适用于金融业的Python:算法交易
本文概述
技术已成为金融中的资产:金融机构现在正向技术公司发展, 而不是仅仅专注于财务方面:除了技术带来创新的事实之外, 它还可以加快速度并有助于获得竞争优势, 速度和频率金融交易的增长以及庞大的数据量, 使得金融机构多年来对技术的关注日益增加, 而技术确实已成为金融的主要推动力。
在最热门的金融编程语言中, 你会发现R和Python, 以及C ++, C#和Java等语言。在本教程中, 你将学习如何开始使用Python进行财务。本教程将涵盖以下内容:
- 你需要入门的基础知识:对于金融新手来说, 你将首先了解有关股票和交易策略, 什么时间序列数据以及设置工作空间所需的知识。
- 使用Python软件包Pandas对时间序列数据和一些最常见的财务分析进行了介绍, 例如移动窗口, 波动率计算。
- 简单动量策略的制定:你将首先逐步完成开发过程, 然后首先制定并编写简单的算法交易策略。
- 接下来, 你将使用Pandas, zipline和Quantopian对已制定的交易策略进行回测。
- 然后, 你将看到如何优化策略以使其表现更好, 并最终评估策略的性能和稳健性。
在此处下载本教程的Jupyter笔记本。
Python财务入门
在制定交易策略之前, 最好先掌握基本知识。本教程的第一部分将重点介绍入门所需的Python基础知识。但是, 这并不意味着你将完全从零开始:你至少应该完成srcmini的免费的Python数据科学入门课程, 在该课程中, 你学习了如何使用Python列表, 包和NumPy。此外, 希望已经了解了流行的Python数据操作包Pandas的基础知识, 但这不是必需的。
然后, 我建议你参加srcmini的Python金融入门课程, 以学习Python的金融基础。然后, 如果你要将新的” Python for Data Science”技能应用于现实世界的财务数据, 请考虑参加”以Python导入和管理财务数据”课程。
股票与交易
当公司想要发展壮大并进行新项目或扩大规模时, 可以发行股票来筹集资金。股票代表公司所有权的一部分, 以换取金钱而发行。买卖股票:买卖双方买卖现有的, 先前发行的股票。出售股票的价格可以独立于公司的成功而变动:价格反而反映了供求关系。这意味着, 每当某只股票被认为是”理想”时, 由于成功, 受欢迎程度……股票价格就会上涨。
请注意, 股票与债券不同, 后者是公司通过借贷(从银行借贷或发行债务)筹集资金的时候。
正如你刚刚读到的, 谈论股票时买卖是必不可少的, 但当然不仅限于此:交易是买卖资产的行为, 可以是金融证券, 例如股票, 债券或有形产品, 例如黄金或石油。
股票交易就是将支付给股票的现金转换为公司所有权的一部分的过程, 可以通过出售将其转换回现金, 而这一切都有望带来利润。现在, 要获得有利可图的回报, 你要么做空, 要么做空:你要么以股票为由, 以为将来股价会上涨以更高的价格卖出, 要么卖出股票, 以期可以买入它以较低的价格返回并实现利润。当你遵循固定的计划去做多或做空市场时, 你就有了交易策略。
制定交易策略需要经历几个阶段, 就像你建立机器学习模型时一样:你制定策略并以可以在计算机上测试的形式指定它, 然后进行一些初步测试或回测, 你可以优化策略, 最后评估策略的性能和稳健性。
交易策略通常通过回测进行验证:你使用历史数据, 使用已开发的策略定义的规则, 使用历史数据重建过去发生的交易。这样, 你可以了解策略的有效性, 并且可以将其用作优化和改进策略的起点, 然后再将其应用于实际市场。当然, 所有这些都在很大程度上依赖于基本理论或信念, 即过去任何可行的策略将来也可能会奏效, 而过去表现不佳的任何策略也可能会有所作为。将来很糟糕。
时间序列数据
时间序列是在连续的等间隔时间点获取的一系列数字数据点。在投资中, 时间序列会在指定的时间段内跟踪选定数据点(例如股票价格)的移动, 并定期记录数据点。如果你仍然不确定究竟是什么样子, 请看以下示例:
你会看到日期位于x轴上, 而价格位于y轴上。在这种情况下, “连续的等距时间点”意味着x轴上的日期相隔14天:请注意3/7/2005与下一个点3/31/2005之间的差异, 以及2005年4月5日和2005年4月19日。
但是, 使用股票数据时, 你经常会看到的不仅是两列, 其中包含期间和价格的观察值, 而且在大多数情况下, 你将有五个列, 其中包含对期间和期初的观察值, 该时期的高, 低和收盘价。这意味着, 如果你将时段设置为每日水平, 那么对当天的观察将使你了解当天的开盘价和收盘价, 以及当天特定股票的极端高低价格走势。
现在, 你已经掌握了学习本教程所需的基本概念。这些概念很快就会回来, 你将在本教程的后面部分进一步了解它们。
设置工作区
准备好工作区是一件容易的事:只需确保在系统上运行Python和集成开发环境(IDE)。但是, 有些方法可以让你入门, 但是刚开始时可能会容易一些。
以Anaconda为例, 它是Python和R的高性能发行版, 其中包括100多个用于数据科学的最受欢迎的Python, R和Scala软件包。此外, 安装Anaconda将使你可以访问720多个软件包, 这些软件包可以轻松地用conac进行安装, conda是Anaconda附带的我们著名的软件包, 依赖项和环境管理器。而且, 除此之外, 你还将获得Jupyter Notebook和Spyder IDE。
听起来不错, 对吧?
你可以从此处安装Anaconda, 不要忘记在srcmini的Jupyter Notebook教程:权威指南中了解如何设置Jupyter Notebook。
当然, Anaconda不是你唯一的选择:你还可以查看Canopy Python发行版(不是免费的), 或尝试使用Quant Platform。
与使用例如Jupyter或Spyder IDE相比, 后者为你提供了其他一些优势, 因为它为你提供了在浏览器中进行财务分析所需的一切!借助Quant平台, 你将可以访问基于GUI的金融工程, 交互式和基于Python的财务分析以及你自己的基于Python的分析库。此外, 你还可以访问一个论坛, 在这里你可以与同行讨论解决方案或问题!
