toplist from "../pages/Discover/Toplist"
import Friends from "../pages/Friends"
import Mine from "../pages/Mine"
import Page404 from "../pages/Page404"
const routes = [
{
path: "/friends",
component: Friends
},
{
path: "/mine",
component: Mine
},
{
path: "/discover",
component: Discover,
children: [
{
path: "/discover/djradio",
component: Djradio
},
{
path: "/discover/playlist",
component: Playlist
},
{
path: "/discover/toplist",
component: Toplist
}
]
},
{//Page404这个配置一定要在所有路由配置之后
path: "*",
component: Page404
}
]
export default routes
我们可以通过上述配置,来生成一个路由.当然上述的配置也只是做了简单的处理,还有redirect exact等属性没有写,我们还是从一个简单的开始吧
2.文件目录
上述的配置中使用了类似于vue的集中式路由配置模式,那么下面就展示下我当前这个demo的结构目录吧
项目目录结构
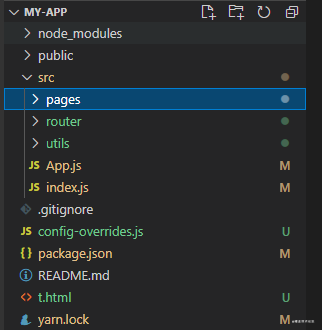
src/pages目录结构
├─Discover
│ │ abc.js
│ │ index.js
│ │
│ ├─Djradio
│ │ │ index.js
│ │ │ lf.js
│ │ │
│ │ └─gv
│ │ index.js
│ │
│ ├─Playlist
│ │ index.js
│ │
│ └─Toplist
│ index.js
│
├─Entertaiment
│ index.js
│
├─Friends
│ index.js
│ xb.js
│
├─Mine
│ index.js
│
└─Page404
index.js
有了这些结构之后,那么在1中提到的引入文件结合起来看就不懵逼啦,接下来我们可以封装一个组件,给他取个名字叫做CompileRouter这个组件专门用于编译路由
3.创建CompileRouter
这个组件我们把它创建在src/utils中,作用就是通过传入的路由配置,然后计算出这个组件,那么问题来了,为什么要创建这个组件呢?
让我们回顾一下react路由的编写方式吧,react路由需要一个基础组件HashRouter或者BrowserRouter这两个相当于一个基石组件
然后还需要一个路由配方这个组件可以接受一个path映射一个component
我们来写段伪代码来说明一下
//引入路由基本组件(要在项目中安装 npm i react-router-dom)
import {HashRouter as Router,Route} from "react-router-dom"
class Demo extends React.Component {
render(){
//基石路由
<Router>
//路由配方组件 通过path匹配component
<Route path="/" component={Home}/>
<Route path="/mine" component={Mine}/>
</Router>
}
}
这是基本用法,所以我们CompileRouter这个组件的工作就是,生成如上代码中的Route一样,生成Route然后展示在组件上
在了解到Compile的基本作用之后,下面我们就开始编码吧
我个CompileRouter设计是接受一个数据,这个数据必须是符合路由配置的一个数组,就像1里代码中所示的数组一样,接受的属性为routes
//这个文件通过routes配置来编译出路由
import React from 'react'
import { Switch, Route } from "react-router-dom";
export default class CompileRouter extends React.Component {
constructor() {
super()
this.state = {
c: []
}
}
renderRoute() {
let { routes } = this.props;//获取routes路由配置
//1.通过routes生成Route组件
//确保routes是一个数组
// console.log(routes)
//render 不会重复让组件的componentDidMount和componentWillUnmount重复调用
if (Array.isArray(routes) && routes.length > 0) {
