快速排序的深入详解以及java实现
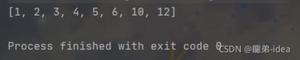
快速排序作为一种高效的排序算法被广泛应用,SUN的JDK中的Arrays.sort 方法用的就是快排。快排采用了经典的分治思想(divide and conquer):Divide:选取一个基元X(一般选取数组第一个元素),通过某种分区操作(partitioning)将数组划分为两个部分:左半部分小于等于X,右半部分大于等于X。Conquer: 左右两个子数组递归地调用Divide过程。Combine:快排作为就地排序算法(in place sort),不需要任何合并操作可以看出快排的核心部分就是划分过程(partitioning),下面以一个实例来详细解释如何划分数组(图取自于《算法导论》)初始化:选取基元P=2,就是数组首元素。i=1,j=i+1=2 (数组下标以1开头)循环不变量:2~i之间的元素都小于或等于P,i+1~j之间的元素都大于或等于P循环过程:j从2到n,考察j位置的元素,如果大于等于P,就继续循环。如果小于P,就将j位置的元素(不应该出现在i+1~j这个区间)和i+1位置(交换之后仍在i+1~j区间)的元素交换位置,同时将i+1.这样就维持了循环不变量(见上述循环不变量说明)。直到j=n,完成最后一次循环操作。要注意的是在完成循环后,还需要将i位置的元素和数组首元素交换以满足我们最先设定的要求(对应图中的第i步)。细心的读者可能会想到另一种更直白的分区方法,即将基元取出存在另一相同大小数组中,遇到比基元小的元素就存储在数组左半部分,遇到比基元大的元素就存储在数组右半部分。这样的操作复杂度也是线性的,即Theta(n)。但是空间复杂度提高了一倍。这也是快排就地排序的优势所在。
以上是 快速排序的深入详解以及java实现 的全部内容, 来源链接: utcz.com/p/207723.html