Python金融基础知识:Pandas
当你使用Python进行财务交易时, 通常会发现使用数据处理包Pandas。但是, 一旦你开始更深入地研究, 其他软件包(例如NumPy, SciPy, Matplotlib等)也会通过。
现在, 让我们专注于熊猫并使用它来分析时间序列数据。本节将说明如何导入数据, 使用Pandas探索和处理数据。最重要的是, 你将学习如何对导入的数据进行常见的财务分析。
将财务数据导入Python
pandas-datareader程序包允许从Google, World Bank等源中读取数据。如果你想获得此功能可用的数据源的更新列表, 请转到文档。你曾经能够从Yahoo!访问数据。直接融资, 但此后已弃用。要访问Yahoo!财务数据, 请观看Matt Macarty的这段视频, 其中显示了一种解决方法。对于本教程, 你将使用该包从Yahoo!读取数据。金融。确保通过使用pip install pandas-datareader通过pip安装最新发行版来首先安装软件包。
提示:如果要安装最新的开发版本, 或者遇到任何问题, 可以在此处阅读安装说明。
import pandas_datareader as pdrimport datetime
aapl = pdr.get_data_yahoo('AAPL', start=datetime.datetime(2006, 10, 1), end=datetime.datetime(2012, 1, 1))
请注意, Yahoo API端点最近已更改, 并且, 如果你想自己开始使用该库, 则需要安装临时修复程序, 直到补丁已合并到master分支中才能开始提取数据。来自Yahoo!使用pandas-datareader进行财务。在你自己开始之前, 请务必先阅读此处的问题!
不过, 不用担心, 本教程已经为你加载了数据, 这样你在学习有关Pandas的Python财务知识时就不会遇到任何问题。
尽管pandas-datareader提供了很多将数据导入Python的选项, 但考虑到这一点还是很明智的, 它不是唯一可以用来导入财务数据的软件包:你还可以使用诸如例如, Quantl可以从Google财经获取数据:
import quandl aapl = quandl.get("WIKI/AAPL", start_date="2006-10-01", end_date="2012-01-01")
有关如何使用Quandl将财务数据直接获取到Python中的更多信息, 请转到此页面。
最后, 如果你已经从事金融业已有一段时间, 那么你可能会知道, 你最经常也使用Excel来处理数据。在这种情况下, 你应该知道可以将Python与Excel集成。
有关更多信息, 请查看srcmini的Python Excel教程:权威指南。
处理时间序列数据
当你最终将数据存储在工作空间中时, 你要做的第一件事就是弄脏你的手。但是, 既然你正在使用时间序列数据, 由于你的索引现在包含DateTime值, 这似乎并不那么简单。
不过不用担心!让我们逐步开始, 首先使用一些功能, 你可能已经知道这些功能, 如果你以前有使用R的编程经验, 或者以前曾使用过Pandas, 则应该先探索数据。
无论哪种方式, 你都会发现它非常简单!
如你在上面的代码块中所看到的, 你已经使用pandas_datareader将数据导入到工作区中。产生的对象aapl是一个DataFrame, 它是一个二维标记的数据结构, 具有可能不同类型的列。现在, 当手头有一个普通的DataFrame时, 你可能要做的第一件事就是运行head()和tail()函数以窥视DataFrame的第一行和最后一行。幸运的是, 当你使用时间序列数据时, 这不会改变!
提示:还请确保使用describe()函数来获取有关数据的一些有用的摘要统计信息。
填写下面的srcmini Light块中的空白, 然后对刚刚导入的数据运行这两个函数!
正如你在简介中所看到的那样, 该数据包含四列, 分别是每天的开盘价和收盘价, 以及每天苹果股票的极端高低价格变动。此外, 你还将获得另外两列:”音量”和”调整关闭”。
前一栏用于注册单日交易的股票数量。另一方面, 后者是调整后的收盘价:它是当天的收盘价, 已稍作调整, 以包括第二天开盘前任何时间发生的任何操作。你可以使用此列来查看历史收益, 也可以在对历史收益进行详细分析时使用。
请注意索引或行标签如何包含日期, 以及列或列标签如何包含数值。
提示:如果你现在想使用pandas中的to_csv()函数将此数据保存到一个csv文件中, 并且可以使用read_csv()函数将数据读回到Python中。例如, 在Yahoo API端点已更改, 而你再也无法访问数据的情况下, 这非常方便:)
import pandas as pdaapl.to_csv('data/aapl_ohlc.csv')
df = pd.read_csv('data/aapl_ohlc.csv', header=0, index_col='Date', parse_dates=True)
现在, 你已经简要检查了数据的第一行并查看了一些摘要统计信息, 是时候进一步介绍了。
一种方法是检查索引和列, 并选择例如特定列的最后十行。后者称为子集, 因为你只占数据的一小部分。子集的结果是一个Series, 它是一个能够保存任何类型的一维标记数组。
请记住, DataFrame结构是带有标签的二维标签数组, 其中的列可能包含不同类型的数据。
在下面的练习中检查所有这些。首先, 使用index和columns属性查看数据的索引和列。接下来, 仅通过选择DataFrame的最后10个观察值来对Close列进行子集设置。利用方括号[]隔离最后十个值。你可能已经从其他编程语言(例如R)中知道了这种子集设置方法。最后, 将后者分配给变量ts, 然后使用type()函数检查ts的类型:
方括号可以帮助你对数据进行子集设置, 但是方括号可能不是处理Pandas的最惯用的方法。因此, 你还应该看看loc()和iloc()函数:你将前者用于基于标签的索引, 而后者用于位置索引。
实际上, 这意味着你可以将行标签的标签(例如2007和2006-11-01)传递给loc()函数, 而将整数(例如22和43)传递给iloc()函数。
完成以下练习, 以了解loc()和iloc()的工作方式:
提示:如果你仔细查看子设置的结果, 则会发现数据中缺少某些日期;如果你仔细观察一下模式, 通常会发现缺少两到三天;传统上, 这些天是周末或公共假期, 不属于你的数据。不必担心:这是完全正常的, 你不必填写这些缺失的日子。
除了建立索引之外, 你可能还想探索其他技术来更好地了解你的数据。你永远都不知道还会出现什么。让我们尝试对数据集中的约20行进行采样, 然后对数据重新采样, 以使aapl现在处于每月级别, 而不是每天。你可以使用sample()和resample()函数来执行此操作:
很简单, 不是吗?
