用Python预测员工流失
本文概述
过去, 大多数人关注”费率”, 例如损耗率和保留率。人力资源经理计算以前的费率, 尝试使用数据仓库工具预测未来的费率。这些比率代表了客户流失的总体影响, 但这只是一半。除汇总之外, 另一种方法可以是关注单个记录。
有许多有关客户流失的案例研究。在客户流失中, 你可以预测谁和何时停止购买客户。员工流失与客户流失相似。它主要关注于员工而不是客户。在这里, 你可以预测员工将终止服务的人员和时间。员工流失是昂贵的, 并且逐步的改进将带来显着的结果。这将帮助我们设计更好的保留计划并提高员工满意度。
在本教程中, 你将涵盖以下主题:
- 员工流失分析
- 数据加载与理解功能
- 探索性数据分析和数据可视化
- 聚类分析
- 使用Gradient Boosting Tree建立预测模型。
- 评估模型性能
- 总结
员工流失分析

员工流失可以定义为智力资产从公司或组织中泄漏或离开。或者, 用简单的话来说, 你可以说员工离开组织时称为流失。另一个定义可以是人口中的某个成员离开人口时, 即流失。
在《研究》中, 发现员工流失率会受到年龄, 任期, 薪资, 工作满意度, 薪水, 工作条件, 增长潜力和员工对公平的看法的影响。其他一些变量, 例如年龄, 性别, 种族, 文化程度和婚姻状况, 也是预测员工流失的重要因素。在某些情况下, 例如具有利基技能的员工更难替换。它影响了现有员工的日常工作和生产力。招募新员工来替代其成本包括招聘成本和培训成本。此外, 新员工将花时间学习与老员工相似的技术或业务专业知识水平的技能。组织通过应用机器学习技术预测员工流失来解决此问题, 这有助于他们采取必要的行动。
以下几点可帮助你更好地理解员工和客户流失:
- 在市场营销过程中, 企业会选择员工雇用某人, 而你却无法选择客户。
- 员工将成为你公司的面子, 并且员工共同完成公司所做的一切。
- 失去客户会影响收入和品牌形象。与保留现有客户相比, 获取新客户既困难又昂贵。员工流失也给公司的组织带来痛苦。寻找和培训替代者需要时间和精力。
与客户流失相比, 员工流失具有独特的动力。它有助于我们设计更好的员工保留计划并提高员工满意度。数据科学算法可以预测未来的客户流失。
探索性分析
探索性数据分析是一个初始的分析过程, 在此过程中, 你可以使用描述性统计数据和可视化来总结数据特征, 例如模式, 趋势, 离群值和假设检验。
导入模块
#import modulesimport pandas # for dataframes
import matplotlib.pyplot as plt # for plotting graphs
import seaborn as sns # for plotting graphs
% matplotlib inline
加载数据集
首先, 我们使用熊猫的CSV读取功能加载所需的HR数据集。你可以从此链接下载数据。
data=pandas.read_csv('HR_comma_sep.csv')data.head()
- 在此, 原始数据由给定数据集中的逗号分隔符(“, “)分隔。
- 你可以仔细看一下在熊猫库的” head()”函数的帮助下返回的前五个观测值的数据。
- 同样, ” tail()”返回最后五个观察值。
data.tail()
加载数据集后, 你可能想了解更多有关它的信息。你可以使用info()检查属性名称和数据类型。
data.info()<class 'pandas.core.frame.DataFrame'>RangeIndex: 14, 999 entries, 0 to 14, 998
Data columns (total 10 columns):
satisfaction_level 14999 non-null float64
last_evaluation 14999 non-null float64
number_project 14999 non-null int64
average_montly_hours 14999 non-null int64
time_spend_company 14999 non-null int64
Work_accident 14999 non-null int64
left 14999 non-null int64
promotion_last_5years 14999 non-null int64
Departments 14999 non-null object
salary 14999 non-null object
dtypes: float64(2), int64(6), object(2)
memory usage: 1.1+ MB
- 该数据集有14, 999个样本和10个属性(6个整数, 2个float和2个对象)。
- 没有变量列具有null / missing值。
你可以将10个属性详细描述为:
- 满意度等级:员工满意度得分, 取值范围为0-1。
- last_evaluation:由雇主评估绩效, 范围为0-1。
- number_projects:分配给员工的项目数量是多少?
- average_monthly_hours:一个员工一个月平均工作多少小时?
- time_spent_company:time_spent_company表示员工经验。员工在公司中度过的年数。
- work_accident:员工是否发生过工伤事故。
- Promotion_last_5years:员工在过去5年中是否晋升。
- 部门:员工的工作部门/部门。
- 工资:员工的工资水平, 例如低, 中, 高。
- left:员工是否已离开公司。
让我们进入数据洞察
在给定的数据集中, 你有两种类型的员工:一种留下来, 另一种离开了公司。因此, 你可以将数据分为两组并比较它们的特征。在这里, 你可以使用groupby()和mean()函数找到两个组的平均值。
left = data.groupby('left')left.mean()

