J2SE 6 在国际化方面的增强
对国际化和本地化的支持是Java 标准版一个长处。 Java SE 6 一如既往地为那些注重本地化资源访问和操作的应用程序开发者提供支持。Java SE 6在以下几方面为本地化作了加强: .资源的访问和控制 .针对本地化的服务 .归一化文本 .国际域名 .日本国的日历 .新增locales 资源访问和控制---------------- 编程人员用 java.util.ResourceBundle 类中提供的方法来为应用程序提供本地化资源。使用这个类中的静态方法 getBundle 来定位以及装载本地化资源,调用后得到ResourceBundle 的实例,那么这个实例就表征了要被使用的本地化了的文本,图片以及其他针对本地化的资源。locale 是由语言和地理区域的不同而形成的文化标志。 尽管在缺省方式下,定位和装载资源绑定已经为我们做了很多工作,Java SE 6 版本里还提供缓存以及让编程人员能对本地化资源进行更好地操纵。我们仍然使用 ResourceBundle类获取本地化的资源,但是Java SE 6 新增加的功能让编程人员能更灵活地来为应用程序的本地化资源内容决定如何存储以及怎样存储。 Java SE 6 先前的版本中,编程人员通常是用属性文件(properies)和 ListResourceBundle的一个子类来存储本地化资源。现在,编程人员可以为资源文件指定不同的格式了。举例来说,使用基于 XML 格式的资源文件,编程人员也可能改动本地化资源文件的缺省命名规范,像这样的特定是 ResourceBundle.Control 类来做工作。 ResourceBundle.Control 类负责资源装载过程中的主要步骤,每个步骤对应类中的一个独立的方法。通过覆盖这些方法来定制策略,以期对资源实现特殊定位,装载和缓存。Control类里定义的方法是实现现有的缺省策略,所以子类化来实现特定的功能。在Control的子类里的 getBundle 方法里定制你自己的功能,甚至能自己决定如何让应用程序找到以及怎样使用本地化资源。 当然可以直接使用缺省的 Control类而不是非得去实现自定义的 Control类。缺省的 Control类里的方法是为编程人员提供了缺省的功能实现,下面的代码给出的是使用Control类里缺省的功能Locale targetLocale = new Locale("fr", "FR"); // French language, French regionResourceBundle myResources = getBundle("com.sun.demo.intl.AppResource", targetLocale); 假如,你正在使用以 en_US 为缺省local的环境,那么 Control 对象在默认情况下就会搜索如下列出的那些本地化的 AppResource 名称:com.sun.demo.intl.AppResource_fr_FRcom.sun.demo.intl.AppResource_frcom.sun.demo.intl.AppResource_en_UScom.sun.demo.intl.AppResource_encom.sun.demo.intl.AppResource 对于以上列出的每个“绑定”名称,Control默认地会去搜索两种实现格式:一种是 ResourceBundle的子类 (.class 文件格式);另一种是 PropertyResulrceBundle 的属性文件(.properties 文件格式)。假如能找到这两种格式的文件之一,那么就能知道 “绑定”的链级关系,从而得到 ResourceBundle的实例。“绑定名”也是以本地化专用的后缀名来区分,比如,fr_FR, fr 以及 en_US,这就是使用相同的本地化“基准名”再配上用于区分具体“绑定”对象的名。此外,AppResource 的缺省行为是会为“绑定”(bundles)进行缓存的,也就是说,即使在对同一个“绑定”(bundle)反复地调用getBundle 方法也只是得到被缓存过了的资源。在JAVA平台的文档里详细讲述了getBundle 方法的行为方式(http://java.sun.com/javase/6/docs/api/java/util/ResourceBundle.html#getBundle%28java.lang.String,java.util.Locale,java.lang.ClassLoader,java.util.ResourceBundle.Control%29) 除了缺省的方式外,也许会用到不同于缺省行为的“绑定”装载的方式。接下来就来说说在哪些场景下装载绑定是不同于缺省方式的,以下就列写这些场景: 用属性文件(properties),而不是用 class 绑定把资源配置存放到与 local 对应的文件目录中在经过一段时间后似的缓存资源失效 仅搜索 Properties 文件-------------------- 有些资源绑定的装载并不需要一个完整的自定义的 Control 子类,只需要用 Control 类里的静态方法 getControl 再配以标准的选项,与使用缺省的方式稍有不同就能达到我们的目的。假如应用程序在使用属性文件时候有排它性,为了避免遍历搜索所有的 ResourceBundle 子类,我们只需要一个仅搜索 Properties 文件的 Control 对象就可以了。 