之所以经常使用resample()函数, 是因为它在时间序列的频率转换上提供了详尽的控制和更大的灵活性:除了自己指定新的时间间隔并指定如何处理丢失的数据外, 你还可以选择指示如何想要重新采样数据, 如上面的代码示例所示。这与asfreq()方法形成鲜明对比, 后者仅具有前两个选项。
提示:在上述srcmini Light块的IPython控制台中自己尝试一下。传入aapl.asfreq(” M”, method =” bfill”)看看会发生什么!
最后, 在将数据探索提高到一个新水平并开始对数据进行可视化并对数据进行一些常见的财务分析之前, 你可能已经开始计算每天的开盘价和收盘价之间的差异。你可以在熊猫的帮助下快速执行此算术运算。只需从相同数据的”关闭”列的值中减去aapl数据的”打开”列中的值即可。或者, 换句话说, 从aapl.Open中扣除aapl.Close。你将结果存储在aapl DataFrame的名为diff的新列中, 然后在del的帮助下再次将其删除:
提示:请确保注释掉最后一行代码, 以免aapl DataFrame的新列被删除, 你可以检查算术运算的结果!
当然, 绝对值的获悉可能已经帮助你了解你是否进行了良好的投资, 但是从数量上来说, 你可能更感兴趣于一种更相对的方式来衡量股票价值, 例如特定股票的价值已经上涨或下跌了很多。一种方法是通过计算每日百分比变化。
暂时知道这是个好消息, 但现在不必担心。你将对此进行更深入的了解!
本节向你介绍了一些在开始执行先前的分析之前先探索数据的方法。但是, 你仍然可以在此方面做得更多。如果你想了解更多信息, 请考虑进行我们的Python探索性数据分析。
可视化时间序列数据
在通过head(), tail(), indexing …探索数据的旁边, 你可能还想可视化时间序列数据。多亏了Pandas与Matplotlib的绘图集成, 这项任务变得容易了。只需使用plot()函数并将相关参数传递给它即可。此外, 你还可以添加grid参数以指示该图在背景中也应具有网格。
让我们检查并运行下面的代码, 看看如何绘制该图!
如果你想进一步了解Matplotlib及其使用入门, 请查看srcmini的数据科学中级Python课程。
共同财务分析
现在你已经了解了数据, 知道了什么时间序列数据以及如何使用熊猫快速浏览数据, 现在该深入研究一些常见的财务分析了, 以便你真正开始致力于制定交易策略。
在本节的其余部分, 你将了解有关收益率, 移动窗口, 波动率计算和普通最小二乘回归(OLS)的更多信息。
退货
简单的每日百分比变化不考虑股息和其他因素, 而是代表股票在一天的交易中价值的百分比变化量。你会发现, 每天的百分比变化很容易计算, 因为Pandas软件包中包含pct_change()函数, 可以使你的生活更轻松:
请注意, 你需要计算对数收益, 以更好地了解收益随时间的增长情况。
知道如何计算每日百分比变化是很不错的, 但是当你想知道每月或每季度的收益怎么办?在这种情况下, 你可以依靠本教程第一部分中已经看到的resample()。
使用pct_change()相当方便, 但是也会掩盖如何精确计算每日百分比。这就是为什么你可以选择使用熊猫的shift()函数而不使用pct_change()的原因。然后, 将daily_close值除以daily_close.shift(1)-1。但是, 通过使用此函数, 将在结果DataFrame的开头保留NA值。
提示:将以下代码的结果与你在第一个srcmini Light块中获得的结果进行比较, 以清楚地看到这两种计算每日百分比变化的方法之间的差异。
提示:借助Pandas的shift()函数计算每日日志收益。在此srcmini Light块的IPython控制台中尝试一下! (对于那些找不到解决方案的人, 请尝试以下代码:daily_log_returns_shift = np.log(daily_close / daily_close.shift(1)))。
供你参考, 每日百分比变化的计算基于以下公式:\(r_t = \ dfrac {{p_t}} {p_ {t-1}}-1 \), 其中p是价格, t是时间(在这种情况下是一天), r是返回值。
另外, 你可以绘制daily_pct_change的分布图:

分布看起来非常对称且呈正态分布:每日变化集中在垃圾箱0.00周围。但是, 请注意, 如何并且应该使用对Daily_pct_c应用的describe()函数的结果正确解释直方图的结果。你将看到平均值也非常接近0.00 bin, 标准偏差为0.02。另外, 请查看百分位数, 以了解有多少数据点低于-0.010672、0.001677和0.014306。
每日累积累积收益率可用于确定定期投资的价值。你可以通过使用每日百分比变化值, 将它们相加1并使用结果值计算累积乘积来计算每日累积收益率:
注意, 可以再次使用Matplotlib来快速绘制cum_daily_return;只需向其添加plot()函数, 然后可选地确定figsize或图形的大小:
很简单, 不是吗?现在, 如果你不想看到每日收益, 而是希望看到每月收益, 请记住, 你可以轻松地使用resample()函数将cum_daily_return设为每月收益:
知道如何计算回报是一项宝贵的技能, 但是当你不将它们与其他股票进行比较时, 你常常会发现这些数字并没有说太多。因此, 你经常会看到比较两个或更多股票的示例。在本节的其余部分, 你将重点关注从Yahoo!获取更多数据。财务, 以便你可以计算每日百分比变化并比较结果。
请注意, 如果你想这样做, 则需要对Pandas有更全面的了解, 以及如何使用Pandas处理数据!
