深入理解Java中的字符串类型
1.Java内置对字符串的支持; 所谓的内置支持,即不用像C语言通过char指针实现字符串类型,并且Java的字符串编码是符合Unicode编码标准,这也意味着不用像C++那样通过使用string和wstring类实现与C语言兼容和Unicode标准。Java内部通过String类实现对字符串类型的支持。这意味着:我们可以直接对字符串常量调用和String对象同样的方法:
//可以再"abc"上直接调用String对象的所有方法 int length="abc".length(); 以及 String abc=new String("abc"); int length=abc.length();
2.Java中的字符串值是constant(常量的)
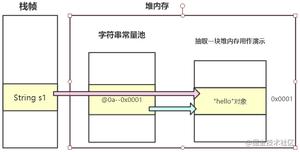
这里的意思是字符串类型在创建完成之后,是不能改变其中的值的,从String的成员方法也可以看出没有能改变值的方法接口;并且像"abc",new String("def")中的”abc","def"存放于Java虚拟机中的常量池。
以下的代码中的"abc"存放于常量池中,因此变量a,ab指向的地址均为常量池中同一个"abc"。
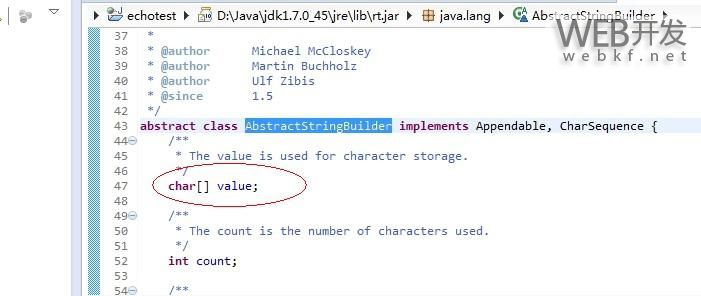
那么动态生成的、可变的字符串又是如何实现的呢?Java中提供StringBuffer和StringBuilder类实现这一需求;Java中字符串连接可以使用“+”操作符; 如:"abc"+"def";这里的内部实现也可以使用StringBuilder类或者StringBuffer类实现;那么StringBuilder和StringBuffer内部又是如何实现呢?是通过字符数组存储字符串。以下是从JDK附带的源码中找到的片段,可以看出StringBuffer内部使用char数组对字符串进行存储,其中的AbstractStringBuilder是StringBuffer的父类:
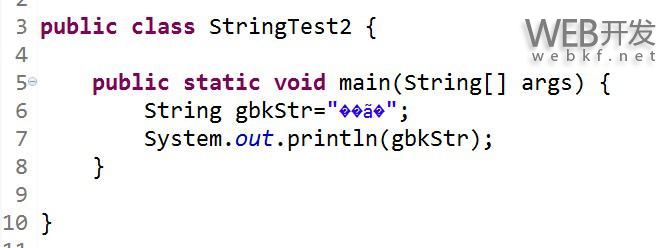
3.字符串中的编码问题。 这里要理解两个问题:如何处理源文件中的字符串编码?编译成class文件或者是代码在Java虚拟机运行时字符串是采用什么编码的? 第一个问题的理解是:源代码中的字符串编码取决于你的IDE或者文本编辑器。如以下的代码是使用GBK编码格式下编辑,然后使用UTF-8和GBK解码打开//GBK编码格式,使用GBK格式打开

//GBK编码格式,使用UTF-8格式打开,乱码;如果此时系统默认的编码格式不是GBK时,在编译时需要在javac加入"-encoding GBK"参数选项值;
那么如何处理这种源代码编码的问题呢?答案是在编译器javac的参数选项-encoding中指定,默认这一参数的值是跟系统默认的编码一致。Windows的默认编码一般为GBK (可以通过System.getProperty("file.encoding")获得该值);在系统默认编码为GBK,但是源代码使用UTF-8编码,此时应该使用 javac -encoding UTF-8 进行编译。
对 ”编译成class文件或者是代码在Java虚拟机运行时字符串是采用什么编码的?“ 这个问题的理解是:首先,Java中的String类型是采用UTF-16编码实现的,也就是不管在源码的编码如何,在Java虚拟机中的字符串都是使用UTF-16编码实现。这意味着只要编译器javac正确的理解了源码文件中字符串的编码,运行时或者class字节码文件中的字符串是独立于源码中的编码格式的。这里我们可以进一步对java中的char基本类型或者Character类进行理解解,这两者内部的编码和java的字符串类型一样,都是基于UTF-16编码实现的,也就是不论‘a','1'这样的字符还是汉字在Java中的长度都是16位。
并且在String类型中也有着通过指定定字符编码,对底层二进制表示和字符串之间进行转化,也就意味着我们可以正确地读取GBK编码、UTF-8编码或者其他编码的文本文件或者其他输入流将其转化为内存中正确的字符串。
如String类中有如下的方法: public String(byte[] bytes, Charset charset);通过指定定字符集编码类型,和相应的byte数组(byte长度为8位)构造字符串; public byte[] getBytes(Charset charset);指定字符集编码类型,将字符串转化为byte数组,即字符串的二进制表示。
还有需要注意String的另一个成员方法:
public byte[] getBytes();这个方法返回的byte数组,所根据的字符集编码是指平台默认的字符集编码,而不一定是UTF-16。
以上是 深入理解Java中的字符串类型 的全部内容, 来源链接: utcz.com/p/207057.html