Java实现读取文章中重复出现的中文字符串
在上个星期阿里巴巴一面的时候,最后面试官问我如何把一篇文章中重复出现的词或者句子找出来,当时太紧张,答的不是很好。今天有时间再来亲手实现一遍。其实说白了也就是字符串的处理,所以难度并不是很大。
以下是代码和运行效果:
实现方法:
import java.io.*;
import java.util.*;
/**
* Created by chunmiao on 17-3-20.
*/
public class ReadArticle {
//读取文件名称
private String filename;
//读取段落
private ArrayList<String> result = new ArrayList<>();
//最小字长(两个字以上进行匹配)
private final int MINSIZE = 2;
//重复词储存
HashSet<String> set;
public ReadArticle(String filename, HashSet<String> set) {
this.filename = filename;
this.set = set;
}
public void createData() throws IOException {
String r;
//读取文章内容
BufferedReader in = new BufferedReader(new FileReader(new File(filename).getAbsoluteFile()));
try {
while ((r = in.readLine()) != null) {
//消除不必要的标点符号
r = r.replaceAll("\\s+ |“|\\[|‘|《| *|", "").trim();
//留下” , 。 。” ”。 ”, ? 》 -等作为划分句子的分割符标示
Collections.addAll(result, r.split(",|(。”|”(。|,)|。)|(\\])|”|'|?|:|》|-"));
}
}finally {
in.close();
}
//对文章内容进行遍历找出重读出现的句子或者是词语
for (int i = 0 ; i < result.size() - 1; i ++){
for (int j = 0 ; j < result.size() - i - 1; j ++) {
//将重复出现的词语保存到set集合里面
set.addAll(getSameCharacter(result.get(i), result.get(j + i + 1)));
}
}
}
private ArrayList<String> getSameCharacter(String a1, String a2){
String maxS;
String minS;
//短句遍历开始处
int start = 0;
//词的长度最短为两个字长
int range =2;
//设定短句和长句s,使得遍历更加快捷
