Spotless Sandboxes->Evading Malware Analysis Systems using Wear-and-Tear Artifacts
出处:2017 IEEE Symposium on Security and Privacy (SP)
作者:Najmeh Miramirkhani, Mahathi Priya Appini, Nick Nikiforakis, Michalis Polychronakis
单位:Stony Brook University
资料:Paper
译者:Z3R0YU
译者博客:http://zeroyu.xyz/
1.Abstract & INTRODUCTION
动态恶意代码分析系统通过将每个样本加载到称为沙箱的大量仪器环境中来操作,并以不同的粒度级别(例如,I/O活动,系统调用,机器指令)监视其操作。 恶意软件沙箱通常使用API hooking机制、CPU仿真器、虚拟机、甚至是专用的裸机主机来构建。
攻击者角度:
- 使用打包、多态以及其他代码混淆技术规避基于静态代码分析的恶意软件扫描技术;
- 在恶意软件中加入一定的“环境感知能力”来规避恶意软件沙箱环境的分析(在发现身处沙箱环境后采用直接崩溃或者展示“良性”行为)。
防御者角度:
- 一般而言用实际值替换分析环境的特有属性并隐藏检测工具,来尝试避免被恶意软件感知;
- 针对使用仿真或者虚拟技术的产品而言,使用清除特定的驱动程序、进程以及其它虚拟技术指示器来实现防规避;
- 使用裸机(在进行一定的隔离后,直接使用物理计算机)。
防御者角度的问题缺陷:
- 用于分析的操作系统几乎是原始状态的;
- 每次进行过二进制分析之后就会将系统回滚至最初状态(浏览器记录、系统日志等信息均被回滚)。
PS:以上内容之所以说是缺陷,是因为真实环境中用户不可能主动去将”缓存”(广义缓存,泛指日志、注册表等)的记录进行回滚或者初始化。
因此在本文中作者提出了一种利用操作系统“wear and tear”(使用痕迹的含义,后文简称为磨损)和“aging”(使用年份的含义,后文简称为老化)的特征来规避sandbox(恶意软件沙箱环境)的方法。
本文的两项研究成果:
- 构建决策树模型,使恶意软件稳定地避免所有经过测试的沙箱的准确率提升至92.86%;
- 构建的统计模型可以根据系统使用指标预测系统的年龄,并可用于将现有的人造沙箱“老化”到所需的年限范围。
BACKGROUND AND RELATED WORK
A. Virtualization and Instrumentation Artifacts
- 防御者D: 使用系统仿真器和虚拟机构建恶意软件沙箱十分方便
- 攻击者A: 使用静态启发式检查某些系统属性,例如特定于VM的设备驱动程序和硬件配置,固定标识符(包括MAC地址),IMEI(用于移动恶意软件分析系统),用户/主机名,VM特定加载的模块和流程(例如VMware的VMware Tools)和注册表项等
- 防御者D: 配置动态分析系统时以避免出现期望值和配置
- 攻击者A: 这对虚拟化指令的时序属性、运行时使用小代码片段等底层属性作用不大
B. Environmental and User Interaction Artifacts
防御者D: 我的两种方案:
- 在多个不同的分析系统上运行每个样本来检测恶意软件的“分裂个性”;
- 避免完全使用仿真或虚拟化,并选择“裸机”系统来保持分析环境的真实性。
攻击者A: 目前虚拟化技术的广泛使用,应当认为VM和非VM是具有同样的感染价值的,从而减少对VM检测技巧的使用,转而采取如下几种启发式方法:
- 检查鼠标光标是否在屏幕中央保持静止;
- 是否存在“最近打开文件”;
- 异常低数量的进程;
- 不受限制的互联网连接,并尝试解析已知的不存在的域名(比如WannaCry)。
防御者D: 我的两种对策:
- 模拟用户行为;
- 暴露更真实的网络环境
防御者D对策的缺陷: 系统正常使用而预计会发生磨损和老化特征未被考虑。
C. Sandbox Fingerprinting
SandFinger: 使用移动设备属性来作为沙箱指纹来规避Google的Bouncer沙箱。
AVLeak: 使用侧信道的方式捕获AV引擎中的指纹。
SandPrint: 提取Windows沙箱中的硬件配置参数,恶意软件样本调用机制的特征,可执行文件的文件名等特征进行聚类分析,进而识别沙箱。
