DBSCAN:Python的宏观调查
简而言之, 群集是将一组对象组合在一起的任务, 以使同一群集中的对象彼此之间的相似性高于其他群集中的对象。相似度是反映两个数据对象之间关系强度的量。聚类主要用于探索性数据挖掘。群集在机器学习, 模式识别, 图像分析, 信息检索, 生物信息学, 数据压缩和计算机图形学等许多领域都有广泛的用途。
聚类技术有很多家族, 你可能熟悉最流行的一种:K-Means(属于基于质心的聚类家族)。作为快速更新, K-Means确定数据中的k个质心并通过将点分配给最近的质心来聚类点。
尽管K-Means在实践中易于理解和实现, 但该算法不会处理离群值, 因此, 所有点都被分配给了一个聚类, 即使它们不属于任何聚类。在异常检测领域, 这会引起问题, 因为会将异常点分配给与”正常”数据点相同的群集。异常点将群集质心拉向它们, 因此很难将它们归类为异常点。
本教程将介绍另一种类型的集群技术, 称为基于密度的集群, 特别是DBSCAN(基于密度的集群技术)。与像K-Means这样的基于质心的聚类相比, 基于密度的聚类通过识别点的”密集”聚类来工作, 从而可以学习任意形状的聚类并识别数据中的离群值。
在这篇文章中, 你将了解
- 基于质心的聚类技术的缺点
- 基于密度的聚类技术概述
- DBSCAN的内部运作
- Python中DBSCAN的简单案例研究
- DBSCAN的应用
基于质心的聚类技术的缺点:
在讨论基于质心的聚类的缺点之前, 让我对其进行简要介绍。重心是群集中心的数据点(虚部或实部)。在基于质心的聚类中, 聚类由中心向量或质心表示。此质心可能不一定是数据集的成员。基于质心的聚类是一种迭代聚类算法, 其中相似性的概念是通过数据点与聚类的质心的接近程度得出的。
有时, 数据集可能包含超出预期范围的极值, 并且与其他数据不同。这些被称为离群值。更正式地说, 离群值是与总体中随机样本中的其他值之间存在异常距离的观察值。基于质心的聚类技术的主要基础是数据点和质心之间的距离测量。因此, 基于质心的聚类技术通常无法识别出在很大程度上偏离数据正态分布的数据点。甚至在对数据建立预测模型之前, 离群值都可能导致误导性表示, 进而导致对收集数据的误导性解释。对于从数据构建有效的预测和分析模型, 这基本上是不希望的。
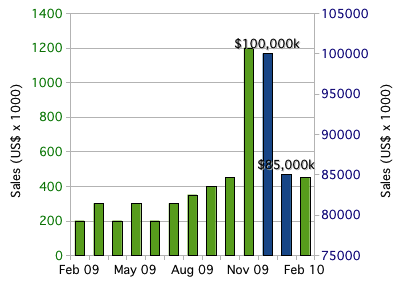
你可以将以下两个较高的条形图(高于其余条形图)视为该特定数据中的异常值:
基于密度的聚类技术的一般介绍:
在讨论基于密度的聚类之前, 你首先需要涵盖一个主题:ɛ-邻里。
ɛ邻域背后的一般思想是给定一个数据点, 你希望能够推理出其周围空间中的数据点。形式上, 对于某些实值ɛ> 0和某个点p, p的ɛ邻域定义为距离p最多为distance的点集。
如果回想一下几何, 所有点都与中心等距的形状就是圆。在2D空间中, 点p的ɛ邻域是包含在以p为中心的半径circle的圆中的点集。在3D空间中, the邻居是半径为p的球体, 以p为中心, 在3D空间中, ɛ邻居只是半径为ɛ的N球体, 以p为中心。
让我们考虑一个使这个想法更具体的例子。在下面的图像中, 100个数据点以[1, 3] X [2, 4]间隔分散。让我们选择点(3, 2)作为我们的点p。
首先, 让我们考虑半径为0.5(ɛ= 0.5)的p的邻域, 即与p相距0.5的点集。
不透明的绿色椭圆形代表我们的社区, 该社区有31个数据点。由于散布了100个数据点, 并且附近有31个数据点, 因此这意味着不到三分之一的数据点包含在半径为0.5的p附近。
现在, 让我们将半径更改为0.15(ɛ= 0.15), 并考虑由此产生的较小邻域。
现在该邻域已缩小, 因此其中仅包含3个数据点。通过将ɛ从0.5减少到0.15(减少70%), 我们附近的点数从31减少到3(减少90%)。
既然你对”邻居”有了一个清晰的了解, 我将介绍下一个重要的概念:邻居的”密度”概念(毕竟, 你正在学习”基于密度的聚类”)。
在小学科学课中, 教导孩子密度=质量/体积。让我们用质量除以体积的概念来定义点p处的密度。如果考虑某个点p及其半径为ɛ的邻域, 则可以将邻域的质量定义为邻域内包含的数据点的数量(或者, 数据点的分数), 并且邻域的体积为volume邻域的最终形状。在2D情况下, 邻域是一个圆, 因此邻域的体积只是所得圆的面积。在3D和更高尺寸的情况下, 邻域是一个球体或n球体, 因此你可以计算此形状的体积。
