Python使用keras进行图像分类项目示例
先决条件:使用CNN的图像分类器
图像分类是一种使用以下方法将图像分类为各自类别的方法:
- 从头开始训练小型网络
- 使用VGG16微调模型的顶层
让我们讨论如何从头开始训练模型并对包含汽车和飞机的数据进行分类。
训练数据:训练数据包含每个汽车和飞机的200张图像, 即它们在训练数据集中总共为400张图像
测试数据 :测试数据包含每个汽车和飞机的50张图像, 即它们在测试数据集中总计为100张图像
要下载完整的数据集, 请单击这里(https://drive.google.com/open?id=1dbcWabr3Xrr4JvuG0VxTiweGzHn-YYvW).
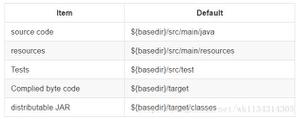
模型描述:在开始使用模型之前, 请先准备数据集及其排列。请看以下图像:

为了馈送数据集文件夹, 应将其制作并仅以这种格式提供。现在, 让我们从模型开始:
为了训练模型, 我们不需要大型高端机器和GPU, 我们也可以与CPU一起工作。首先, 在给定的代码中包括以下库:
# Importing all necessary librariesfrom keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras import backend as K
img_width, img_height = 224 , 224
数据集中的每个图像的大小为224 * 224。
train_data_dir = 'v_data/train'validation_data_dir = 'v_data/test'
nb_train_samples = 400
nb_validation_samples = 100
epochs = 10
batch_size = 16
在这里train_data_dir是训练数据集目录。validation_data_dir是验证数据的目录。nb_train_samples是训练样本的总数。nb_validation_samples是验证样本的总数。
检查图像格式:
if K.image_data_format() = = 'channels_first' : input_shape = ( 3 , img_width, img_height)
else :
input_shape = (img_width, img_height, 3 )
这部分是检查数据格式, 即RGB通道先到还是最后到, 因此无论它是什么形式, 模型都会首先检查, 然后相应地输入输入形状。
model = Sequential()model.add(Conv2D( 32 , ( 2 , 2 ), input_shape = input_shape))
model.add(Activation( 'relu' ))
model.add(MaxPooling2D(pool_size = ( 2 , 2 )))
model.add(Conv2D( 32 , ( 2 , 2 )))
model.add(Activation( 'relu' ))
model.add(MaxPooling2D(pool_size = ( 2 , 2 )))
model.add(Conv2D( 64 , ( 2 , 2 )))
model.add(Activation( 'relu' ))
model.add(MaxPooling2D(pool_size = ( 2 , 2 )))
model.add(Flatten())
model.add(Dense( 64 ))
model.add(Activation( 'relu' ))
model.add(Dropout( 0.5 ))
model.add(Dense( 1 ))
model.add(Activation( 'sigmoid' ))
关于以上使用的以下术语:
Conv2D是将图像卷积为多个图像的层。
Activation是激活功能。
MaxPooling2D用于最大存储给定大小矩阵中的值,下面的2层也使用相同的方法。然后,用Flatten将卷积后得到的图像的尺寸进行Flatten。
Dense用于使它成为完全连接的模型, 并且是隐藏层。
dropout用于避免数据集过拟合。
Dense是输出层, 仅包含一个神经元, 该神经元决定图像属于哪个类别。
编译功能:
model. compile (loss = 'binary_crossentropy' , optimizer = 'rmsprop' , metrics = [ 'accuracy' ])此处使用的编译功能涉及损耗, 优化器和指标的使用。此处使用的损耗函数为二元交叉熵, 使用的优化程序是rmsprop.