如果沙箱操作员将沙箱的特征值进行多样化处理,致使是指纹失效。那么攻击者下一步会考虑怎么方法进行规避? 这种方式就是本文中所提到的真实系统才具有的“磨损”和“老化”特征。
III. WEAR AND TEAR ARTIFACTS
文中选用的artifact的特点: 恶意软件可以轻松探测
artifact的选择策略: 哪些在系统的正常使用中会被影响
A. Probing for Artifacts while Preserving User Privacy
从artifact地选择上来看可以分为两种:一种是直接源于用户活动;另一种是来自系统活动(用户活动的间接表现)。
直接来源是针对用户行为的定性指标:
- 文档文件夹是否包含具有预期文件扩展名的合理数量的文件;
- 检查流行文档查看应用程序中最近打开的文档;
- 最近键入的在线搜索引擎查询;
- 系统范围的搜索查询
- 即时消息;
- 电子邮件消息内容
但是这些将会对用户的隐私造成侵犯,所以本文的方案将使用间接来源(比如:统计cookie、访问的URL数量等方式)
B. Artifact Categories
本文主要针对Windows操作系统进行研究,所以采用的artifact类别集合如下表所示:
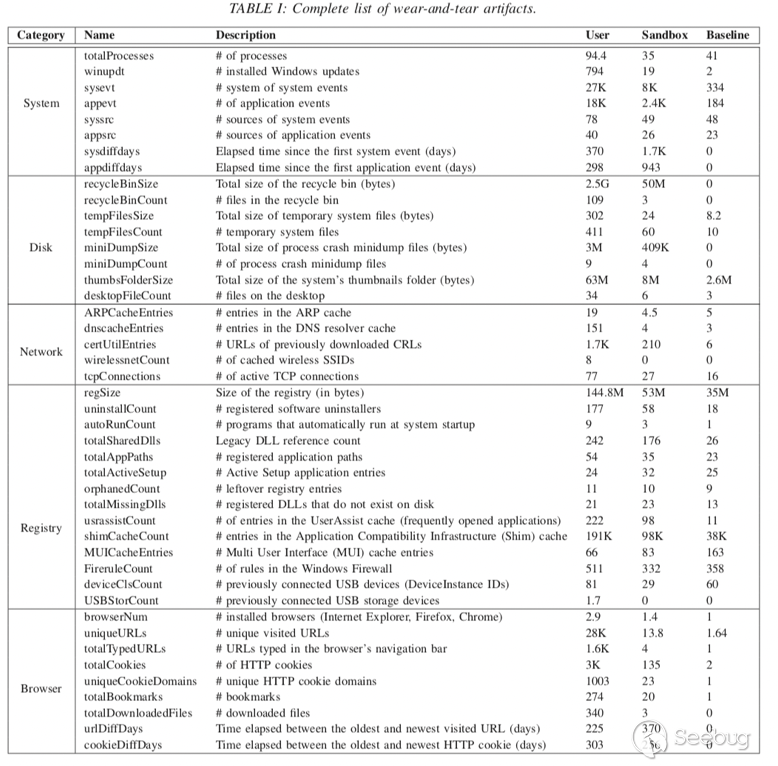
IV. DATA COLLECTION
A. Probe Tool Implementation
为了从真实用户系统和恶意软件沙箱中收集以上类别的artifact数据集,作者实现了一个只使用系统API、不需要安装并且兼容Windows XP到Windows 10的探针程序。这个程序主要有以下几个特点:
- 使用HTTPS信道传输收集到的artifact数据防止沙箱拦截请求;
- 收集一些BIOS供应商等其他信息用于VM启发式检测,来去除用户集中可能存在的VM结果集;
- 唯一的嵌入式ID来识别同一供应商的多次提交(一些砂箱会将程序放在多个不同的环境中进行动态分析,进而检测其行为);
- 基于操作系统安装日期,Windows版本,BIOS供应商等信息的组合来区分不同的操作系统。
B. IRB Approval and User Involvement
这部分主要讲述作者在申请IRB批准,从而让真实用户参与进这个项目中。
C. Data Collection