例如, 让我们再次考虑半径为0.5的p =(3, 2)的邻域。
质量是邻域中数据点的数量, 因此质量=31。体积是圆的面积, 因此体积=π0.52=π/ 4。因此, 我们在* p =(3, 2)处的局部密度近似值被计算为:密度=质量/体积= 31 /(π/ 4)= 124 /π〜= 39.5。
该值本身是没有意义的, 但是如果你为数据集中的所有点计算局部密度近似值, 则可以通过说出附近(包含在同一邻域中)且具有相似局部密度近似值的点属于该点来聚类我们的点。同一集群。如果减小value的值, 则可以构造较小的邻域(较小的体积), 该邻域也将包含较少的数据点。理想情况下, 你要标识高度密集的邻域, 其中大多数数据点都包含在这些邻域中, 但是每个邻域的数量相对较小。
尽管这与DBSCAN或”层次集树”算法(属于基于密度的聚类家族的另一种聚类技术)都不完全一样, 但它形成了基于密度的聚类的一般直觉。
回顾一下, 你介绍了ɛ邻域以及它们如何推理特定点周围的空间。然后, 你了解了特定邻域在特定点的密度概念。在下一节中, 你将了解DBSCAN算法, 其中ɛ-ball是定义聚类的基本工具。
DBSCAN的内部工作原理:
DBSCAN代表带噪声的应用程序的基于密度的空间聚类, 它是最著名的基于密度的聚类算法。它是由Ester等人于1996年首次引入的。等由于其在理论和应用上的重要性, 该算法是在SIGKDD 2014上荣获”时间测试奖”的三种算法之一。
与K-Means不同, DBSCAN不需要将簇数作为参数。而是根据数据推断聚类的数量, 并且可以发现任意形状的聚类(为了进行比较, K-Means通常会发现球形聚类)。如你先前所见, the邻域是DBSCAN近似局部密度的基础, 因此该算法具有两个参数:
- ɛ:数据点p周围的邻域半径。
- minPts:你要在邻域中定义集群的最小数据点数。
使用这两个参数, DBSCAN将数据点分为三类:
- 核心点:如果Nbhd(p, ɛ)[p的邻域]至少包含minPts, 则数据点p是核心点; | Nbhd(p, ɛ)| > =分钟
- 边界点:如果Nbhd(q, ɛ)包含的数据点少于minPts, 则数据点* q是边界点, 但是q可以从某个核心点p到达。
- 离群点:数据点o如果既不是核心点也不是边界点, 则是离群点。本质上, 这是”其他”类。
这些定义可能看起来很抽象, 所以让我们详细介绍每个定义的含义。
核心点:
核心点是我们集群的基础, 该集群基于我在上一节中讨论的密度近似值。你使用相同的ɛ计算每个点的邻域, 因此所有邻域的体积均相同。但是, 每个邻域中其他点的数量有所不同。回想一下, 我说过, 你可以将附近的数据点数量视为其质量。每个邻域的体积是恒定的, 邻域的质量是可变的, 因此, 通过在作为核心点所需的最小质量量上设置阈值, 实际上就是在设置最小密度阈值。因此, 核心点是满足最小密度要求的数据点。我们的集群是围绕核心点构建的(因此是核心部分), 因此, 通过调整minPts参数, 你可以微调集群核心必须具有的密度。
边界点:
边界点是我们集群中不是核心点的点。在上面关于边界点的定义中, 我使用了术语密度可达。我还没有定义这个术语, 但是这个概念很简单。为了解释这一概念, 让我们重新看一下epsilon = 0.15的邻域示例。考虑点p附近的点r(黑点)。
据说p点附近的所有点都可以直接从p到达。现在, 让我们探索点q的邻域, 点p可以直接到达该点。黄色圆圈代表q的邻居。
现在, 虽然你的目标点r不是起点p的邻域, 但它包含在点q的邻域中。这就是密度可达到的思想:如果你可以通过从邻域跳到邻域来到达点r, 则从点p开始, 则点r从点p是密度可达到的。
打个比方, 你可以将密度可达点视为”朋友的朋友”。如果核心点p的直接可达点是其”朋友”, 则p的”朋友”附近的密度可达点就是”其朋友的朋友”。可能不清楚的一件事是密度可达点不仅限于两个相邻的邻域跳跃。只要可以到达从核心点p开始的”邻居跳跃”点, 该点就可以从p达到密度, 因此也包括”朋友的朋友…朋友的朋友”。
