java实现爬取知乎用户基本信息
本文实例为大家分享了一个基于JAVA的知乎爬虫,抓取知乎用户基本信息,基于HttpClient 4.5,供大家参考,具体内容如下
详细内容:
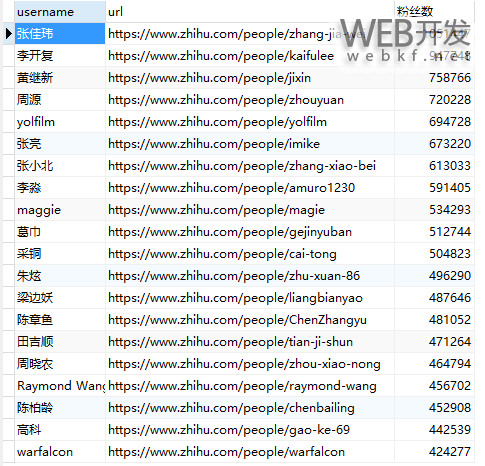
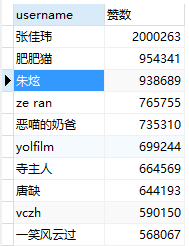
抓取90W+用户信息(基本上活跃的用户都在里面)
大致思路:
1.首先模拟登录知乎,登录成功后将Cookie序列化到磁盘,不用以后每次都登录(如果不模拟登录,可以直接从浏览器塞入Cookie也是可以的)。
2.创建两个线程池和一个Storage。一个抓取网页线程池,负责执行request请求,并返回网页内容,存到Storage中。另一个是解析网页线程池,负责从Storage中取出网页内容并解析,解析用户资料存入数据库,解析该用户关注的人的首页,将该地址请求又加入抓取网页线程池。一直循环下去。
3.关于url去重,我是直接将访问过的链接md5化后存入数据库,每次访问前,查看数据库中是否存在该链接。
到目前为止,抓了100W用户了,访问过的链接220W+。现在抓取的用户都是一些不太活跃的用户了。比较活跃的用户应该基本上也抓完了。
项目地址:https://github.com/wycm/mycrawler
实现代码:
作者:卧颜沉默
链接:https://www.zhihu.com/question/36909173/answer/97643000
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
/**
*
* @param httpClient Http客户端
* @param context Http上下文
* @return
*/
public boolean login(CloseableHttpClient httpClient, HttpClientContext context){
String yzm = null;
String loginState = null;
HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin");
HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false);
HttpPost request = new HttpPost("https://www.zhihu.com/login/email");
List<NameValuePair> formParams = new ArrayList<NameValuePair>();
yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login");//肉眼识别验证码
formParams.add(new BasicNameValuePair("captcha", yzm));
formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用
formParams.add(new BasicNameValuePair("email", "邮箱"));
formParams.add(new BasicNameValuePair("password", "密码"));
formParams.add(new BasicNameValuePair("remember_me", "true"));
UrlEncodedFormEntity entity = null;
try {
entity = new UrlEncodedFormEntity(formParams, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
request.setEntity(entity);
loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录
JSONObject jo = new JSONObject(loginState);
if(jo.get("r").toString().equals("0")){
System.out.println("登录成功");
getRequest = new HttpGet("https://www.zhihu.com");
HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页
HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录
return true;
}else{
System.out.println("登录失败" + loginState);
return false;
}
}
/**
* 肉眼识别验证码
* @param httpClient Http客户端
* @param context Http上下文
* @param url 验证码地址
* @return
*/
public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){
HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true);
Scanner sc = new Scanner(System.in);
String yzm = sc.nextLine();
return yzm;
}
效果图:
以上就是本文的全部内容,希望对大家的学习有所帮助。
以上是 java实现爬取知乎用户基本信息 的全部内容, 来源链接: utcz.com/p/209618.html