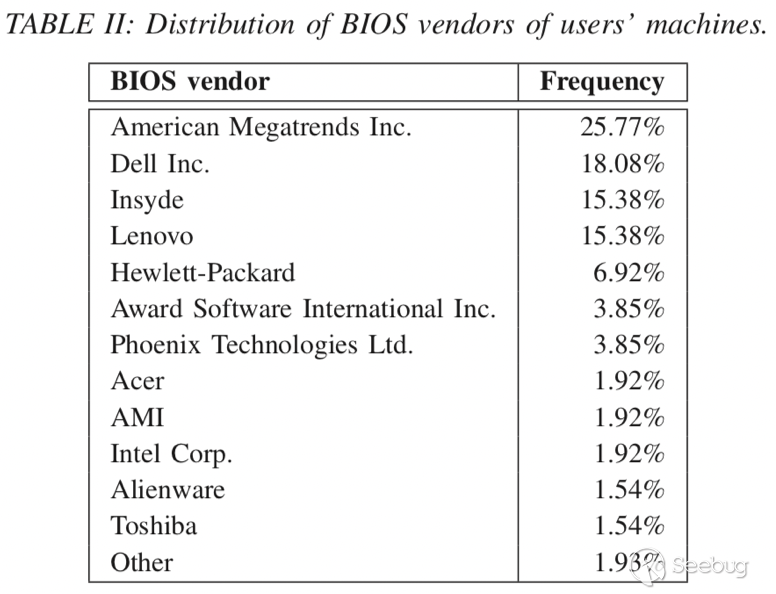
第一个数据集(Dreal)-> 270个真实用户机器,其中有89.4%是Amazon Mechanical Turk workers。国家分布为美国(44%),印度(18%),GB(10%),CA(8%),NL(1%),PK (1%),RU(1%)和其他28个频率低于1%的国家/地区(这种国家分析代表了从发达国家到发展中国家的计算机使用磨损特性)。表II中显示了用户系统的BIOS供应商分布。
PS:后面作者发现Amazon Mechanical Turk workers是一种跟搜索引擎相结合的沙箱,因此将这一部分的数据标记为“crawlers”并合并到后面的沙箱数据集中。
第二个数据集(Dsand)-> 来自15个可以收集到信息的恶意软件沙箱,表III是沙箱与对应探针回收的信息。
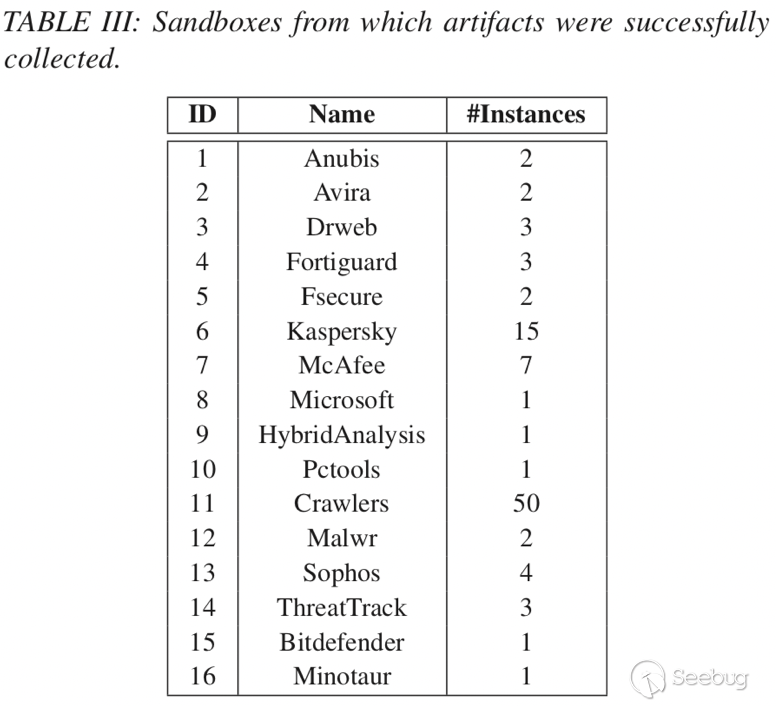
PS:有的沙箱环境会在底层使用不同版本的操作系统来分别进行分析。
第三个数据集(Dbase)-> 基准数据集,数据来自多个全新安装的Microsoft Windows版本(包括Azure和AWS提供的云Windows服务器)。
D. Dataset Statistics
表IV显示了我们三个收集的数据集中不同Microsoft Windows版本的数量。(可以看出沙箱的系统分布与真实用户的是不相同的)。
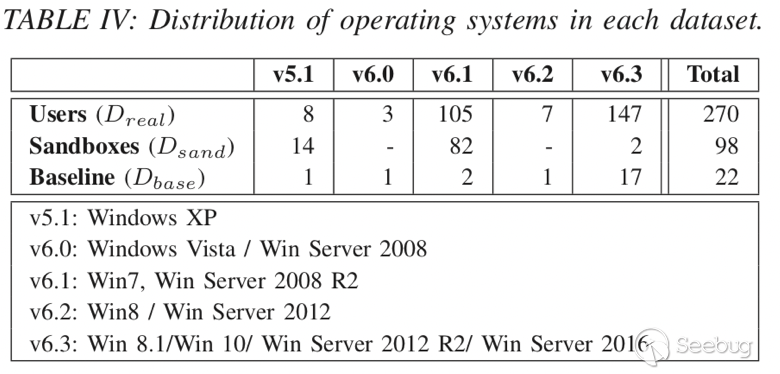
图1显示了三个数据集(Dreal,Dsand和Dbase)中每个磨损artifact值的分布。从中可以看到:1.大多数artifact在真实用户系统中的值大于沙箱和基线中的值,因此可以用来区分真实用户和沙箱;2.真实用户的artifact值分布更宽,因此可以用来预测系统年龄。
PS: 可以看到沙箱的appdiffdays和sysdiffdays值比真实用户高很多,因此沙箱系统一般比真实用户系统“老化”程度更高。
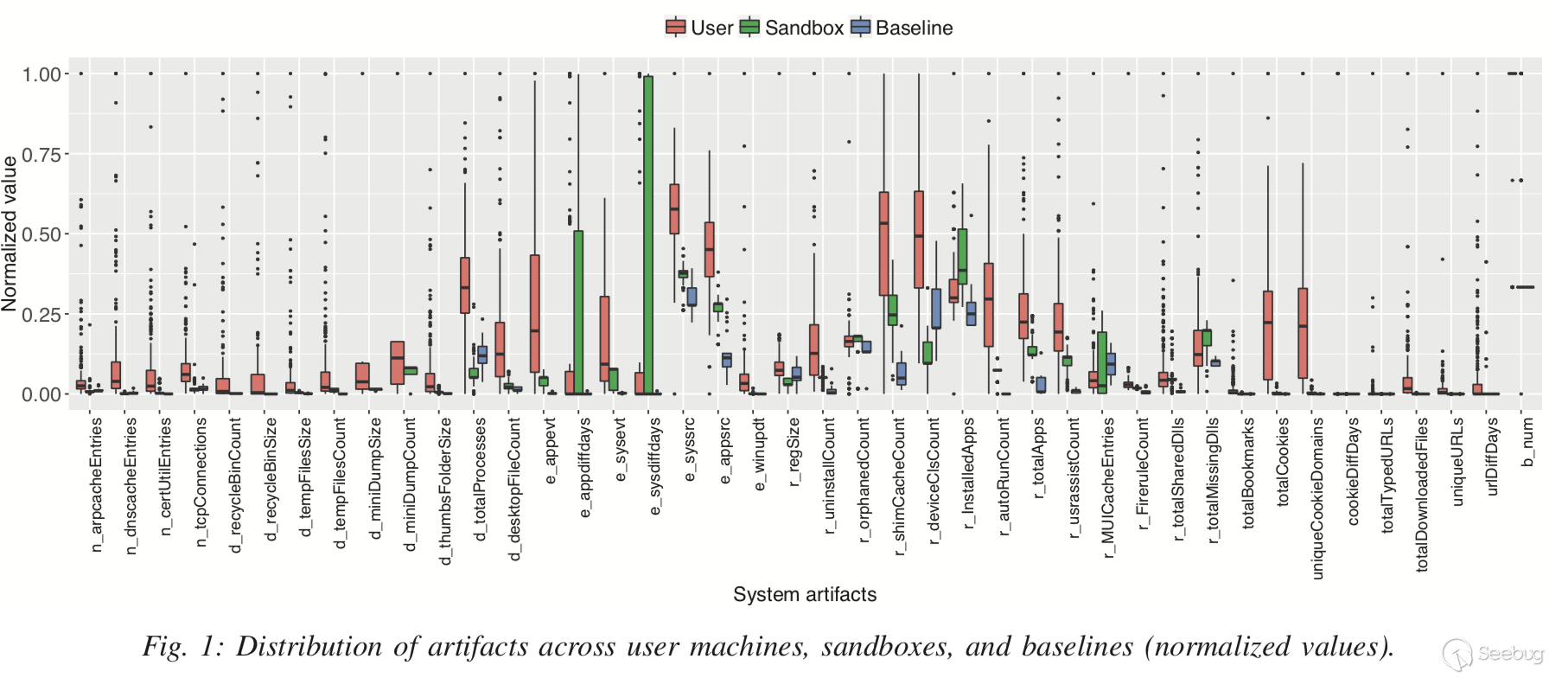
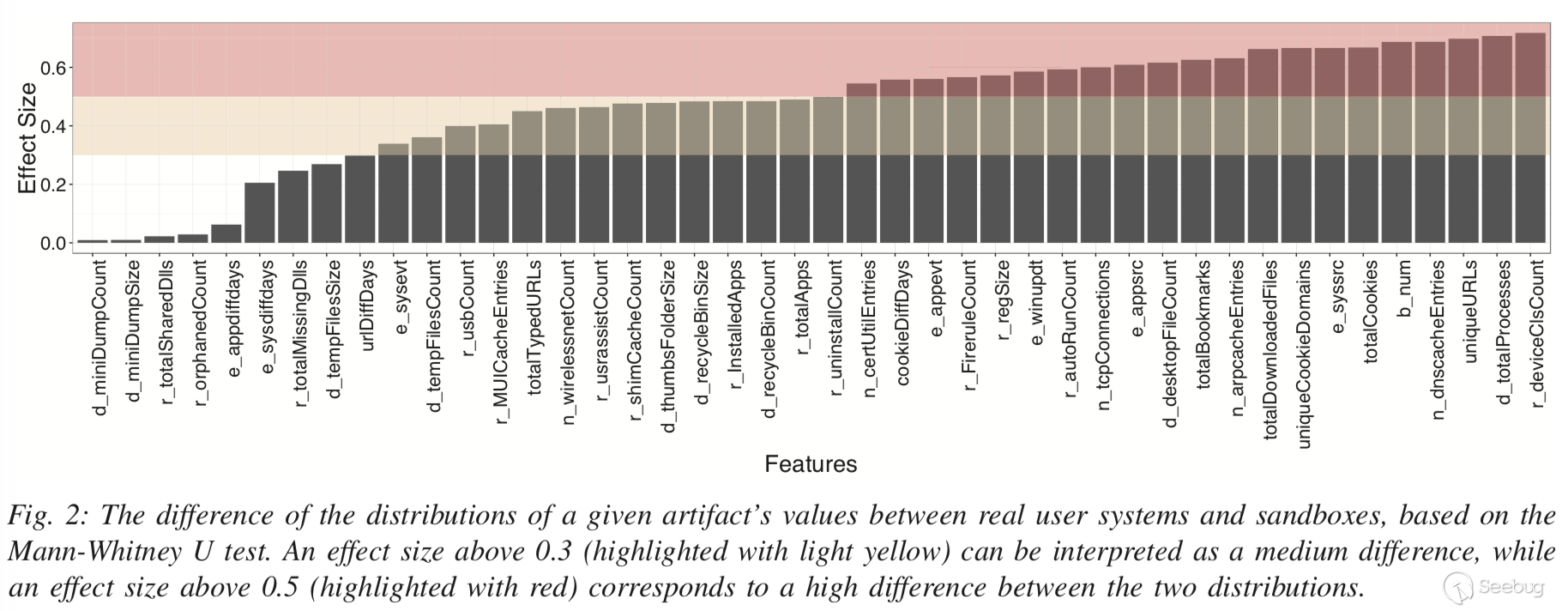