调用 Control.getControl 方法,并且用一个List<String> 来指定需要的文件格式。这个预定义的字符串的值有两: java.class 和 java.properties 。三个静态的,不可被修改的常量List<String>列出了可指定的文件格式:FORMAT_CLASS 包含 “java.class” 的仅允许 class 文件格式的列表(java.util.List<String>)FORMAT_PROPERTIES 包含“java.properties”的,仅允许properties 文件格式的列表(java.util.List<String>)FORMAT_DEFAULT 既包含“java.class”也包含“java.properties”的列表(java.util.List<String>)选用常量 Control.FORMAT_PROPERTIES使得 Control 对象仅搜索 properties 文件,代码如下:Control propOnlyControl = Control.getControl(Control.FORMAT_PROPERTIES);ResourceBundle bundle = ResourceBundle.getBundle("com.sun.demo.intl.res.Warnings",propOnlyControl); 使用 propOnlyControl 变量(Control 的实例),getBundle 方法就忽略以 class 结尾的文件,而只搜索以 properties 结尾的文件。 Locales 是包名称的一部分----------------------- 基本名相同的各种本地化绑定,通常是以后缀名来区分。缺省的警告信息的"绑定"(Warnings bundle) 仅是简单地用 Warnings.properties 配置文件实现。然而,当你需要用法文来显示这些警告消息的时候,就要用 Warnings_fr_FR.properties 文件了。使用缺省的 Control ,这些本地化绑定名都是存在于同一个包里的,但是可以改变这些本地化绑定的命名。假设有这样的情形:你想要把同一个绑定的不同的本地化版本放置在各自对应的子目录或者是包里,那么就需要按照如下的样子创建这些 properties 并把它们放到各自对应的文件路径或者是包里:com/sun/demo/intl/res/root/Warnings.propertiescom/sun/demo/intl/res/fr_FR/Warnings.propertiescom/sun/demo/intl/res/ja_JP/Warnings.properties 通过子类化 Control,并且在子类中覆盖以下方法来达成这样的目的。需要被覆盖的方法是:* getFormats* toBundleName 覆盖 getFormats 方法是因为应用程序仅需要 properties 文件作资源绑定;覆盖 toBundleName方法是因为应用程序需要使用指定的 locale 作为新的“绑定”的包名称的一部分,而不是在“绑定”后面追加 locale 的名称。
看看示例代码是怎样通过定制 Control 子类来指定 locale 包名class SubdirControl extends Control { //仅搜索 properties 格式的文件 public List<String> getFormats() { return Control.FORMAT_PROPERTIES; } public String toBundleName(String bundleName, Locale locale) { StringBuffer localizedBundle = new StringBuffer(); // Find the base bundle name. int nBaseName = bundleName.lastIndexOf('.'); String baseName = bundleName; // Create a new name starting with the package name. if (nBaseName >= 0) { localizedBundle.append(bundleName.substring(0, nBaseName)); baseName = bundleName.substring(nBaseName+1); } String strLocale = locale.toString(); // Now append the locale identification to the package name. if (strLocale.length() > 0 ) { localizedBundle.append("." + strLocale); } else { localizedBundle.append(".root"); } // Now append the basename to the fully qualified package. localizedBundle.append("." + baseName); return localizedBundle.toString(); }} 下面的代码演示了如何来调用上面子定义的 getBundle 方法:String bundleName = "com.sun.demo.intl.res.Warnings";SubdirControl control = new SubdirControl();Locale locale = new Locale("fr", "FR");ResourceBundle bundle = ResourceBundle.getBundle(bundleName, locale, control); 假如缺省的 locale 是 en_US ,那么 getBundle 方法就用 Control 类去搜索侯选项并返回如下列出的那些包名com.sun.demo.intl.res.fr_FR.Warningscom.sun.demo.intl.res.fr.Warningscom.sun.demo.intl.res.en_US.Warningscom.sun.demo.intl.res.en.Warningscom.sun.demo.intl.res.root.Warnings 缓存 Control 对象的实例-------------------------- 装载资源绑定的时候,默认地就会对每个“绑定”检查,判断它是否已经被装载过。我们也可以对此方式作点改变。假如,想在加载一个绑定前,简单地清除掉缓存,可以调用 ResourceBundle类的 clearCache 方法来实现。ResourceBundle.clearCache();ResourceBundle myBundle = ResourceBundle.getBundle("com.sun.demo.intl.res.Warnings"); 甚至能为缓存设置一个“过期”数值来控制缓存的“生存周期”。在 Control 的子类里覆盖方法getTimeToLive ,这个方法返回以毫秒值代表的“生命周期”。缺省情况下,这个方法返回的是预定义的两个值中的一个,这两个值是:TTL_DONT_CACHE 和 TTL_NO_EXPIRATION_CONTROL Control 缺省情况时返回 TTL_NO_EXPIRATION_CONTROL,这个值表示:缓存永不过期。而 TTL_DONT_CACHE 表示:根本就不对绑定进行缓存。假如,想让“绑定”每过4个小时就要进行更新,而且不是重新启动程序的话,那么需要像如下代码那样来覆盖 getTimeToLive 方法:public long getTimeToLive() {return 4L*60*60*1000; // 14,400,000 milliseconds is four hours.} Control 对象里有很多方法来为绑定的搜索和控制进行细致地设置。本文仅列举了其中的一些,其他的,如下所列的方法也可通过覆盖来实现定制:* getCandidateLocales* getFallbackLocale* newBundle* needsReload 请参阅详细的文档中对这些方法的说明(http://java.sun.com/javase/6/docs/api/java/util/ResourceBundle.Control.html)
针对locale的服务---------------- 在 java.text 和 java.util 包里支持超过100个的 locale。这些locale 可以为世界上大多数地区的人所使用,然而对某些地区的支持仍然未被支持。为了让JAVA支持这些 locale,需要做很多调查工作,比如说研究和确定数字和日期的格式,国家名称的翻译,排列的次序。某些情形下,设置是政治上的冲突都会影响到locale的内容。事实上,JAVA平台上的locale做不到“与时具进”。 有一种解决办法就是提供新的编程接口(API)让编程人员使用任意的 locale 数据。Java SE 6 里提供给编程人员一个新的接口,可让定制的 locale 插到应用程序上或者是关联到服务。幸运的是,当前正在进行的一个项目 Common Locale Data Repository (CLDR通用区域数据仓库)正在努力地跟踪研究现今世界上所有的区域数据并且维护这些数据。Unicode 组织主持这个项目。借助新的“区域相关的服务提供接口”,就可让应用程序使用任意的与区域相关的数据。 为了使用区域相关的数据和服务,先要确定应用程序需要什么样的功能。可以为以下列出的类应用与区域相关的数据:* java.text.BreakIterator* java.text.Collator* java.text.DateFormat* java.text.DateFormatSymbols* java.text.DecimalFormatSymbols* java.text.NumberFormat* java.util.Currency* java.util.Locale* java.util.TimeZone 确定了需要使用区域相关数据的功能后,就要遵照服务提供接口来实现,这些接口是定义在java.text.spi 和 java.util.spi 包里。 比如说,想要为一个新的区域相关的数据提供 DateFormat 对象,可以通过实现抽象类java.text.spi.DateFormatProvider里的* getAvailableLocales* getDateInstance* getDateTimeInstance* getTimeInstance这些方法达到目的。 