在这里, 你可以解释为, 离开公司的员工的满意度低, 晋升率低, 薪水低, 并且工作的员工比留在公司的员工多。
熊猫中的describe()函数可方便地获取各种摘要统计信息。此函数返回计数, 均值, 标准偏差, 最小值和最大值以及数据的分位数。
data.describe()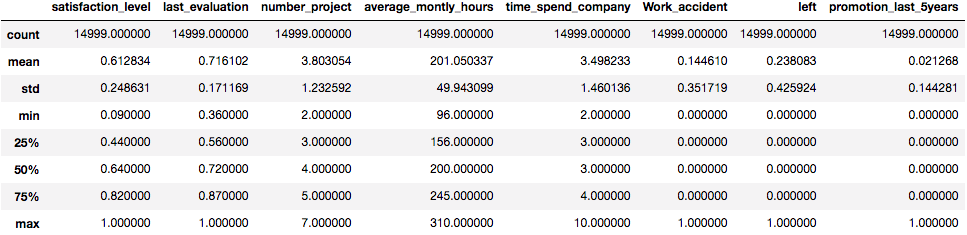
数据可视化
员工离职
让我们检查一下剩下的员工人数吗?
在这里, 你可以使用Matplotlib绘制条形图。条形图适用于显示离散变量计数。
left_count=data.groupby('left').count()plt.bar(left_count.index.values, left_count['satisfaction_level'])
plt.xlabel('Employees Left Company')
plt.ylabel('Number of Employees')
plt.show()

data.left.value_counts()0 114281 3571
Name: left, dtype: int64
在这里, 你可以看到剩余的15, 000个中的3, 571个, 并且留下了11, 428个。剩下的雇员人数是总就业人数的23%。
项目数量
同样, 你也可以绘制条形图以计算在多少个项目上部署的员工数量?
num_projects=data.groupby('number_project').count()plt.bar(num_projects.index.values, num_projects['satisfaction_level'])
plt.xlabel('Number of Projects')
plt.ylabel('Number of Employees')
plt.show()

- 大多数员工是从3-5岁开始做这个项目的。
公司花费的时间
同样, 你也可以绘制条形图以根据多少经验来计算雇员人数?
time_spent=data.groupby('time_spend_company').count()plt.bar(time_spent.index.values, time_spent['satisfaction_level'])
plt.xlabel('Number of Years Spend in Company')
plt.ylabel('Number of Employees')
plt.show()

大多数员工经验在2-4年之间。而且, 3年和4年经验丰富的员工之间存在巨大差距。
使用Seaborn的子图
这是你可以一一分析功能的方法, 但是这很费时。更好的选择是使用Seaborn库并使用子图在一次运行中绘制所有图形。
features=['number_project', 'time_spend_company', 'Work_accident', 'left', 'promotion_last_5years', 'Departments ', 'salary']fig=plt.subplots(figsize=(10, 15))
for i, j in enumerate(features):
plt.subplot(4, 2, i+1)
plt.subplots_adjust(hspace = 1.0)
sns.countplot(x=j, data = data)
plt.xticks(rotation=90)
plt.title("No. of employee")

你可以在以上可视化中观察以下几点:
- 大多数员工是从3-5岁开始做这个项目的。
- 在3年至4年的经验丰富的员工之间大幅下降。
- 剩下的雇员人数是总就业人数的23%。
- 在过去的五年中, 获得晋升的员工人数明显减少。
- 销售部门拥有最大的员工数量, 其次是技术和支持
- 大多数员工的薪水中或低。
fig=plt.subplots(figsize=(10, 15))for i, j in enumerate(features):
plt.subplot(4, 2, i+1)
plt.subplots_adjust(hspace = 1.0)
sns.countplot(x=j, data = data, hue='left')
plt.xticks(rotation=90)
plt.title("No. of employee")