图2显示了Mann-Whitney U检验显示的Dreal和Dsand分布之间差异的影响大小。0.3和0.5之间的效果被认为是“中等”效应的特征,而高于0.5的效应被认为是“强”效应。
V. EVADING MALWARE SANDBOXES
以上的统计信息说明了作者所选用的artifact是可以作为特征来分辨沙箱的,因此接下来将使用有监督机器学习方式,训练决策树模型来进一步完成对沙箱的规避工作。
A. Setup and Classifier
- 使用决策树模型。因为决策树模型可以表现为一系列的if-else语句,从而将恶意软件的整体足迹保持在最小。
- 计算皮尔森相关系数(r)来检查特征对的相关性。虽然有4对特征具有很强的相关性(r> 0.7),但是为了尽可能的规避所有沙箱,作者还是采用了所有的特征。
- 训练集:49个沙箱环境实例,22个新安装操作系统的实例,71个真实用户实例;测试集:剩余的49个沙箱环境实例,49个真实用户随机样本。
- 使用10-trial adaptive boosting算法(创建多个树,每个树专注改进前一棵树的结果)和adaptive boosting决策树算法(覆盖单棵树不能到达的边界)来提升分类器准确性。
- 指定成本矩阵减少漏报的出现(原则是宁可不感染到某些真实用户,也尽量不能被沙箱捕获)。
PS: FP 误报->没有感染真实用户主机;FN 漏报->尝试感染沙箱
B. Evaluation
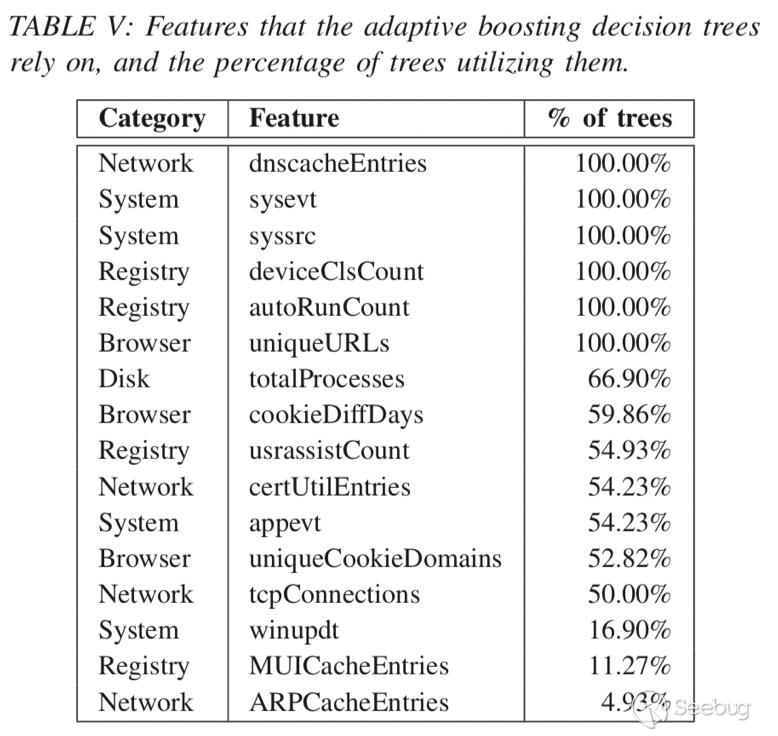
模型在测试集上达到了92.86%的准确率,假阴性率(FNR)为4.08%,假阳性率(FPR)为10.20%。 十个构建的树的平均树大小为4.6分裂,最短的树具有3个分裂,最长的树分裂为5个。 表V显示了对算法最有用的功能,以及使用任何给定功能的树的百分比。
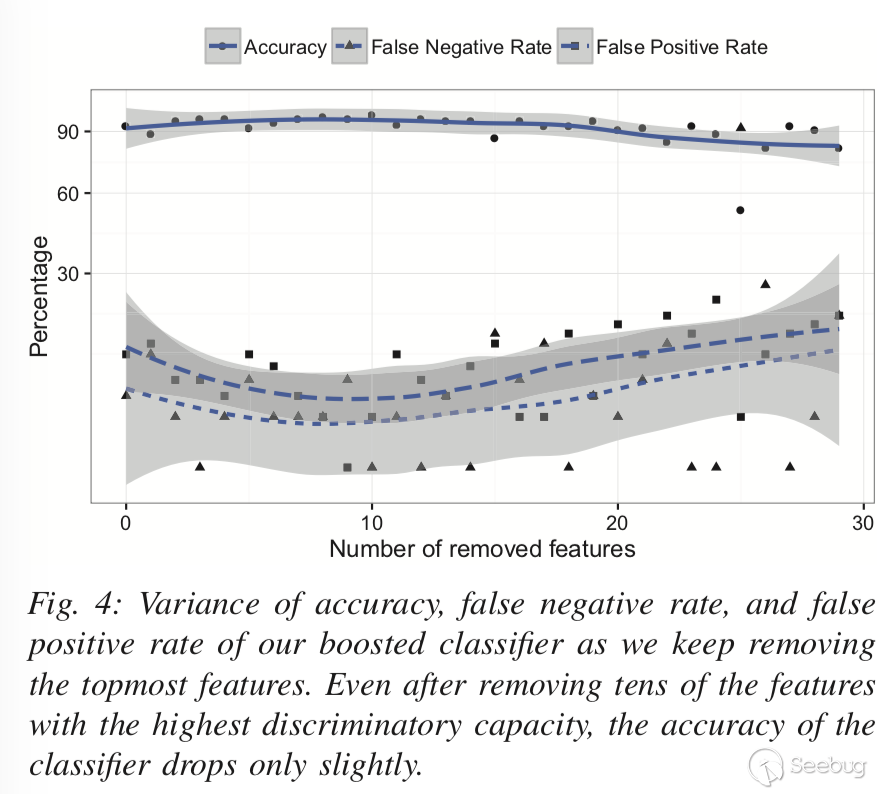
之后作者从两个思路出发:
一、评估我们的算法对沙盒环境中增量变化的稳健性
方法: 每次只删除一个特征,将以上分类器训练过程重复30次。
目的: 对于攻击者而言量化恶意软件区分沙箱和真实用户的能力;对于防御者而言可以使用在此处识别的最有价值的artifact磨损程度来模仿真实的用户系统。