开始吧!从Yahoo!获取更多数据!财务第一。你可以通过创建包含股票代码或股票代号, 开始日期和结束日期的函数来轻松实现此目的。你看到的下一个函数data(), 然后使用代码来从开始日期到结束日期获取数据并返回它, 以便get()函数可以继续。你可以使用正确的代码来映射数据, 并返回一个将代码数据与代码连接起来的DataFrame。
请查看下面的代码, 其中将来自Apple, Microsoft, IBM和Google的股票数据加载并收集到一个大型DataFrame中:
def get(tickers, startdate, enddate): def data(ticker):
return (pdr.get_data_yahoo(ticker, start=startdate, end=enddate))
datas = map (data, tickers)
return(pd.concat(datas, keys=tickers, names=['Ticker', 'Date']))
tickers = ['AAPL', 'MSFT', 'IBM', 'GOOG']
all_data = get(tickers, datetime.datetime(2006, 10, 1), datetime.datetime(2012, 1, 1))
请注意, 此代码最初是在”精通金融熊猫”中使用的。本教程已将其更新为新标准。另请注意, 由于开发人员仍在研究更永久的修复程序, 以从Yahoo!查询数据。 Finance API, 可能是你需要导入fix_yahoo_finance软件包。你可以在此处找到安装说明, 或查看本教程随附的Jupyter笔记本。
在本教程的其余部分, 你会很安全, 因为数据已经为你加载了!
现在, 你问这些代码行的结果吗?看看这个:
然后, 你可以使用大型DataFrame开始绘制一些有趣的图:

另一个有用的图是散点矩阵。你可以使用pandas库轻松完成此操作。不要忘记在代码中添加scatter_matrix()函数, 以便实际上创建一个散点矩阵:)作为参数, 你传递daily_pct_change, 并作为对角线, 设置要具有内核密度估计(KDE)情节。另外, 你可以使用alpha参数设置透明度, 并使用figsize设置图形大小。

请注意, 在本地工作时, 你可能需要使用绘图模块制作散点图矩阵(即pd.plotting.scatter_matrix())。另外, 很高兴知道内核密度估计图可估计随机变量的概率密度函数。
恭喜你!你已经通过首次财务分析成功地做到了这一点, 在这里你探索了收益!现在是时候进入第二个窗口了。
移动窗户
当你在由特定时间段表示的数据窗口上计算统计信息, 然后以指定的时间间隔在数据上滑动窗口时, 会出现移动窗口。这样, 只要窗口首先落在时间序列的日期之内, 就可以连续计算统计量。
熊猫中有很多函数可以计算移动窗口, 例如rolling_mean(), rolling_std()等。
但是, 请注意, 它们中的大多数都将很快被弃用, 因此最好结合使用rolling()和mean()或std()函数, ………当然取决于要精确计算的移动窗口类型。
但是, 移动窗口对你到底意味着什么?
当然, 确切的含义取决于你应用于数据的统计信息。例如, 滚动平均值可以消除短期波动并突出显示数据的长期趋势。
提示:在IPython控制台中尝试使用Pandas软件包随附的一些其他标准移动窗口功能, 例如rolling_max(), rolling_var()或rolling_median()。请注意, 你也可以结合使用rolling()和max(), var()或中位数()来达到相同的结果!请记住, 如果单击此srcmini Light块顶部的文本中提供的链接, 则可以找到更多功能。
当然, 你可能并不真正了解所有这些内容。也许在Matplotlib的帮助下, 一个简单的图可以帮助你理解滚动平均值及其实际含义:
波动率计算
股票的波动率是对特定时间段内股票收益率方差变化的度量。通常, 将一只股票与另一只股票的波动率进行比较, 以获得一种风险可能较小的感觉, 或者将其与市场指数进行比较以检查该股票在整个市场中的波动率。通常, 波动性越高, 对该股票的投资就越有风险, 这导致投资于另一只股票。
原木返回的移动历史标准偏差-即移动的历史波动率-可能会引起更多关注:还可以使用pd.rolling_std(data, window = x)* math.sqrt(window)来获取对数收益率的移动历史标准差(又称移动历史波动率)。
波动率是通过计算库存变化百分比的滚动窗口标准偏差来计算的。你可以在代码中清楚地看到这一点, 因为你将daily_pct_change和min_periods传递给rolling_std()。
请注意, 窗口的大小可以并且将改变总体结果:如果将窗口变宽并使min_periods变大, 则结果将变得不那么具有代表性。如果使其更小并使窗口更窄, 结果将更接近于标准偏差。
综合考虑所有这些因素, 你会发现, 根据数据采样频率获得正确的窗口大小绝对是一项技能。
普通最小二乘回归(OLS)
经过所有计算之后, 你还可以使用更传统的回归分析(例如, 普通最小二乘回归(OLS))对财务数据进行更多统计分析。
为此, 你必须使用statsmodels库, 该库不仅为你提供用于估计许多不同统计模型的类和函数, 而且还允许你进行统计测试和执行统计数据探索。
请注意, 你确实可以使用Pandas进行OLS回归, 但是ols模块现在已被弃用, 并将在以后的版本中删除。因此, 使用statsmodels软件包是明智的。
请注意, 你在AAPL和MSFT返回数据的串联中添加了[1:], 因此你没有任何NaN值会干扰你的模型。
在研究模型摘要的结果时需要注意的事项如下:
- 部门变量, 指示哪个变量是模型中的响应
- 在这种情况下, 模型是OLS。这是你正在使用的模型
- 此外, 你还可以使用”方法”来指示如何计算模型的参数。在这种情况下, 你会看到此设置为最小二乘。