使用DataGenerator:
train_datagen = ImageDataGenerator( rescale = 1. /255 , shear_range = 0.2 , zoom_range = 0.2 , horizontal_flip = True )
test_datagen = ImageDataGenerator(rescale = 1. /255 )
train_generator = train_datagen.flow_from_directory(
train_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' )
validation_generator = test_datagen.flow_from_directory(
validation_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' )
model.fit_generator(
train_generator, steps_per_epoch = nb_train_samples //batch_size, epochs = epochs, validation_data = validation_generator, validation_steps = nb_validation_samples //batch_size)
现在, dataGenerator出现在图中, 我们使用了:
ImageDataGenerator可重新缩放图像, 在一定范围内施加剪切力, 缩放图像并对图像进行水平翻转。该ImageDataGenerator包括图像的所有可能方向。
train_datagen.flow_from_directory是用于从train_dataset目录准备数据的函数。Target_size指定图像的目标大小。
test_datagen.flow_from_directory用于准备模型的测试数据, 并且所有与上面类似。
fit_generator用于将数据拟合到上面制作的模型中, 使用的其他因素是step_per_epochs告诉我们关于训练数据执行模型的次数。
epochs告诉我们在向前和向后传递中训练模型的次数。
validation_data用于将验证/测试数据输入模型。
validation_steps表示验证/测试样本的数量。
model.save_weights( 'model_saved.h5' )最后, 我们还可以保存模型。
以下是完整的实现:
# importing librariesfrom keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras import backend as K
img_width, img_height = 224 , 224
train_data_dir = 'v_data/train'
validation_data_dir = 'v_data/test'
nb_train_samples = 400
nb_validation_samples = 100
epochs = 10
batch_size = 16
if K.image_data_format() = = 'channels_first' :
input_shape = ( 3 , img_width, img_height)
else :
input_shape = (img_width, img_height, 3 )
model = Sequential()
model.add(Conv2D( 32 , ( 2 , 2 ), input_shape = input_shape))
model.add(Activation( 'relu' ))
model.add(MaxPooling2D(pool_size = ( 2 , 2 )))
model.add(Conv2D( 32 , ( 2 , 2 )))
model.add(Activation( 'relu' ))
model.add(MaxPooling2D(pool_size = ( 2 , 2 )))
model.add(Conv2D( 64 , ( 2 , 2 )))
model.add(Activation( 'relu' ))
model.add(MaxPooling2D(pool_size = ( 2 , 2 )))
model.add(Flatten())
model.add(Dense( 64 ))
model.add(Activation( 'relu' ))
model.add(Dropout( 0.5 ))
model.add(Dense( 1 ))
model.add(Activation( 'sigmoid' ))
model. compile (loss = 'binary_crossentropy' , optimizer = 'rmsprop' , metrics = [ 'accuracy' ])
train_datagen = ImageDataGenerator(
rescale = 1. /255 , shear_range = 0.2 , zoom_range = 0.2 , horizontal_flip = True )
test_datagen = ImageDataGenerator(rescale = 1. /255 )
train_generator = train_datagen.flow_from_directory(train_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' )
validation_generator = test_datagen.flow_from_directory(
validation_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' )
model.fit_generator(train_generator, steps_per_epoch = nb_train_samples //batch_size, epochs = epochs, validation_data = validation_generator, validation_steps = nb_validation_samples //batch_size)
model.save_weights( 'model_saved.h5' )
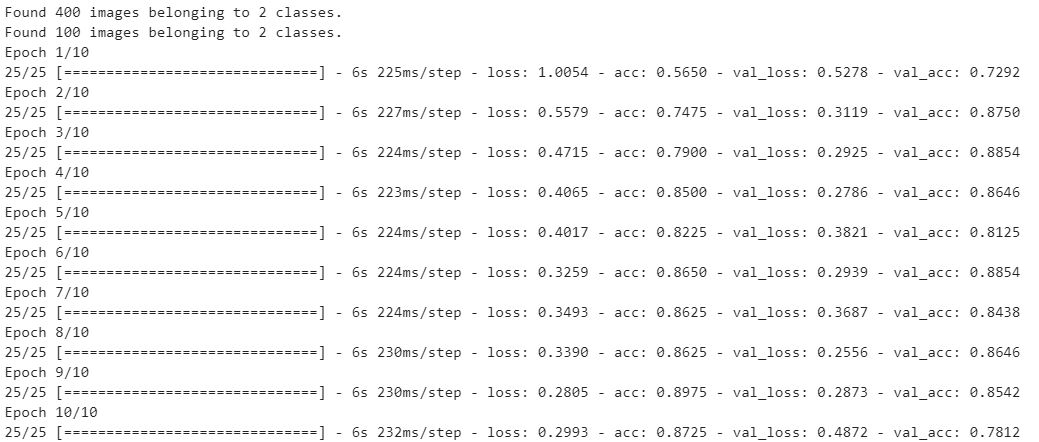
输出如下:
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
以上是 Python使用keras进行图像分类项目示例 的全部内容, 来源链接: utcz.com/p/204385.html