Python3调用百度OCR图片文字识别API
最近做了个小项目,中间需要用到图片文字识别,使用了百度的接口,这里分享下代码相关代码。
注意:SECRET_KEY和 API_KEY 需要自己去免费申请,有相应的免费额度,具体可以参考官方文档:ai.baidu.com/ai-doc/OCR/dk3iqnq51
# -*- coding: utf-8-*-# @Author: bgods.cn
# @Create Date:2020-07-2217:08
# @File Name: api.py
# @Description: 图片转文字API
import base64
import requests
API_KEY='*********' # 自行获取
SECRET_KEY='************' # 自行获取
OCR_URL="https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" # OCR接口
TOKEN_URL='https://aip.baidubce.com/oauth/2.0/token' # TOKEN获取接口
def fetch_token():
# 获取token
params ={'grant_type':'client_credentials',
'client_id':API_KEY,
'client_secret':SECRET_KEY}
try:
f = requests.post(TOKEN_URL, params, timeout=5)
if f.status_code ==200:
result = f.json()
if'access_token'in result.keys() and 'scope'in result.keys():
if not 'brain_all_scope'in result['scope'].split(' '):
return None,'please ensure has check the ability'
return result['access_token'],''
else:
return None,'请输入正确的 API_KEY 和 SECRET_KEY'
else:
return None,'请求token失败: code {}'.format(f.status_code)
except BaseException as err:
return None,'请求token失败: {}'.format(err)
def read_file(image_path):
f = None
try:
f =open(image_path,'rb') # 二进制读取图片信息
return f.read(),''
except BaseException as e:
return None,'文件({0})读取失败: {1}'.format(image_path, e)
finally:
if f:
f.close()
def pic2text(img_path):
def request_orc(img_base, token):
"""
调用百度OCR接口,图片识别文字
:param img_base: 图片的base64转码后的字符
:param token: fetch_token返回的token
:return: 返回一个识别后的文本字典
"""
try:
req = requests.post(
OCR_URL+"?access_token="+ token,
data={'image': img_base},
headers={'Content-Type':'application/x-www-form-urlencoded'}
)
if req.status_code ==200:
result = req.json()
if'words_result'in result.keys():
return req.json()["words_result"],''
elif 'error_msg'in result.keys():
return None,'图片识别失败: {}'.format(req.json()["error_msg"])
else:
return None,'图片识别失败: code {}'.format(req.status_code)
except BaseException as err:
return None,'图片识别失败: {}'.format(err)
file_content, file_error =read_file(img_path)
if file_content:
token, token_err =fetch_token()
if token:
results, result_err =request_orc(base64.b64encode(file_content), token)
if result_err: # 打印失败信息
print(result_err)
for result in results: # 打印处理结果
print(result)
if __name__ =='__main__':
pic2text(img_path='图片文字识别.jpg')
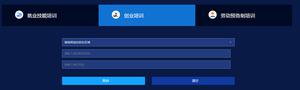
源图片:

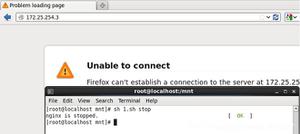
识别效果如下:

以上是 Python3调用百度OCR图片文字识别API 的全部内容, 来源链接: utcz.com/p/217063.html