if (a1.length() <= a2.length()){
maxS = a2;
minS = a1;
}else {
maxS = a1;
minS = a2;
}
String result = "";
ArrayList<String> list = new ArrayList<String>();
//防止substring时超出范围
while (start + range <= minS.length()) {
//如果句子或词在对象里面,则找出相应的句子或词保存在list里面
if (maxS.indexOf(minS.substring(start, start + range)) != -1) {
//获取最长句子,删除短句子
list.remove(result);
list.add(minS.substring(start, start + range));
result = minS.substring(start, start + range);
range++;
continue;
}
range = MINSIZE;
start++;
}
return list;
}
}
测试代码:
import java.io.IOException;
import java.util.HashSet;
public class Main {
public static void main(String[] args) throws IOException {
String filename = "test.txt";
HashSet<String> result = new HashSet<String>();
ReadArticle read = new ReadArticle(filename,result);
read.createData();
System.out.println("这篇文章中的重复出现的词或句子有以下几个词或句子:\n");
for (String s : result){
System.out.println(s);
}
}
}
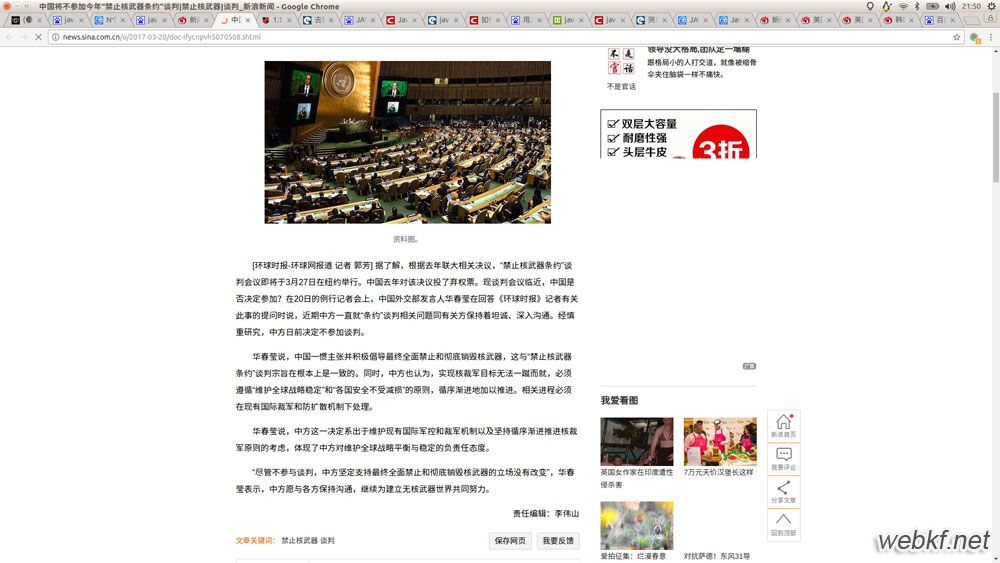
读取的文章内容:
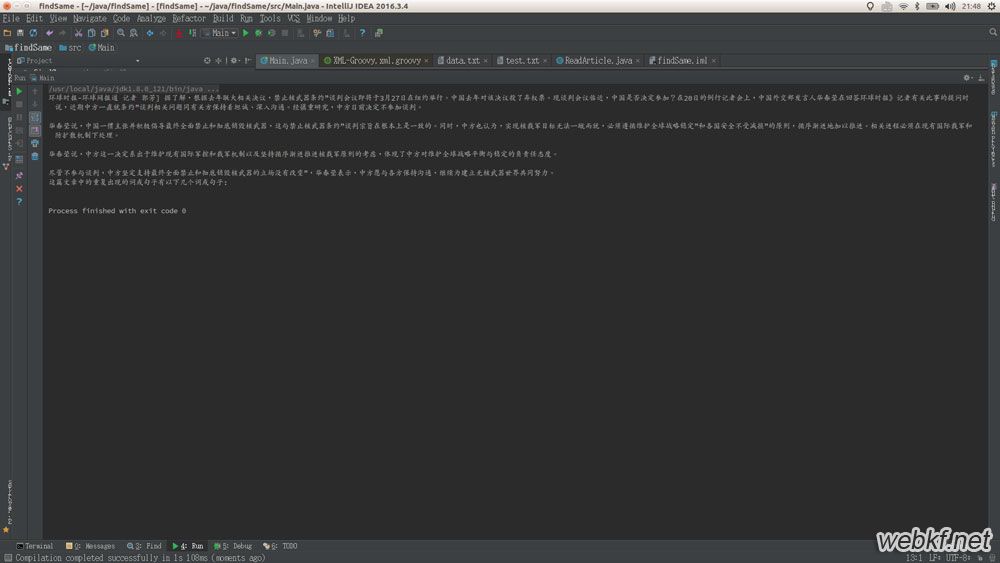
正则匹配结果(去掉多余字符):
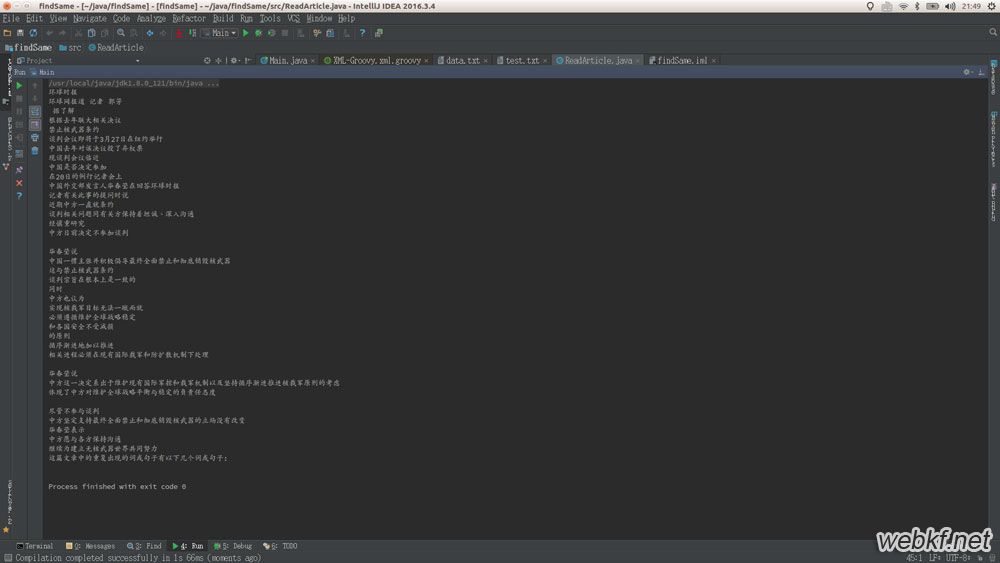
字符串转换成ArrayList:
最终处理结果:
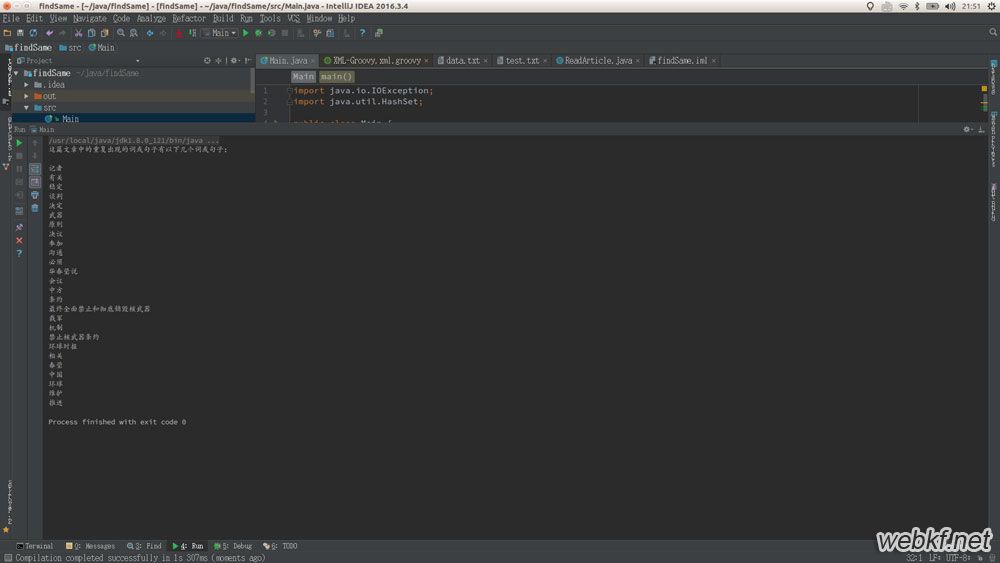
其实从上面的结果可以看出。单纯的操控字符串并不能判断它是否是一个完整的词和句,应该还要配合数据库字典来匹配上面的结果,从而找出真正的词和句
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持!
以上是 Java实现读取文章中重复出现的中文字符串 的全部内容, 来源链接: utcz.com/p/213354.html