重要的是要记住, 密度可达的想法取决于我们的value值。通过选择更大的values值, 更多的点变得密度可达, 而通过选择较小的values值, 更少的点变得密度可达。
离群值:
最后, 你进入”其他”课程。离群点既不是核心点, 也不是距离群集足够近的点, 从核心点可以密度到达。离群值未分配给任何聚类, 并且视情况而定, 可以将其视为异常点。
Python中DBSCAN的案例研究:
在流行的Python机器学习库Scikit-Learn中已经很好地实现了DBSCAN, 并且由于该实现具有可伸缩性和经过了良好的测试, 因此你将使用它来了解DBSCAN的实际工作方式。
DBSCAN算法的步骤为:
- 随机选择一个尚未分配给群集或指定为离群值的点。计算其邻域以确定它是否是核心点。如果是, 请在此点附近启动集群。如果否, 则将该点标记为离群值。
- 一旦找到核心点并因此找到一个集群, 请通过将所有直接可达的点添加到集群来扩展集群。执行”邻居跳跃”以找到所有密度可达到的点, 并将它们添加到群集中。如果添加了异常值, 请将该点的状态从异常值更改为边界点。
- 重复这两个步骤, 直到将所有点都分配给一个群集或指定为离群值。
为此, 你将使用由批发分销商的年度客户数据组成的数据集。
因此, 让我们开始吧。
# Let's import all your dependencies firstfrom sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
数据集包含440个客户, 每个客户都有8个属性。你将使用Pandas库导入.csv文件, 并将其转换为DataFrame对象。
现在, 当你将.csv文件导入时, 请确保提供该文件的正确路径。
# Import .csv file and convert it to a DataFrame objectdf = pd.read_csv("C:/Users/Sayak/data/customers.csv");
print(df.head())
Channel Region Fresh Milk Grocery Frozen Detergents_Paper \0 2 3 12669 9656 7561 214 2674
1 2 3 7057 9810 9568 1762 3293
2 2 3 6353 8808 7684 2405 3516
3 1 3 13265 1196 4221 6404 507
4 2 3 22615 5410 7198 3915 1777
Delicatessen
0 1338
1 1776
2 7844
3 1788
4 5185
现在, 在进一步应用DBSCAN之前, 非常重要的一点是, 你应该充分了解数据, 以便了解数据集中的数据类型, 数据遵循的分布以及哪些功能是数字形式。
根据此数据集的官方UCI机器学习存储库中给出的描述, 有关数据集特征的信息如下:
新鲜:每年在新鲜产品上的支出(连续)(连续);
牛奶:牛奶产品的年度支出(m.u。)(连续);
杂货:杂货产品的年度支出(连续);
冻结:年度冷冻产品支出(m.u。)(连续)
DETERGENTS_PAPER:在洗涤剂和纸制品上的年度支出(m.u。)(连续)
DELICATESSEN:每年在熟食和熟食上的支出(m.u。)(连续);
频道:客户频道-霍雷卡(酒店/餐厅/咖啡厅)或零售频道(名义)地区
现在你已经了解了数据集的功能, 现在让我们显示数据的一些统计信息。
print(df.info())<class 'pandas.core.frame.DataFrame'>RangeIndex: 440 entries, 0 to 439
Data columns (total 8 columns):
Channel 440 non-null int64
Region 440 non-null int64
Fresh 440 non-null int64
Milk 440 non-null int64
Grocery 440 non-null int64
Frozen 440 non-null int64
Detergents_Paper 440 non-null int64