效果: 图4显示了准确性,误报率和漏报率如何变化。可以看到即使删除多达20个特征,分类器的整体准确性仍高于90%。
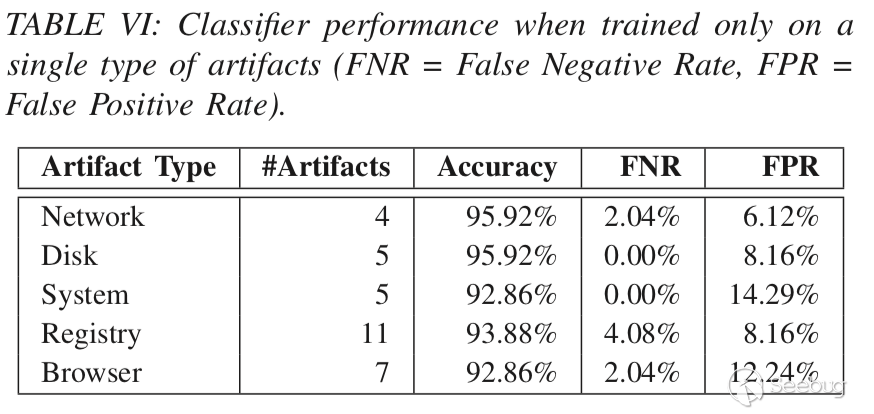
二、每种类型的工件如何影响分类器的准确性
方法: 一次仅使用一种类型的工件重新训练我们的模型。
目的: 让恶意软件作者可以选择他们想要关注的artifact类别,但这种选择不会影响恶意软件的规避能力。
效果: 表VI显示了每个类别的artifact数量以及每个分类器在测试数据集上的性能。
VI. ESTIMATING ACTUAL SYSTEM AGE
在之前的数据分析中,可以发现沙箱环境的“老化”程度与用户的真实环境是截然不同的。而且理论上“磨损”程度和“老化”程度应该是相匹配的,如果不匹配那么是沙箱的概率则很大。对于攻击者可以使用者一特点进行沙箱规避;对于防御者则可以对沙箱做更好的调整。
A. Correlation Between Age and Artifacts
目的: 得出artifact的磨损与系统年龄之间的关系
图5显示了用户系统和恶意软件沙箱“年龄”的累积分布函数。可以看到平均而言用户系统比沙箱更“新”。
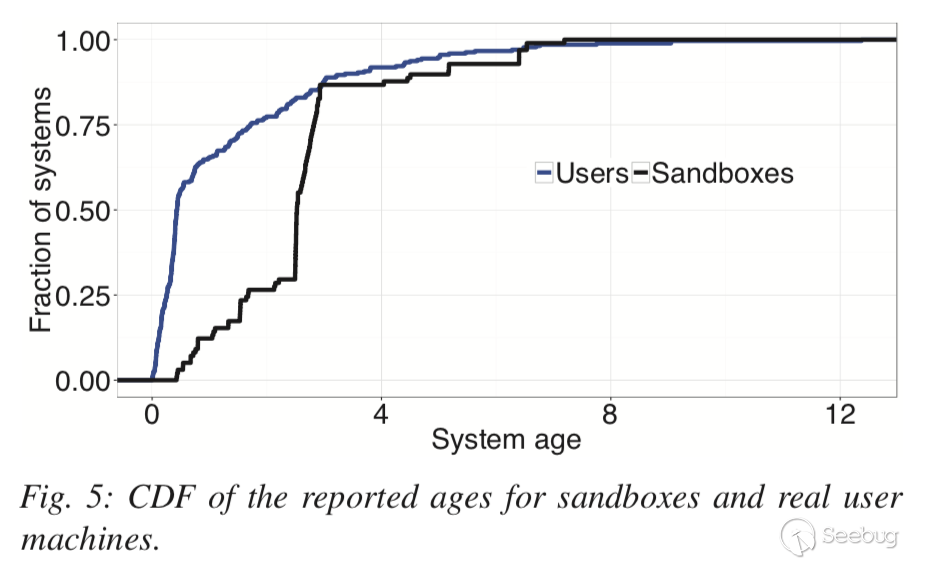
图6显示了报告的年龄与真实用户系统的每个artifact磨损程度之间的皮尔森相关系数。此处假设从真实用户系统收集的报告年龄是准确的。
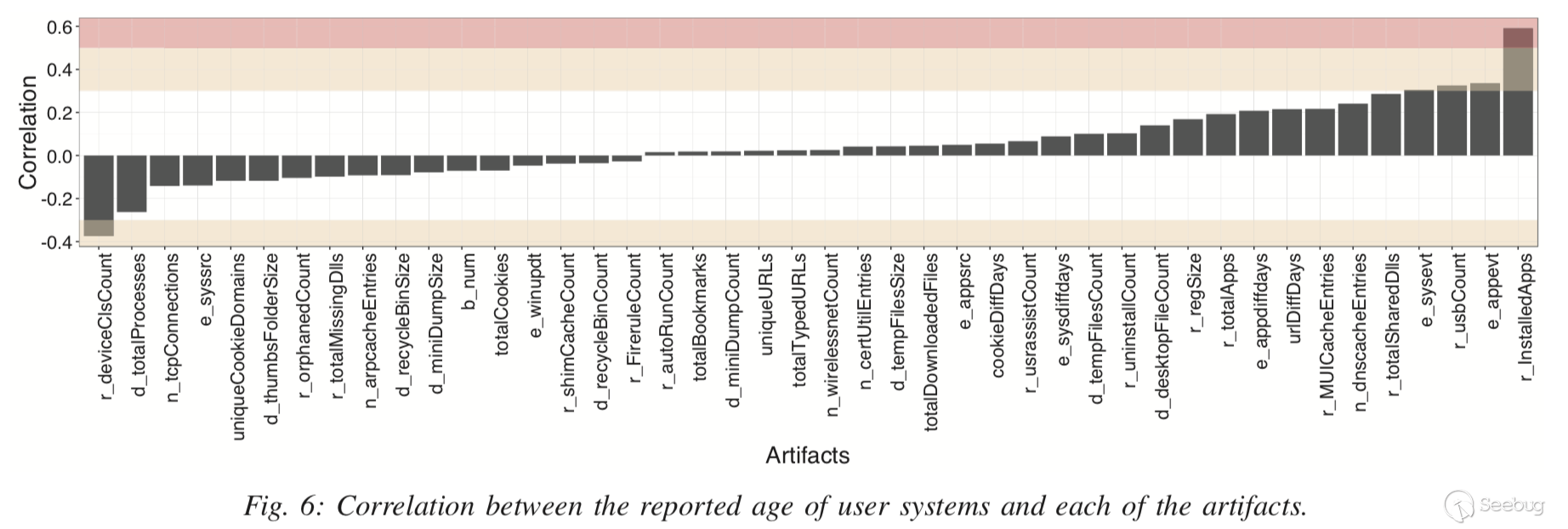
观测结果分析:
- 许多非常成功地区分真实机器和沙箱的工件实际上与机器的年龄无关;
- 一些与用户活动直接相关的artifact不能很好的反映系统的年龄,比如cookie的数量(用户可以主动清除);
- 一些不太容易被用户修改的artifact将跟系统年龄成正相关,比如连接过的USB数量。
B. Regression
目的: 确定组合它们的原始值来估计系统的实际年龄的合适方法。
数据集处理:
- 删除具有缺失值的artifact;
- 删除丢失率超过80%的artifact。
(1) Linear Regression:
- 公式: Y =β0+β1X1+β2X2+ … +ε (Xi是给定的artifact值,βi是对应的权重,Y是预测的年龄)
- 数据集: 训练(60%),测试(40%)
- 评估: 十折交叉验证
- 结果: 真实系统的预测年龄的最终均方误差(MSE)是1.88,而沙箱的MSE非常高,为6.25。
- 结论: 使用artifact的磨损程度来预测系统年龄是可行的,也就是说使用预测年龄和系统的生成年龄的对比来识别沙箱是可行的。
PS: 十折交叉验证,英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。
表VII中报告了模型的系数及其p值。 我们看到13种artifact磨损程度与机器的年龄相关,具有统计学意义。
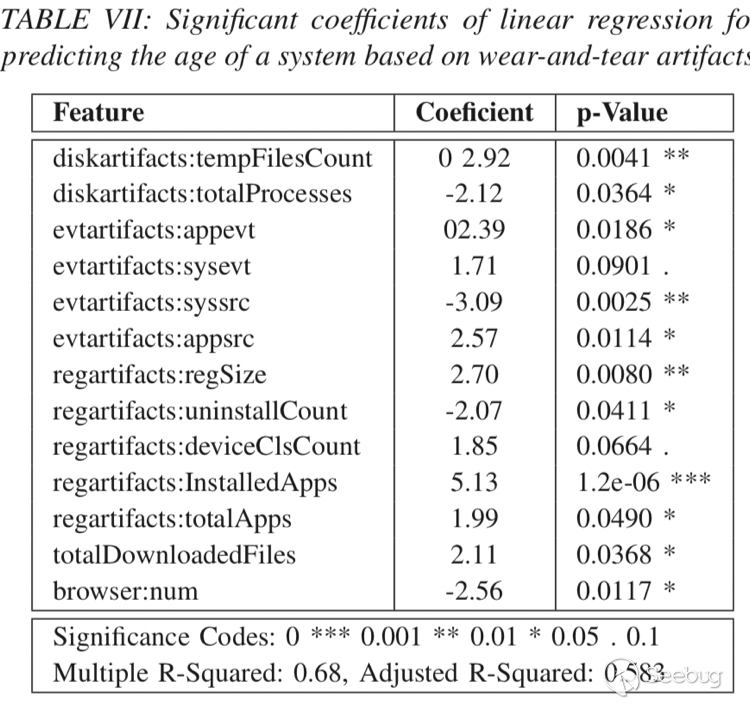
图7显示了在Dreal和Dsand系统上应用线性回归模型时残差值的累积分布函数(CDF)。可以看到在尝试预测沙箱年龄时的残差值是非常高的。
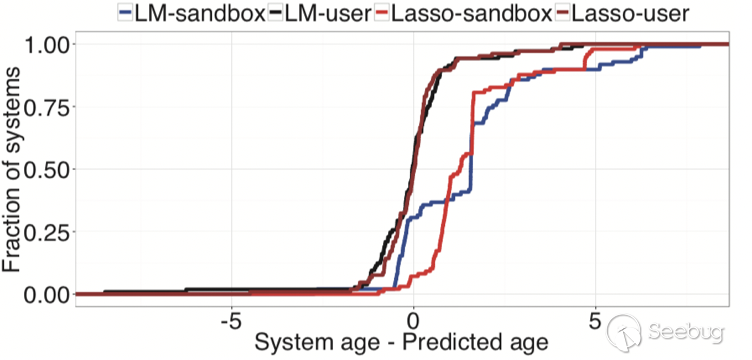
(2) Lasso Regression
- 目的: 验证复杂的回归模型是否会带来更好的预测准确性
- 套索回归的优点: 比线性回归使用更少的预测变量,这降低了整体模型的复杂性。 对于恶意软件,较小的功能集意味着对底层操作系统的API调用较少,从而减少了触发可疑活动监视器的机会。
- 数据集: 训练集,评估集和测试集
- 方法: 交叉验证来找到最佳的λ值
- 结果: Dreal集的MSE为0.749,Dsand集上的MSE为4.45,优于线性回归
- 结论: Lasso模型可以更好地辨别沙箱。
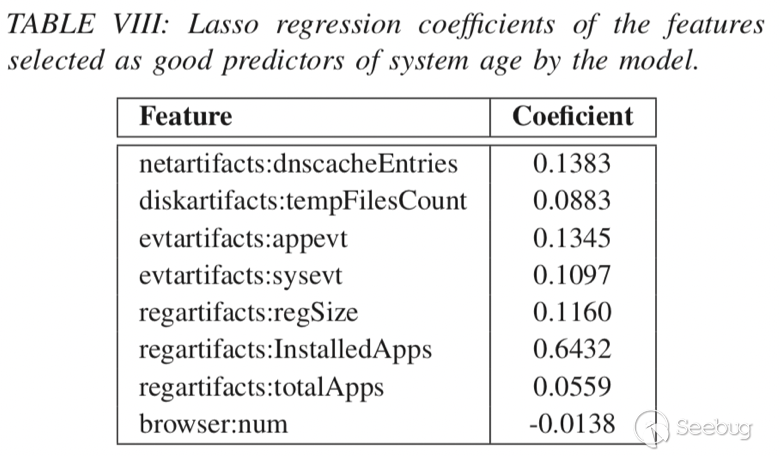
表VIII显示了Lasso模型选择的八个特征,它们是系统年龄及其相应系数的良好预测因子。
小结: 使用artifact磨损程度来预测系统年龄是可行的,这一方面可以用于辨识沙箱;另一方面是可以帮助sandbox开发人员创建系统年龄相符的沙箱环境
VII. DISCUSSION
A. Ethical Considerations and Coordinated Disclosure