//确保传入的routes是个数组
// 循环迭代传入的routes
let finalRoutes = routes.map(route => {
//每个route是这个样子的 {path:"xxx",component:"xxx"}
//如果route有子节点 {path:"xxx",component:"xxx",children:[{path:"xxx"}]}
return <Route path={route.path} key={route.path} render={
// 这么写的作用就是,如果路由还有嵌套路由,那么我们可以把route中的children中的配置数据传递给这个组件,让组件再次调用CompileRouter的时候就能编译出嵌套路由了
() => <route.component routes={route.children} />
} />
})
this.setState({
c: finalRoutes
})
} else {
throw new Error('routes必须是一个数组,并且长度要大于0')
}
}
componentDidMount() {
//确保首次调用renderRoute计算出Route组件
this.renderRoute()
}
render() {
let { c } = this.state;
return (
<Switch>
{c}
</Switch>
)
}
}
上述代码就是用于去处理routes数据并且声称这样的组件,每一步的作用我都已经在上面用注释标明了
4.使用CompileRouter
其实我们可以把封装的这个组件当成是vue-router中的视图组件<router-view/>就暂且先这么认为吧,接下来我们需要在页面上渲染1级路由了
在src/app.js
import React from 'react'
import { HashRouter as Router, Link } from 'react-router-dom'
//引入我们封装的CompileRouter罪案
import CompileRouter from "./utils/compileRouter"
//引入在1中定义的路由配置数据
import routes from "./router"
console.log(routes)
class App extends React.Component {
render() {
return (
<Router>
<Link to="/friends">朋友</Link>
|
<Link to="/discover">发现</Link>
|
<Link to="/mine">我的</Link>
{/*当成是vue-router的视图组件 我们需要将路由配置数据传入*/}
<CompileRouter routes={routes} />
</Router>
)
}
}
export default App
写完后,那么页面上其实就可以完美的展示1级路由了
5.嵌套路由处理
上面我们已经对1级路由进行了渲染,可以跳转,但是二级路由怎么处理呢?其实也很简单,我们只需要找到二级路由的父路由,继续使用CompileRouter就可以了
我们从配置中可以看到,Discover这个路由是具有嵌套路由的,所以我们就以Discover路由为例子,首先我们看下结构图
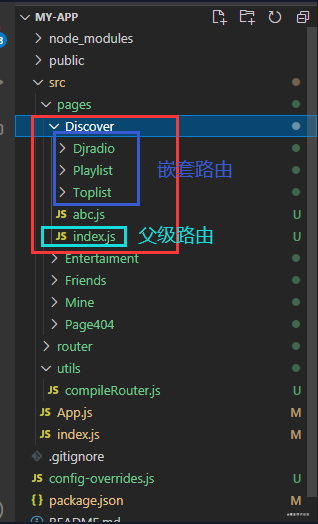
图上的index.js就是Discover这个视图组件了,也是嵌套路由的父级路由,所以我们只需要在这个index.js中继续使用CompileRouter就可以了
import React from 'react'
import { Link } from "react-router-dom"
import CompileRouter from "../../utils/compileRouter"
function Discover(props) {
let { routes } = props //这个数据是从ComileRouter组件编译的时候传递过来的children
// console.log(routes)
let links = routes.map(route => {
return (
<li key={route.path}>
<Link to={route.path}>{route.path}</Link>
</li>
)
})
return (
<fieldset>
<legend>发现</legend>
<h1>我发现,不能说多喝热水</h1>
<ul>
{links}
</ul>
{/*核心代码,再次使用即可 这里将通过children数据可以渲染出Route*/}
<CompileRouter routes={routes} />
</fieldset>
)
}
Discover.meta = {
title: "发现",
icon: ""
}