到目前为止, 你还没有看到太多新信息。你基本上已经在srcmini Light块中运行的代码中设置了所有这些。但是, 你还可以发现其他有趣的事情, 例如:
- 观察数(No.观察数)。请注意, 你还可以使用info()函数通过Pandas包来派生此内容。在上面的srcmini Light块的IPython控制台中运行return_data.info()进行确认。
- 残差的自由度(DF残差)
- 模型中参数的数量, 由DF模型指示;请注意, 该数字不包含上面代码中定义的常数项X。
这基本上是你浏览的整个左栏。右列为你提供了更多关于合身性的信息。你看到例如:
- R平方, 这是确定系数。该分数表明回归线逼近实际数据点的程度。在这种情况下, 结果是0.280。以百分比表示, 这表示分数是28%。当分数为0%时, 表明模型没有解释响应数据均值附近的变化。当然, 分数为100%则相反。
- 你还会看到调整。 R平方分, 乍一看得出相同的数字。但是, 此度量标准背后的计算会根据观察次数和残差(在DF残差中注册)的自由度来调整R平方值。在这种情况下, 调整没有太大效果, 因为调整后的分数仍与常规R平方分数相同。
- F统计量度拟合的重要性。它是通过将模型的均方误差除以残差的均方误差来计算的。该模型的F统计量是514.2。
- 接下来, 还有Prob(F统计量), 它表示在给定不相关的零假设的情况下获得F统计量结果的概率。
- 对数似然性指示似然函数的对数, 在这种情况下为3513.2。
- AIC是Akaike信息准则:该指标会根据观察次数和模型的复杂性来调整对数可能性。该模型的AIC是-7022。
- 最后, BIC或贝叶斯信息准则与你刚刚看到的AIC相似, 但是它会更严厉地惩罚具有更多参数的模型。鉴于此模型只有一个参数(请检查DF模型), BIC得分将与AIC得分相同。
在模型摘要的第一部分下方, 你会看到每个模型系数的报告:
- 系数的估计值记录在coef处。
- std err是系数估计的标准误差。
- 你还可以在t下找到t统计值。此度量标准用于衡量系数在统计上的重要性。
- P> | t |表示系数= 0为真的零假设。如果它小于置信度水平(通常为0.05), 则表明该项与响应之间存在统计上的显着关系。在这种情况下, 你会看到常数的值为0.198, 而APL被设置为0.000。
最后, 模型摘要的最后一部分是其他统计测试, 用于评估残差的分布:
- Omnibus, 即Omnibus D’Angostino的测试:它提供了有关偏斜和峰度存在的组合统计测试。
- 概率(Omnibus)是综合指标转化为概率。
- 接下来, 偏度或偏度测量关于均值的数据的对称性。
- 峰度表明分布的形状, 因为它比较接近均值的数据量和远离均值的数据量(在尾部)。
- Durbin-Watson是对自相关性的测试, 而Jarque-Bera是对偏度和峰度的另一个测试。你还可以将此测试的结果转换为概率, 就像在Prob(JB)中看到的那样。
- 最后, 你有了Cond。不, 它测试多重共线性。
你可以在Matplotlib的帮助下绘制普通最小二乘回归:
请注意, 你还可以使用收益的滚动相关性来交叉检查结果。你可以方便地利用Matplotlib与Pandas的集成, 在滚动相关性的结果上调用plot()函数:
使用Python建立交易策略
现在, 你已经对数据进行了一些主要分析, 是时候制定你的第一个交易策略了;但是在进行所有这些操作之前, 为什么不先了解一些最常见的交易策略呢?简要介绍之后, 无疑会更轻松地推进你的交易策略。
共同的交易策略
从介绍开始, 你仍然会记得, 交易策略是在市场上做多或做空的固定计划, 但是你还没有真正获得更多的信息。通常, 有两种常见的交易策略:动量策略和反转策略。
首先, 动量策略也称为发散或趋势交易。当你遵循此策略时, 你之所以这样做, 是因为你相信数量的移动将沿其当前方向继续。换句话说, 你认为股票具有动量或上升或下降的趋势, 你可以检测和利用。
此策略的一些示例是移动平均线交叉, 双重移动平均线交叉和乌龟交易:
- 移动平均交叉是指资产的价格从移动平均的一侧移动到另一侧。这种交叉表示动量的变化, 可以用作决定进入或退出市场的点。你将在本教程的后面看到这种策略的示例, 这是定量交易的”世界”。
- 当短期平均值与长期平均值交叉时, 会发生双重移动平均值交叉。该信号用于识别动量向短期平均方向移动。当短期均值超过长期均值并高于长期均值时, 会生成买入信号, 而短期均值越过长期均值并低于长期均值会触发卖出信号。
- 根据理查德·丹尼斯(Richard Dennis)最初讲授的策略, 海龟交易是一种流行的趋势。基本策略是在20天高点买入期货, 在20天低点卖出。
其次, 归还策略, 也称为收敛或周期交易。这种策略背离了这样一个信念, 即数量的运动最终会逆转。这似乎有点抽象, 但是当你举这个例子时就不再如此。看一看均值回归策略, 你实际上认为股票回到了均值, 并且可以在偏离均值时加以利用。
听起来已经很实用了, 对吧?
除均值回复策略外, 该策略的另一个示例是交易均值回复的货币对, 类似于均值回复策略。均值回归策略基本上表明股票恢复到均值, 而货币对交易策略对此进行了扩展, 并指出, 如果可以识别出具有较高相关性的两只股票, 则可以使用两种股票之间的价格差异的变化如果两者中的一个与另一个不相关, 则发出交易事件信号。这意味着, 如果两只股票之间的相关性降低, 则可以将价格较高的股票视为空头头寸。应该将其出售, 因为价格较高的股票将返回均值。另一方面, 低价股票将处于多头头寸, 因为随着相关性恢复正常, 价格将上涨。
除了这两种最常用的策略外, 你可能还会偶尔遇到其他一些策略, 例如预测策略, 它会尝试预测股票的方向或价值, 在这种情况下, 是根据随后的未来时间段基于某些历史因素。还有高频交易(HFT)策略, 该策略利用了毫秒以下的市场微观结构。
现在就是未来的所有音乐;现在, 让我们集中精力制定你的第一个交易策略!