本文主要讲述了这种新的规避技术的有效性,并且目前已经出现了此类相关工作的恶意软件。但是本文主要是为了帮助创建更强大的恶意软件分析系统。
B. Probing Stealthiness
- 总是存在不受监控的artifact集;
- 虽然最小特权原则造成的系统API调用限制,可访问的环境限制,但是依旧可以从其他不受限制的artifact集获取大量信息;
C. OS Dependability
文章虽然是基于Windows平台在进行artifact的分析,但其中的一些artifact并不是其特有的,在其它系统例如Linux,Mac,Android等也同样适用。如果想适用Java等编写跨平台的恶意软件,就可以去关注那些不依赖于特定系统而存在的artifact。
D. Defenses
克隆真实用户系统并将其用作恶意软件沙箱的基础。
缺点:
i) 隐私问题(如何在克隆之前或之后擦除所有私人信息,但保留磨损工件完整?);
ii) artifact的老化问题(攻击者可以使用我们提出的统计模型来检测声称的年龄与磨损程度不匹配的情况)。
从新安装的操作系统映像开始,通过自动模拟用户操作人为地使其老化。
缺点:尚不清楚这种人工老化在多大程度上会产生与真实系统相似的artifact情况。
VIII. CONCLUSION AND FUTURE WORK
本文主要做了两个方面工作:
- 攻击者角度:将Windows系统的一些不涉及用户隐私的artifact作为特征,使用决策树分类器进行训练,最终可以在92.86%的准确度上来识别沙箱环境。
- 防御者角度:将系统的artifact特征与系统的年龄进行联系并提出统计模型,从而帮助沙箱操作人员对系统进行微调,使其具有更逼真的磨损特性。
未来工作:
- 克隆真实用户系统并将其用作恶意软件沙箱的基础。
- 自动模拟用户操作人为地使系统其老化到所需程度。
- 不同的桌面操作系统以及移动设备中评估基于artifact磨损特性的沙盒规避的有效性。
以上是 Spotless Sandboxes->Evading Malware Analysis Systems using Wear-and-Tear Artifacts 的全部内容, 来源链接: utcz.com/p/199276.html