export default Discover
所以我们以后记住,只要是有嵌套路由我们要做两件事
- 配置routes
- 在嵌套路由的父级路由中再次使用CompileRouter,并且传入routes即可
6. require.context
上面我们实现了一个路由集中式的配置,但是我们会发现一个问题
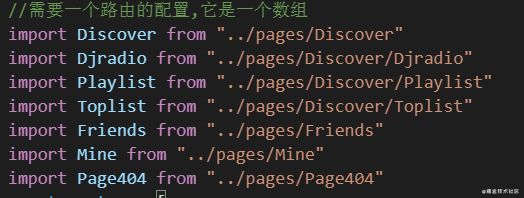
引入了很多的组件,实际上,在项目中引入的更多,如果一个一个引入,对我们来说是灾难性的,所以我们可以使用webpack提供的一个很好用的api,require.context我们先说说它是怎么使用的吧
自动化导入require.context方法,使用这个方法可以减少繁琐的组件引入,而且可以深度的递归目录,做到import做不到的事情 下面我们来看一下这个方法是如何使用的
使用
你可以通过 require.context() 函数来创建自己的 context。
可以给这个函数传入4个参数:
- 一个要搜索的目录,
- 一个标记表示是否还要搜索其子目录,
- 一个匹配文件的正则表达式。
- mode 模块加载模式,常用值为 sync、lazy、lazy-once、eager
- sync 直接打包到当前文件,同步加载并执行
- lazy 延迟加载会分离出单独的 chunk 文件
- lazy-once 延迟加载会分离出单独的 chunk 文件,加载过下次再加载直接读取内存里的代码。
- eager 不会分离出单独的 chunk 文件,但是会返回 promise,只有调用了 promise 才会执行代码,可以理解为先加载了代码,但是我们可以控制延迟执行这部分代码。
webpack 会在构建中解析代码中的 require.context() 。
语法如下:
require.context(
directory,
(useSubdirectories = true),
(regExp = /^\.\/.*$/),
(mode = 'sync')
);
示例:
require.context('./test', false, /\.test\.js$/);
//(创建出)一个 context,其中文件来自 test 目录,request 以 `.test.js` 结尾。
require.context('../', true, /\.stories\.js$/);
// (创建出)一个 context,其中所有文件都来自父文件夹及其所有子级文件夹,request 以 `.stories.js` 结尾。
api
函数有三个属性:resolve, keys, id。
resolve 是一个函数,它返回 request 被解析后得到的模块 id。
let p = require.context("...",true,"xxx")
p.resolve("一个路径")
keys 也是一个函数,它返回一个数组,由所有可能被此 context module 处理的请求(译者注:参考下面第二段代码中的 key)组成。
require.context的返回值是一个函数,我们可以在函数中传入文件的路径,就可以得到模块化的组件了
let components = require.context('../pages', true, /\.js$/, 'sync')
let paths = components.keys()//获得了所有引入文件的地址
// console.log(paths)
let routes = paths.map(path => {
let component = components(path).default
path = path.substr(1).replace(/\/\w+\.js$/,"")
return {
path,
component
}
})
console.log(routes)
总结
虽然上面有很多api和返回的值,我们只拿两个来做说明
keys方法,这个可以获取所有模块的路径,返回的是一个数组
let context = require.context("../pages", true, /\.js$/);
let paths = context.keys()//获取了所有文件的路径
获取路径下所有的模块
let context = require.context("../pages", true, /\.js$/);
let paths = context.keys()//获取了所有文件的路径
let routes = paths.map(path => {
//批量获取引入的组件
let component = context(path).default;
console.log(component)
})
掌握这两个就可以了,下面我们来继续处理
7.扁平数据转换为树形结构的(convertTree算法)
这个算法的名字是我自己起的,首先我们要明白为甚么需要将数据转换成tree
我们的预期的routes数据应该是下面这样的
//目的是什么?