简单的交易策略
如上所述, 你将从量化交易的” hello world”开始:移动平均交叉。你将要制定的策略很简单:你可以创建两个不同的回溯期(例如40天和100天)的时间序列的单独的简单移动平均线(SMA)。如果短期移动均线超过长期移动均线, 则你做多;如果长期移动均线超过短期移动均线, 则退出。
请记住, 当你做多时, 你认为股价会上涨并且将来会以更高的价格卖出(=买入信号);当你做空股票时, 你会卖出股票, 期望你可以以较低的价格买回股票并实现盈利(=卖出信号)。
当你刚入门时, 这种简单的策略可能看起来很复杂, 但请逐步进行以下操作:
- 首先定义两个不同的回溯期:一个短窗口和一个长窗口。你设置两个变量, 并为每个变量分配一个整数。确保分配给短窗口的整数比分配给长窗口变量的整数短!
- 接下来, 创建一个空的Signals DataFrame, 但是要确保复制aapl数据的索引, 以便你可以开始计算aapl数据的每日买入或卖出信号。
- 在你的空信号DataFrame中创建一个名为signal的列, 并通过将该列中所有行的值设置为0.0对其进行初始化。
- 准备工作结束后, 是时候在相应的长时窗和短时窗上创建一组短期和长期简单移动平均线了。利用rolling()函数开始滚动窗口计算:在该函数中, 指定窗口和min_period, 并设置中心参数。实际上, 这将导致为你提供roll()函数, 你将short_window或long_window传递给了rolling()函数, 其中1作为窗口中具有值所需的最小观察值的数量, 为False, 因此不会设置标签在窗口的中心。接下来, 别忘了还要链接mean()函数, 以便计算滚动平均值。
- 在计算了短窗口和长窗口的均值之后, 当短移动均线与长移动均线相交时(仅在大于最短移动均线窗口的时间段内), 你应该创建一个信号。在Python中, 这将导致以下情况:signals [‘short_mavg’] [short_window:]> signal [‘long_mavg’] [short_window:]。请注意, 你添加了[short_window:]以符合条件”仅适用于大于最短移动平均窗口的时间段”。当条件为真时, 信号列中的初始值0.0将被1.0覆盖。创建一个”信号”!如果条件为假, 则将保留原始值0.0, 并且不会生成信号。你可以使用NumPy where()函数设置此条件。就像你刚才阅读的内容一样, 将结果分配给它的变量是signals [‘signal’] [short_window], 因为你只想创建大于最短移动平均窗口的周期的信号!
- 最后, 你采用信号的差异来生成实际的交易订单。换句话说, 在信号DataFrame的此列中, 你可以区分多头和空头头寸, 无论你是买进还是卖出股票。
在下面的srcmini Light块中尝试所有这些操作:
这并不难, 不是吗?打印出信号DataFrame并检查结果。在这里重要的是要了解此DataFrame中的位置和信号列的含义。你会发现, 继续前进将变得非常重要!
当你花时间了解交易策略的结果时, 请使用Matplotlib快速绘制所有这些(短期和长期移动平均线以及买入和卖出信号):
结果很酷, 不是吗?
回测交易策略
既然你已掌握了交易策略, 则最好对它进行回测并计算其效果。但是, 在深入了解这一点之前, 你可能只想稍微了解一下回测的陷阱, 回测器中需要哪些组件以及可以用来回测简单算法的Python工具。
但是, 如果你已经掌握最新知识, 则可以继续实施回测器!
回测陷阱
回溯测试除了可以”测试交易策略”之外, 还可以在相关历史数据上测试该策略, 以确保在开始采取行动之前该策略是切实可行的策略。通过回测, 交易者可以在一段时间内模拟和分析使用特定策略进行交易的风险和获利能力。但是, 在进行回测时, 请记住一个陷阱, 这是一个好主意, 当你刚开始时, 这些陷阱可能对你而言并不明显。
例如, 存在外部事件, 例如市场制度变化, 这是监管变化或宏观经济事件, 这些事件肯定会影响你的回测。此外, 流动性限制(例如禁止卖空)可能会严重影响你的回测。
接下来, 你可能会遇到一些陷阱, 例如, 当你过度拟合模型(优化偏差), 由于认为更好而忽略策略规则(干扰)或当你不小心将信息引入到过去的数据中时(前瞻性偏差)。
这些只是你在制定本教程并对其进行回测之后主要需要考虑的一些陷阱。
回测组件
除了陷阱之外, 很高兴知道你的回测器通常包含四个基本组件, 每个回测器通常都应包含这些组件:
- 数据处理程序, 它是一组数据的接口,
- 一种策略, 根据数据生成信号, 该信号会做多或做空,
- 产生订单并管理损益(也称为” PnL”)的投资组合, 以及
- 执行处理程序, 将订单发送给经纪人并接收”执行”或发出已购买或出售股票的信号。
除了这四个组件之外, 你还可以根据其复杂性将更多的内容添加到回测器中。你绝对可以超越这四个组成部分。但是, 对于本入门教程, 你将只专注于使这些基本组件在代码中起作用。
Python工具
要实施回测, 可以使用除Pandas之外的其他工具, 在本教程的第一部分中已广泛使用Pandas来对数据进行一些财务分析。除熊猫外, 还有NumPy和SciPy, 它们提供矢量化, 优化和线性代数例程, 你可以在制定交易策略时使用它们。
此外, 当你使用预测策略时, Python机器学习库Scikit-Learn也可以派上用场, 因为它们提供了创建回归和分类模型所需的一切。有关此库的介绍, 请考虑srcmini的Scikit-Learn监督学习课程。但是, 如果要使用统计库来进行时间序列分析, 则statsmodels库是理想的选择。在执行普通最小二乘回归(OLS)时, 已在本教程中简要使用了此库。
最后, 还有IbPy和ZipLine库。前者为你提供了用于盈透证券在线交易系统的Python API:你将获得连接到盈透证券, 请求股票行情收录器数据, 提交股票定单的所有功能, …后者是多合一的Python回测支持Quantopian的框架, 你将在本教程中使用该框架。
一个简单的回测器的实现
如上所述, 一个简单的回测器由一个策略, 一个数据处理程序, 一个投资组合和一个执行处理程序组成。你已经在上面实现了策略, 并且还可以访问数据处理程序, 该数据处理程序是pandas-datareader或Pandas库, 用于将保存的数据从Excel导入Python。仍然需要执行的组件是执行处理程序和项目组合。