你可以在以上可视化中观察以下几点:
- 项目数量超过5个的那些员工已离开公司。
- 完成了6个和7个项目的员工离开了公司, 似乎他们工作太重了。
- 具有五年经验的员工因最近5年没有晋升而离职更多, 而由于对公司的喜爱而超过6年的经验也没有离职。
- 在过去5年中升职的人没有离开, 即所有离开的人在过去5年中都没有升职。
数据分析和可视化摘要:
以下功能对一个人离开公司的影响最大:
- 晋升:如果员工在过去5年中没有获得晋升, 他们辞职的可能性就更大。
- 与公司的时间:在这里, 三年的时间似乎是员工职业生涯中至关重要的时刻。他们中的大多数人在三年左右的时间里辞职。另一个重要点是6年点, 即员工不太可能离开。
- 项目数量:员工敬业度是影响员工离开公司的另一个关键因素。拥有3-5个项目的员工离职的可能性较小。项目数量越来越少的员工可能会离开。
- 薪资:大多数在中低薪阶层中辞职的员工。
聚类分析
让我们找出离职的员工群体。你会发现, 任何员工留下或离开的最重要因素是公司的满意度和绩效。因此, 让我们使用聚类分析将它们聚集在一群人中。
#import modulefrom sklearn.cluster import KMeans
# Filter data
left_emp = data[['satisfaction_level', 'last_evaluation']][data.left == 1]
# Create groups using K-means clustering.
kmeans = KMeans(n_clusters = 3, random_state = 0).fit(left_emp)
# Add new column "label" annd assign cluster labels.left_emp['label'] = kmeans.labels_
# Draw scatter plot
plt.scatter(left_emp['satisfaction_level'], left_emp['last_evaluation'], c=left_emp['label'], cmap='Accent')
plt.xlabel('Satisfaction Level')
plt.ylabel('Last Evaluation')
plt.title('3 Clusters of employees who left')
plt.show()

在这里, 离开公司的员工可以分为三种类型的员工:
- 较高的满意度和较高的评价(图中绿色阴影), 你也可以称它们为优胜者。
- 低满意度和高评价(在图形中由蓝色阴影(在图形中由绿色阴影)遮蔽), 你也可以将其称为受挫。
- 中度满意和中度评估(在图中以灰色阴影表示), 你也可以将其称为”不匹配”。
建立预测模型
预处理数据
许多机器学习算法需要数字输入数据, 因此你需要在数字列中表示分类列。
为了对该数据进行编码, 可以将每个值映射到一个数字。例如薪金栏的值可以表示为low:0, medium:1和high:2。
此过程称为标签编码, 而sklearn可以方便地使用LabelEncoder为你完成此过程。
# Import LabelEncoderfrom sklearn import preprocessing
#creating labelEncoder
le = preprocessing.LabelEncoder()
# Converting string labels into numbers.
data['salary']=le.fit_transform(data['salary'])
data['Departments ']=le.fit_transform(data['Departments '])
在这里, 你导入了预处理模块并创建了Label Encoder对象。使用此LabelEncoder对象, 你可以适合”工资”和”部门”列并将其转换为数字列。
拆分训练和测试集
为了了解模型的性能, 将数据集分为训练集和测试集是一个很好的策略。
让我们使用函数train_test_split()拆分数据集。你需要传递3个参数功能, 目标和test_set大小。此外, 你可以使用random_state随机选择记录。
#Spliting data into Feature andX=data[['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours', 'time_spend_company', 'Work_accident', 'promotion_last_5years', 'Departments ', 'salary']]
y=data['left']
# Import train_test_split functionfrom sklearn.model_selection import train_test_split
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 70% training and 30% test
在这里, 数据集按70:30的比例分为两部分。这意味着70%的数据将用于模型训练, 而30%的数据将用于模型测试。
建筑模型
让我们为员工建立客户流失预测模型。
在这里, 你将使用”梯度增强分类器”预测流失。
首先, 导入GradientBoostingClassifier模块并使用GradientBoostingClassifier()函数创建Gradient Boosting分类器对象。
然后, 使用fit()将模型拟合到训练集上, 并使用predict()对测试集执行预测。
#Import Gradient Boosting Classifier modelfrom sklearn.ensemble import GradientBoostingClassifier
#Create Gradient Boosting Classifier
gb = GradientBoostingClassifier()
#Train the model using the training sets
gb.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = gb.predict(X_test)
评估模型性能
#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics
# Model Accuracy, how often is the classifier correct?
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Model Precision
print("Precision:", metrics.precision_score(y_test, y_pred))
# Model Recall
print("Recall:", metrics.recall_score(y_test, y_pred))
Accuracy: 0.971555555556Precision: 0.958252427184
Recall: 0.920708955224
好吧, 你的分类率为97%, 被认为是不错的准确性。
精度:精度是指精度, 即模型的精度。换句话说, 你可以说, 当模型做出预测时, 它正确的频率是多少。在你的预测案例中, 当你的Gradient Boosting模型预测某个员工要离开时, 该员工实际上有95%的时间离开。
回想一下:如果有一个员工离开了测试集中, 并且你的Gradient Boosting模型可以在92%的时间内识别出该员工。
总结
恭喜, 你已完成本教程的结尾!
在本教程中, 你学习了什么是员工流失?, 它与客户流失有何不同, 使用matplotlib和seaborn探索性数据分析和员工流失数据集的可视化, 使用python scikit-learn包进行模型构建和评估。
我期待听到任何反馈或问题。你可以通过发表评论来提出问题, 我会尽力回答。
如果你有兴趣了解有关Python的更多信息, 请查看srcmini的数据科学中级Python课程。
以上是 用Python预测员工流失 的全部内容, 来源链接: utcz.com/p/204092.html