Delicatessen 440 non-null int64
dtypes: int64(8)
memory usage: 27.6 KB
None
从上面的输出中可以看到, 数据集中没有缺失值, 并且所有数据都是整数类型。这减轻了进一步预处理数据的负担。让我们进一步挖掘。
print(df.describe()) Channel Region Fresh Milk Grocery \count 440.000000 440.000000 440.000000 440.000000 440.000000
mean 1.322727 2.543182 12000.297727 5796.265909 7951.277273
std 0.468052 0.774272 12647.328865 7380.377175 9503.162829
min 1.000000 1.000000 3.000000 55.000000 3.000000
25% 1.000000 2.000000 3127.750000 1533.000000 2153.000000
50% 1.000000 3.000000 8504.000000 3627.000000 4755.500000
75% 2.000000 3.000000 16933.750000 7190.250000 10655.750000
max 2.000000 3.000000 112151.000000 73498.000000 92780.000000
Frozen Detergents_Paper Delicatessen
count 440.000000 440.000000 440.000000
mean 3071.931818 2881.493182 1524.870455
std 4854.673333 4767.854448 2820.105937
min 25.000000 3.000000 3.000000
25% 742.250000 256.750000 408.250000
50% 1526.000000 816.500000 965.500000
75% 3554.250000 3922.000000 1820.250000
max 60869.000000 40827.000000 47943.000000
从上面的输出中, 你可以得出所有必要的统计量, 例如数据集中每个特征的标准差, 均值, 最大值。你可以看到此数据集中的大多数数据本质上是连续的, 除了两个功能:通道和区域。因此, 为了简化计算, 你将删除以下两个:
df.drop(["Channel", "Region"], axis = 1, inplace = True)# Let's get a view of the data after the dropprint(df.head())
Fresh Milk Grocery Frozen Detergents_Paper Delicatessen0 12669 9656 7561 214 2674 1338
1 7057 9810 9568 1762 3293 1776
2 6353 8808 7684 2405 3516 7844
3 13265 1196 4221 6404 507 1788
4 22615 5410 7198 3915 1777 5185
因此, 你可以可视化数据, 为此你将使用以下两项功能:
- 杂货:客户在杂货产品上的年度支出(以某种货币为单位)。
- 牛奶:客户在牛奶产品上的年度支出(以货币单位计)。
# Let's plot the data nowx = df['Grocery']
y = df['Milk']
plt.scatter(x, y)
plt.xlabel("Groceries")
plt.ylabel("Milk")
plt.show()

让我们简要介绍一下用于绘图目的的函数:plt.scatter():此函数实际上基于数据(作为提供的[x和y]参数)创建散点图。 plt.xlabel():它可以帮助你沿X轴放置标签。 (在这种情况下为杂货店)plt.ylabel():它可以帮助你沿Y轴放置标签。 (在这种情况下为牛奶)plt.show():创建图后, 此功能可帮助你将其显示为输出。