//生成一个路由配置
const routes = [
{
path: "",
component:xxx
children:[
{
path:"xxx"
component:xxx
}
]
}
]
但其实我们使用require.context处理之后的数据是这样的

可以看到这个数据是完全扁平化的,没有任何的嵌套,所以我们第一步就是要实现将这种扁平化的数据转换为符合我们预期的树形结构,下面我们一步一步来
7.1使用require.context将数据处理成扁平化
首先要处理成上图那样的结构,代码都有注释,难度也不高
//require.context()
// 1. 一个要搜索的目录,
// 2. 一个标记表示是否还要搜索其子目录,
// 3. 一个匹配文件的正则表达式。
let context = require.context("../pages", true, /\.js$/);
let paths = context.keys()//获取了所有文件的路径
let routes = paths.map(path => {
//批量获取引入的组件
let component = context(path).default;
//组件扩展属性方便渲染菜单
let meta = component['meta'] || {}
//console.log(path)
//这个正则的目的
//因为地址是./Discover/Djradio/index.js这种类型的并不能直接使用,所以要进行处理
//1.接去掉最前的"." 得到的结果是/Discover/Djradio/index.js
//2.处理了还是不能直接用 因为我们的预期/Discover/Djradio,所以通过正则将index.js干掉了
//3.有可能后面的路径不是文件夹 得到的结果是/Discover/abc.js,后缀名并不能用到路由配置的path属性中,所以.js后缀名又用正则替换掉
path = path.substr(1).replace(/(\/index\.js|\.js)$/, "")
// console.log(path)
return {
path,
component,
meta
}
})
7.2 实现convertTree算法
上面处理好了数据后,我们封装一个方法,专门用于处理扁平化数据变成树形数据,算法时间复杂度为O(n^2)
function convertTree(routes) {
let treeArr = [];
//1.处理数据 将每条数据的id和parent处理好 (俗称 爸爸去哪儿了)
routes.forEach(route => {
let comparePaths = route.path.substr(1).split("/")
// console.log(comparePaths)
if (comparePaths.length === 1) {
//说明是根节点,根节点不需要添加parent_id
route.id = comparePaths.join("")
} else {
//说明具有父节点
//先处理自己的id
route.id = comparePaths.join("");
//comparePaths除去最后一项就是parent_id
comparePaths.pop()
route.parent_id = comparePaths.join("")
}
})
//2.所有的数据都已经找到了父节点的id,下面才是真正的找父节点了
routes.forEach(route => {
//判断当前的route有没有parent_id
if (route.parent_id) {
//有父节点
//id===parent_id的那个route就是当前route的父节点
let target = routes.find(v => v.id === route.parent_id);
//判断父节点有没有children这个属性
if (!target.children) {
target.children = []
}
target.children.push(route)
} else {
treeArr.push(route)
}
})
return treeArr
}
通过上述处理之后就可以得到树形结构啦
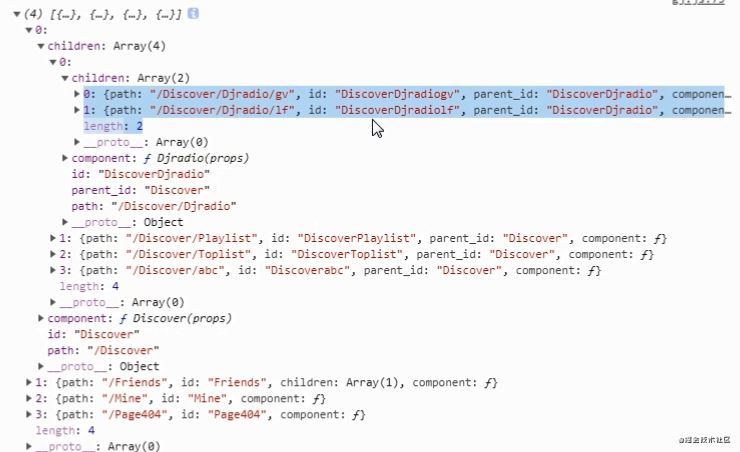
接下来我们只需要把数据导出去,在app上引入传递给CompileRouter组件就可以了
7.3 以后要注意的
以后只需要在pages中创建文件即可自动实现路由的处理以及编译了,不过对于嵌套级别的路由咱们别忘了要在路由组件加上CompileRouter组件,总结为亮点
- 创建路由页面
- 嵌套路由的父级路由组件中加入
8.扩展静态属性
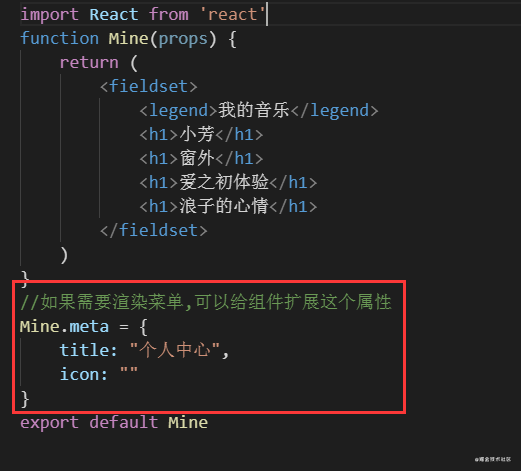