注意,getAvailableLocales 方法是继承自父类 LocaleServiceProvider,因此所有的SPI提供者必须实现此方法来声明它们所支持的区域对象。其他三个方法是被映射到相关类上的工厂方法,譬如 getDateInstance 方法就是在 java.text.DateFormat 类上的。 实现了以上的这些必要的方法后需要把服务包装起来以便部署到JAVA运行环境。区域相关的服务是基于标准的JAVA扩展机制(http://java.sun.com/javase/6/docs/technotes/guides/extensions/)把它们打包进 JAR 文件并放到 JRE 的扩展目录中,运行环境就能提供当初那些不被支持的区域相关的数据了。 归一化文本--------------- Unicode 标准允许用户以不同的方式创建等效的文本。比方讲,é 这个字符是带重音的拉丁小字母,它在Unicode编码表上的码值是 U+00E9。基本字符 e 和重音符号被合成到一个编码上来表示。 也能把小写字母e和重音符号合并起来展现同样的可见字符。比如,1/2 这样的字符串就有3个字符,它与作为单个字符的1/2(unicode字符 U+00BD)其实表示了同样的意思。类似地,上标字符2与常规字符2是同样的意思,仅是在外观表现上有点不同罢了,正因为字符的这些特点,我们可以使用很多方式来进行文本的输入。你可能想到,像文本搜索和排序是不是会因为同样的字符而表象变得复杂起来呢? Java 中的java.text.Collator 能正确领会Unicode 编码并且会将文本进行“归一化”以实现正确的搜索功能。为了执行文本的正确操作,需要把各不相同的文本转化到单一的形式。在 JDK1.6前,java.text.Collator 使用私有的 API 执行文本归一化,在1.6版本中,这些API成为了公开方法了。 用java.text.Normalizer来对文本执行归一化操作,在进行文本处理,串行化,转换甚至是数据库存储操作前进行归一化工作。java.text.Normalizer 类里只有两个静态方法:normalize 和 isNormalized 。正如所想,normalize 方法对文本执行归一化,isNormalized方法检查文本是否已经被归一化。 枚举型 Normalizer.Form 表示了每个unicode 归一化形式:* NFD (Normalization Form D)* NFC (Normalization Form C)* NFKD (Normalization Form KD)* NFKC (Normalization Form KC) NFD是规范分解,按照unicode标准把合并了的字符分解成合并了的序列。拿unicode码 U+00F1(ñ ),会被分解成 U+006E U+0303,这个分解后的序列其实就是字符n和发音符号。 NFC是紧随规范合成后的规范分解。把文本分解后,接下来把字符序列合并到标准代码。比如把字符序列 U+0065 U+0300 并成单个字符编码 U+00E8,也就是字符 è 。NFC是W3C组织推荐的用于互联网上文本传输和处理的归一化方式。 NFKD是一种兼容性的分解。这种方式把某些字符转换到兼容的形式。通过预定义的字符映射来实现兼容。常见的商标字符 TM,其unicode 码是 U+2122,也就是大写的拉丁字符 T(U+0054)和M(U+004D) NFKC是一种兼容的分解方式。这种归一化方式试图创建兼容原始字符的合并字符。等效的兼容字符由unicode标准定义。把NFKC应用到 U+1E9B (拉丁小写长音字符s,带有圆点上标),分解的时候就创建 U+017F U+0307 两个字符序列,最后,进行合并而成为单个字符 U+1E61 示例代码演示了如何使用Mormalizer类来把文本归一化到NFD形式:String strName = "Jos\u00E9"; // using a composed éString strNFD = Normalizer.normalize(strName, Normalizer.Form.NFD); 变量 strNFD 现在有五个码:Jose' 这五个码是: U+004A U+006F U+0073 U+0065 U+0301接着看看文本是否已经被归一化了:boolean bNormalized = Normalizer.isNormalized(strNFD, Normalizer.Form.NFD);System.out.printf("NFD? %b\n", bNormalized); 国际域名------------------------ RFC 3490为应用程序里的国际域名(IDNA)做定义,事实上,国际域名不在仅限于ASCII码了,根据unicode 3.2 规范,域名定义的限制比原先要少了:unicode 3.2 规范中的所有字符都能用来作域名。很遗憾,域名服务器以及定位服务对于unicode 3.2还不能妥善的存储和使用非ASCII字符的信息。IDNA 的解决方式是:定义一个用ASCII编码来表示非ASCII字符的方法,这就使得DNS和名称定位服务的应用软件继续提供兼容ASCII码的服务,通过使用扩展的unicode字符,集终端用户还能使用国际化域名。