但是, 由于你才刚刚起步, 因此你现在不会专注于实现执行处理程序。相反, 你将在下面看到如何开始创建可生成订单并管理损益的投资组合:
- 首先, 你将创建一个设置变量initial_capital来设置你的初始资本和一个新的DataFrame头寸。再次, 你从另一个DataFrame复制索引;在这种情况下, 这就是信号DataFrame, 因为你要考虑为其生成信号的时间范围。
- 接下来, 在DataFrame中创建一个新列AAPL。在信号为1且移动均线短线超过移动均线(大于最小移动均线窗口的时间段)的那一天, 你将买入100股。信号为0的日子, 由于操作100 * signals [‘signal’], 最终结果将为0。
- 将创建一个新的DataFrame产品组合来存储未平仓头寸的市场价值。
- 接下来, 你创建一个存储位置(或库存数量)差异的DataFrame
- 然后, 真正的回溯测试开始了:你使用名称持有为投资组合数据框架创建一个新列, 该列存储你购买的头寸或股票的价值乘以”平仓价”。
- 你的投资组合还包含一个现金列, 这是你仍然有待动用的资本:它是通过减去initial_capital并减去所持股份(购买股票所支付的价格)来计算的。
- 你还将在投资组合数据框架中添加一个总计列, 其中包含你的现金和所持资产的总和, 以及
- 最后, 你还要在投资组合中添加一个退货列, 在其中存储退货
作为你的回测的最后一个练习, 借助Matplotlib和回测的结果, 可视化多年来的投资组合价值或投资组合[‘total’]:
请注意, 在本教程中, 回测器的Pandas代码以及交易策略的编写方式使你可以轻松地以交互方式遍历它。在现实生活中的应用程序中, 你可能会选择具有更多类的面向对象设计, 这些类包含所有逻辑。你可以在此处找到具有面向对象设计的相同移动平均交叉策略的示例, 在这里查看本演示文稿, 并且绝对不要忘记srcmini的Python函数教程。
使用Zipline和Quantopian进行回测
你现在已经了解了如何使用Python流行的数据处理程序包Pandas实现回测器。但是, 你还可以看到容易出错, 并且这并不是每次都使用的最安全的选择:即使你已经利用Pandas来获得结果, 也需要从头开始构建大多数组件。 。
这就是为什么对你的反向测试者使用诸如Quantopian之类的反向测试平台的原因。 Quantopian是一个免费的, 以社区为中心的托管平台, 用于建立和执行交易策略。它由zipline(用于算法交易的Python库)提供支持。你可以在本地使用该库, 但对于本入门教程而言, 你将使用Quantopian编写和回测算法。但是, 在执行此操作之前, 请确保先注册并登录。
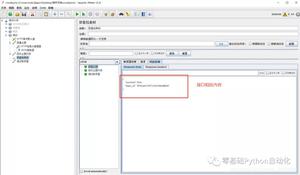
接下来, 你可以轻松上手。点击”新算法”以开始编写交易算法, 或者选择一个已经为你编写的示例, 以更好地了解你要处理的内容:)

让我们开始简单并制定一个新算法, 但仍然遵循我们的移动平均交叉的简单示例, 这是你在zipline快速入门指南中找到的标准示例。
碰巧这个示例与你在上一节中实现的简单交易策略非常相似。但是, 你会看到下面的代码块和上面的屏幕快照中的结构与你在本教程中到目前为止看到的结构有些不同, 即, 你有两个开始使用的定义, 即initialize()和handle_data():
def initialize(context): context.sym = symbol('AAPL')
context.i = 0
def handle_data(context, data):
# Skip first 300 days to get full windows
context.i += 1
if context.i < 300:
return
# Compute averages
# history() has to be called with the same params
# from above and returns a pandas dataframe.
short_mavg = data.history(context.sym, 'price', 100, '1d').mean()
long_mavg = data.history(context.sym, 'price', 300, '1d').mean()
# Trading logic
if short_mavg > long_mavg:
# order_target orders as many shares as needed to
# achieve the desired number of shares.
order_target(context.sym, 100)
elif short_mavg < long_mavg:
order_target(context.sym, 0)
# Save values for later inspection
record(AAPL=data.current(context.sym, "price"), short_mavg=short_mavg, long_mavg=long_mavg)
当程序启动并执行一次性启动逻辑时, 将调用第一个函数。作为参数, initialize()函数采用一个上下文, 该上下文用于在回测或实时交易期间存储状态, 并且可以在算法的不同部分中进行引用, 如下面的代码所示;你会看到上下文在第一个移动平均窗口的定义中返回。你将看到通过证券(在这种情况下为APL)的符号(在这种情况下为APL)将证券的搜索结果分配给context.security。
在模拟或实时交易期间, 每分钟调用一次handle_data()函数, 以决定每分钟应下达的订单(如果有)。该函数需要上下文和数据作为输入:上下文与你刚刚阅读的上下文相同, 而数据是一个对象, 该对象存储多个API函数, 例如current()以检索给定的最新值给定资产或历史记录的字段, 以获取历史价格或交易量数据的尾随窗口。这些API函数不会出现在下面的代码中, 也不属于本教程的范围。
请注意, 例如, 你在Quantopian控制台中键入的代码只能在平台本身上运行, 而不能在本地Jupyter Notebook中使用!