出于所有可视化目的, 你应该真正探索Matplotlib的美丽世界。它的文档绝对很棒。
你可以轻松地发现误入歧途的数据点。对?好吧, 这些就是你的离群值。
借助DBSCAN, 我们希望确定这一主要客户群, 但同时也希望将具有更多非常规年度购买习惯的客户标记为离群值。
由于数据的值是数千, 因此你将通过将每个属性缩放为0均值和单位方差来规范化每个属性。基本上, 这样做是有助于保持要素之间的相互关系完整, 从而使一个要素的微小变化反映在另一个要素上。
df = df[["Grocery", "Milk"]]df = df.as_matrix().astype("float32", copy = False)
stscaler = StandardScaler().fit(df)df = stscaler.transform(df)
你将构造一个DBSCAN对象, 该对象在半径0.5的附近至少需要15个数据点才能被视为核心点。
dbsc = DBSCAN(eps = .5, min_samples = 15).fit(df)接下来, 我们可以提取聚类标签和离群值以绘制结果。
labels = dbsc.labels_core_samples = np.zeros_like(labels, dtype = bool)
core_samples[dbsc.core_sample_indices_] = True
凭着直觉, DBSCAN算法能够识别一群平均食品杂货和平均乳制品购买量的顾客。此外, 它还可以标记那些年度购买行为与其他客户有太大差异的客户。
由于异常值对应于具有更极端购买行为的客户, 因此批发分销商可以专门为这些客户提供独家折扣, 以鼓励他们进行更大的购买。
DBSCAN的实际应用程序:
- 假设我们有一个电子商务, 并且我们想通过向客户推荐相关产品来提高销售量。我们不确切知道客户在寻找什么, 但是根据数据集, 我们可以预测相关产品并将其推荐给特定客户。我们可以将DBSCAN应用于我们的数据集(基于电子商务数据库), 并根据用户购买的产品查找集群。使用这个集群, 我们可以发现客户之间的相似性, 例如, 如果客户A购买了一支笔, 一本书和一把剪刀, 而客户B购买了一本书和一把剪刀, 那么你可以向客户B推荐一支笔。
- 在基于深度学习的高级方法学兴起之前, 研究人员使用DBSCAN来从可能介导癌症的基因数据集中分离基因。
- 科学家使用DBSCAN来检测由移动GPS设备生成的轨迹数据中的停靠点。停靠点代表了轨迹中最有意义和最重要的部分。
结论:
因此, 在此博文中, 你了解了基于质心的聚类的主要缺点, 并熟悉了另一类聚类技术, 即基于密度的聚类。你还看到了它们如何克服基于质心的聚类的缺点。
你了解了DBSCAN的工作原理, 并进行了案例研究。此外, 你还获得了有关DBSCAN已解决的现实生活问题的全面概述。作为进一步的阅读, 我真的建议大家通过其他基于密度的聚类方法, 例如”级别集树”聚类以及它与DBSCAN有何不同。
如果你想了解有关Python群集的更多信息, 请参加我们的Python无监督学习课程。
参考文献:
- Martin Ester, Hans-Peter Kriegel, JörgSander和Xuxiaowei。 1996年。一种基于密度的发现簇的算法一种基于密度的发现簇的大型空间数据库中的算法。在第二届知识发现和数据挖掘国际会议论文集(KDD’96)中, Evangelos Simoudis, Hanwei Wei和Usama Fayyad(编辑)。 AAAI按226-231。
- https://towardsdatascience.com/how-dbscan-works-and-why-should-i-use-it-443b4a191c80
- https://www.coursera.org/learn/predictive-analytics/lecture/EVHfy/dbscan
以上是 DBSCAN:Python的宏观调查 的全部内容, 来源链接: utcz.com/p/204095.html