Java SE 6里提供了 java.util.IDN 类来自持IDNA,此类中提供了一些方法来把unicode编码的域名转换成与ASCII码兼容的域名,这些方法是: toASCII 和 toUnicode 。应用程序在和DNS或者是名称定位服务打交道前,需用 toASCII 方法把域名转换到ASCII码;反过来,使用方法 toUnicode 创建用户可见的 unicode 文本。 如果在应用程序里输入非ASCII字符集的域名,程序在把数据发送到国际互联网前需要做如下工作:// 获取应用程序界面上的输入String strUnicodeName = txtUnicodeName.getText();// 转换成与ASCII兼容的编码String strACEName = IDN.toASCII(strUnicodeName); 如图,使用日本语的域名,变量 strACEName 保存了文本 “xn--wgv71a119e.jp”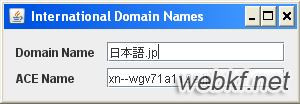 “xn--wgv71a119e.jp”这样的文本谁也读不懂,因为这是对字符编码后的样子,只有对计算机和应用程序有用。可以用下面代码演示如何把这样的字符转变为人能读懂的文本:String strACEName = txtACEName.getText();String strUnicodeName = IDN.toUnicode(strACEName); 日本国的日历--------------- 日本人常使用两种纪年方式:国际上的公元纪年法和他们本国的年号纪年法。几乎所有人都会用公元纪年法,然而日本政府在日常习俗和文件中还常使用年号纪年法。年号纪年法依据天皇在位的时间来定义。 JAVA编程中使用 java.util.Calendar.getInstance 方法来获取日历对象的实例。通过像演示代码中那样的方式来使用日本国的年号纪年法:Calendar calJapanese = Calendar.getInstance(new Locale("ja", "JP", "JP")); 在创建了 Calendar 对象实例后就可在其上使用基于年号纪年法的日期设置,获取以及组装。 公元纪年法和年号纪年法一个明显区别就是在格式化日期上。java.text.SimpleDateFormat和 java.text.DateFormat 类为新的日历格式提供了支持,可向下面代码演示的那样来对日期格式化和显示:Date now = new Date();Locale localeJapanese = new Locale("ja", "JP");Locale localeImperialJapanese = new Locale("ja", "JP", "JP");DateFormat dfGregorian = DateFormat.getDateInstance(DateFormat.FULL, localeJapanese);DateFormat dfImperial = DateFormat.getDateInstance(DateFormat.FULL, localeImperialJapanese);String strGregorianDate = dfGregorian.format(now);String strImperialDate = dfImperial.format(now);txtGregorianDate.setText(strGregorianDate);txtImperialDate.setText(strImperialDate); 对 locale 设置了使用 “ja_JP” 后,DateFormat 就用日文字符来表示年月日的格式化结果。如果对 locale 设置了使用 “ja_JP_JP” ,DateFormat 就会输出年号纪年法格式化的日期字符串。如下图所示:
“xn--wgv71a119e.jp”这样的文本谁也读不懂,因为这是对字符编码后的样子,只有对计算机和应用程序有用。可以用下面代码演示如何把这样的字符转变为人能读懂的文本:String strACEName = txtACEName.getText();String strUnicodeName = IDN.toUnicode(strACEName); 日本国的日历--------------- 日本人常使用两种纪年方式:国际上的公元纪年法和他们本国的年号纪年法。几乎所有人都会用公元纪年法,然而日本政府在日常习俗和文件中还常使用年号纪年法。年号纪年法依据天皇在位的时间来定义。 JAVA编程中使用 java.util.Calendar.getInstance 方法来获取日历对象的实例。通过像演示代码中那样的方式来使用日本国的年号纪年法:Calendar calJapanese = Calendar.getInstance(new Locale("ja", "JP", "JP")); 在创建了 Calendar 对象实例后就可在其上使用基于年号纪年法的日期设置,获取以及组装。 公元纪年法和年号纪年法一个明显区别就是在格式化日期上。