你会看到该数据对象使你可以检索价格(如果有的话, 该价格是向前填充的, 并返回最近的已知价格)。如果没有, 将返回一个NaN值。
你在上面的代码块中看到的另一个对象是投资组合, 它存储有关……的重要信息。你的投资组合。如你在代码片段context.portfolio.positions中所看到的, 此对象存储在上下文中, 然后在上下文必须作为用户提供给你的核心功能中也可以访问。请注意, 你刚刚阅读的头寸将存储Position对象, 并包括诸如股票数量和作为价格支付的价格之类的信息。此外, 你还看到投资组合还具有现金属性以检索投资组合中的当前现金量, 并且头寸对象还具有金额属性以探索特定头寸中的全部股份数量。
order_target()下订单以将头寸调整为目标股份数。如果资产中没有现有头寸, 则会下达完整目标编号的订单。如果资产中有头寸, 则将下达目标股份或合约数量与当前持有数量之差的订单。下达负目标定单将导致空头头寸等于指定的负数。
提示:如果对功能或对象还有其他疑问, 请确保检查” Quantopian帮助”页面, 该页面包含有关本教程中简要介绍的所有(以及更多)信息。
使用initialize()和handle_data()函数(或将上面的代码复制粘贴)创建策略到界面左侧的控制台后, 只需按” Build Algorithm”按钮即可构建代码并进行回测。如果你按下”运行全面回溯测试”按钮, 则会运行全面回溯测试, 该流程与构建算法时所执行的完全相同, 但是你将能够看到更多详细信息。无论是”简单”测试还是完整测试, 回测都可能需要一段时间。确保注意页面顶部的进度条!

你可以在此处找到有关如何开始使用Quantopian的更多信息。
请注意, Quantopian是使用zipline入门的简便方法, 但是你始终可以继续在本地使用库, 例如Jupyter笔记本。
改善交易策略
你已经成功制作了一个简单的交易算法, 并通过Pandas, Zipline和Quantopian执行了回测。可以说你已经开始使用Python进行交易了。但是, 当你制定了交易策略并对其进行了回测后, 你的工作还没有停止;你可能需要改善策略。可以使用一种或多种算法在连续基础上改进模型, 例如KMeans, k最近邻(KNN), 分类树或回归树和遗传算法。这将是将来的srcmini教程的主题。
除了可以使用的其他算法之外, 你还看到可以通过使用多符号组合来改善策略。仅将一个公司或符号纳入你的策略通常并不能说太多。你还会在评估移动平均交叉策略时看到这一点。你可以添加或以其他方式执行的其他操作是使用风险管理框架或使用事件驱动的回测, 以帮助减轻你先前了解的前瞻性偏见。你还有许多其他方法可以改善策略, 但是现在, 这是一个良好的起点!
评估移动平均交叉策略
改善策略并不意味着你就算完成了!你可以轻松地使用Pandas来计算一些指标, 以进一步判断你的简单交易策略。首先, 你可以使用Sharpe比率来了解你投资组合的回报是你决定进行明智投资还是承担大量风险的结果。
当然, 理想的情况是回报是可观的, 但投资的额外风险则应尽可能小。这就是为什么投资组合的夏普比率越大越好:回报与所产生的额外风险之间的比率是可以接受的。通常, 投资者可以接受大于1的比率, 2的比率非常好, 3的比率很好。
让我们看看你的算法是如何做的!
请注意, 本教程的Sharpe比率的定义中未包含无风险利率, 并且通常不将Sharpe比率视为独立的比率:通常将其与其他股票进行比较。因此, 解决此问题的最佳方法是通过使用更多数据(来自其他公司)扩展你的原始交易策略!
接下来, 你还可以计算最大跌幅, 该跌幅用于衡量投资组合价值从峰值到谷底的最大单次下跌, 以便在达到新峰值之前。换句话说, 分数表示基于某种策略选择的投资组合的风险。
请注意, 将min_periods设置为1是因为你希望让前252天的数据具有扩展窗口。
接下来是复合年增长率(CAGR), 它将为你提供一段时间内的恒定回报率。换句话说, 利率告诉你在投资期结束时你真正拥有什么。你可以通过先将投资的最终价值(EV)除以投资的初始价值(BV)来计算此汇率。你将结果提高到1 / n的幂, 其中n是周期数。你从结果中减去1, 就可以看到CAGR!
也许公式更清晰:\ [((EV / BV)^ {1 / n}-1 \]
请注意, 在下面的代码块中, 你会看到考虑了天数, 因此将1调整为365天(等于1年)。
除了这两个指标, 你还可以考虑其他许多指标, 例如收益分配, 贸易水平指标, …
现在怎么办?
做得好, 你已经通过此Python Finance入门教程实现了!你已经涉足了很多领域, 但是还有更多的发现要探索!首先参加srcmini的Python金融入门课程, 以了解更多基础知识。
你还应该阅读Yves Hilpisch的《 Python for Finance》一书, 对于那些已经拥有一定金融背景但对Python不太了解的人来说, 这是一本不错的书。对于那些想开始使用Python进行金融学习的人, 也推荐Michael Heydt撰写的”掌握数据科学的熊猫”!另外, 请务必查看Quantstart的文章, 以获取有关算法交易的指导性教程以及有关金融金融Python编程的完整系列文章。
如果你对使用R继续从事金融之旅更感兴趣, 请考虑参加srcmini的R定量分析师。同时, 请继续发布我们的第二篇有关使用Python启动财务的文章, 并查看本教程的Jupyter笔记本。
本网站提供的信息不是财务建议, 所有作者都不是财务专业人员。本网站上提供的材料应仅用于提供信息, 绝不应该作为财务建议。我们对任何信息的准确性, 完整性, 适用性或有效性不做任何陈述。对于因其显示或使用而引起的任何错误, 遗漏或任何损失, 伤害或损坏, 我们概不负责。所有信息均按原样提供, 不提供任何担保, 也不授予任何权利。另外, 请注意, 此类材料不会定期更新, 因此某些信息可能不是最新信息。在做出有关财务管理的决定时, 请务必咨询你自己的财务顾问。在未首先评估你自己的个人和财务状况或未咨询财务专家的情况下, 切勿使用此博客中提到的思想和策略。
以上是 适用于金融业的Python:算法交易 的全部内容, 来源链接: utcz.com/p/204034.html