我们当前创建出来的效果是有了,但是如果我们用于渲染菜单的时候就会有问题,没有内容可以用于渲染菜单,所以我们可以给组件上扩展静态属性meta(也可以是别的),然后对我们的自动化编译代码做一些小小的改动就行了
组件
自动化处理逻辑完整代码
//require.context()
// 1. 一个要搜索的目录,
// 2. 一个标记表示是否还要搜索其子目录,
// 3. 一个匹配文件的正则表达式。
let context = require.context("../pages", true, /\.js$/);
let paths = context.keys()//获取了所有文件的路径
let routes = paths.map(path => {
//批量获取引入的组件
let component = context(path).default;
//组件扩展属性方便渲染菜单
let meta = component['meta'] || {}
//console.log(path)
//这个正则的目的
//因为地址是./Discover/Djradio/index.js这种类型的并不能直接使用,所以要进行处理
//1.接去掉最前的"." 得到的结果是/Discover/Djradio/index.js
//2.处理了还是不能直接用 因为我们的预期/Discover/Djradio,所以通过正则将index.js干掉了
//3.有可能后面的路径不是文件夹 得到的结果是/Discover/abc.js,后缀名并不能用到路由配置的path属性中,所以.js后缀名又用正则替换掉
path = path.substr(1).replace(/(\/index\.js|\.js)$/, "")
// console.log(path)
return {
path,
component,
meta
}
})
//这种数据是扁平化的数据,并不符合我们的路由规则
//需要做算法 尽可能将时间复杂度降低o(n)最好
//封装一个convertTree算法 时间复杂度o(n^2)
// console.log(routes)
//id
//parent_id
function convertTree(routes) {
let treeArr = [];
//1.处理数据 将每条数据的id和parent处理好 (俗称 爸爸去哪儿了)
routes.forEach(route => {
let comparePaths = route.path.substr(1).split("/")
// console.log(comparePaths)
if (comparePaths.length === 1) {
//说明是根节点,根节点不需要添加parent_id
route.id = comparePaths.join("")
} else {
//说明具有父节点
//先处理自己的id
route.id = comparePaths.join("");
//comparePaths除去最后一项就是parent_id
comparePaths.pop()
route.parent_id = comparePaths.join("")
}
})
//2.所有的数据都已经找到了父节点的id,下面才是真正的找父节点了
routes.forEach(route => {
//判断当前的route有没有parent_id
if (route.parent_id) {
//有父节点
//id===parent_id的那个route就是当前route的父节点
let target = routes.find(v => v.id === route.parent_id);
//判断父节点有没有children这个属性
if (!target.children) {
target.children = []
}
target.children.push(route)
} else {
treeArr.push(route)
}
})
return treeArr
}
export default convertTree(routes)
//获取一个模块
// console.log(p("./Discover/index.js").default)
//目的是什么?
//生成一个路由配置
// const routes = [
// {
// path: "",
// component,
// children:[
// {path component}
// ]
// }
// ]
写在最后
其实上述的处理并不能作为应用级别用于项目中,主要在于CompileRouter处理的不够细致,下一期我将专门写一篇如何处理CompileRouter用于鉴权等应用在项目中
到此这篇关于react自动化构建路由的实现的文章就介绍到这了,更多相关react自动化构建路由内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 react自动化构建路由的实现 的全部内容, 来源链接: utcz.com/p/220097.html