java.text.SimpleDateFormat和 java.text.DateFormat 类为新的日历格式提供了支持,可向下面代码演示的那样来对日期格式化和显示:Date now = new Date();Locale localeJapanese = new Locale("ja", "JP");Locale localeImperialJapanese = new Locale("ja", "JP", "JP");DateFormat dfGregorian = DateFormat.getDateInstance(DateFormat.FULL, localeJapanese);DateFormat dfImperial = DateFormat.getDateInstance(DateFormat.FULL, localeImperialJapanese);String strGregorianDate = dfGregorian.format(now);String strImperialDate = dfImperial.format(now);txtGregorianDate.setText(strGregorianDate);txtImperialDate.setText(strImperialDate); 对 locale 设置了使用 “ja_JP” 后,DateFormat 就用日文字符来表示年月日的格式化结果。如果对 locale 设置了使用 “ja_JP_JP” ,DateFormat 就会输出年号纪年法格式化的日期字符串。如下图所示: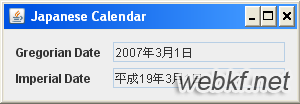 新增locales-------------- 在 Java SE 6 里,在现有支持的LOCALE基础上又新添了许多 locale 以支持不同的区域相关类。区域相关的数据来源于 CLDR (http://unicode.org/cldr/),尽管新的区域相关数据被引入了很多,但是不影响以前就存在的那些区域相关的对象。下表列出了 Java SE 6 里新添加了的区域对象Chinese (Simplified) Singapore zh_SGEnglish Malta en_MTEnglish Philippines en_PHEnglish Singapore en_SGGreek Cyprus el_CYIndonesian Indonesia in_IDIrish Ireland ga_IEJapanese(Japanese Imperial calendar) Japan ja_JP_JPMalay Malaysia ms_MYMaltese Malta mt_MTSerbian Bosnia and Herzegovina sr_BASerbian Serbia and Montenegro sr_CSSpanish United States es_US 小结------------ Java SE 6 向开发者敞开大门,让他们能对资源的定位和装载实现更多的控制,这样就使得JAVA平台对国际化的支持更广泛了,同样,也能使用区域相关的服务接口来支持未在JAVA SE 6中提供的区域数据。Normalizer 类不再是私有的了,它能把文本归一化到四种 unicode 标准格式: NFC,NFD,NFKC,NFKD。不用再把域名限制在ASCII编码集了,IDN类提供API来转换非ASCII域名到可用的兼容ASCII编码的域名服务和名称定位服务。新添加了支持日本国的年号纪年法的日期格式化。结束本文前,超过“一打”的新的区域对象已经可以被拿来使用了,这些区域对象的数据是从 CLDR 项目上获得的,这些新添加了的区域对象不会与现存对象冲突。
新增locales-------------- 在 Java SE 6 里,在现有支持的LOCALE基础上又新添了许多 locale 以支持不同的区域相关类。区域相关的数据来源于 CLDR (http://unicode.org/cldr/),尽管新的区域相关数据被引入了很多,但是不影响以前就存在的那些区域相关的对象。下表列出了 Java SE 6 里新添加了的区域对象Chinese (Simplified) Singapore zh_SGEnglish Malta en_MTEnglish Philippines en_PHEnglish Singapore en_SGGreek Cyprus el_CYIndonesian Indonesia in_IDIrish Ireland ga_IEJapanese(Japanese Imperial calendar) Japan ja_JP_JPMalay Malaysia ms_MYMaltese Malta mt_MTSerbian Bosnia and Herzegovina sr_BASerbian Serbia and Montenegro sr_CSSpanish United States es_US 小结------------ Java SE 6 向开发者敞开大门,让他们能对资源的定位和装载实现更多的控制,这样就使得JAVA平台对国际化的支持更广泛了,同样,也能使用区域相关的服务接口来支持未在JAVA SE 6中提供的区域数据。Normalizer 类不再是私有的了,它能把文本归一化到四种 unicode 标准格式: NFC,NFD,NFKC,NFKD。不用再把域名限制在ASCII编码集了,IDN类提供API来转换非ASCII域名到可用的兼容ASCII编码的域名服务和名称定位服务。新添加了支持日本国的年号纪年法的日期格式化。结束本文前,超过“一打”的新的区域对象已经可以被拿来使用了,这些区域对象的数据是从 CLDR 项目上获得的,这些新添加了的区域对象不会与现存对象冲突。
以上是 J2SE 6 在国际化方面的增强 的全部内容, 来源链接: utcz.com/p/206443.html