wget/curl问题
如果要批量下载一个url下的资源,用wget/curl/bash怎么实现?
譬如url="http://go.googlecode.com/files/"直接wget -r ${url}的话会出现
➜ golang wget -r https://go.googlecode.com/files/ --2014-10-14 06:02:40-- https://go.googlecode.com/files/
Resolving go.googlecode.com (go.googlecode.com)... 74.125.130.82, 2404:6800:4003:c01::52
Connecting to go.googlecode.com (go.googlecode.com)|74.125.130.82|:443... connected.
HTTP request sent, awaiting response... 404 Not Found
2014-10-14 06:02:40 ERROR 404: Not Found.
资源示例:"https://go.googlecode.com/files/go1.2.1.linux-amd64.tar.gz"
回答:
补充下结论吧:如果web服务器不提供一个一个目录下所有资源的汇总页面,是无法进行递归下载的
“wget -r”命令中参数r的解释确实如题主所说,可用于递归下载:
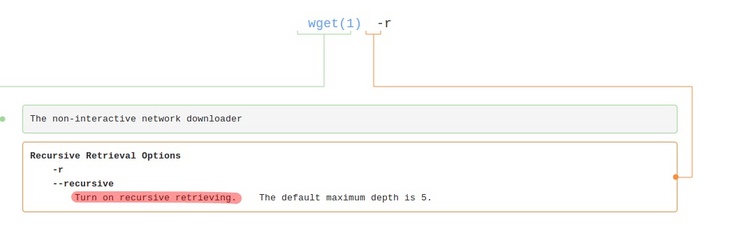
但执行完命令之后,确实遇到了和题主一样的窘境,授人以鱼不如授人以渔吧,题主可以通过使用strace跟踪wget命令的执行情况:(注:为了方便阅读http协议,这里将https替换成了http)
strace -s 3000 -tt -o strace.log wget -r http://go.googlecode.com/files/这里,也附上strace命令参数详解:点击我,谢谢
然后,vim打开strace.log: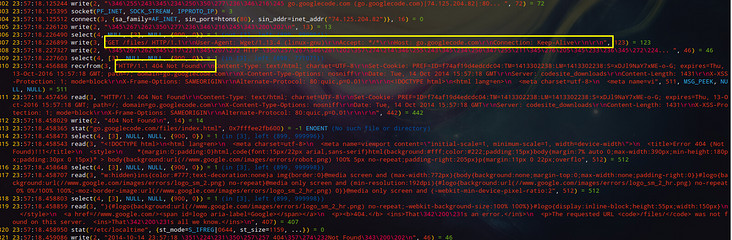
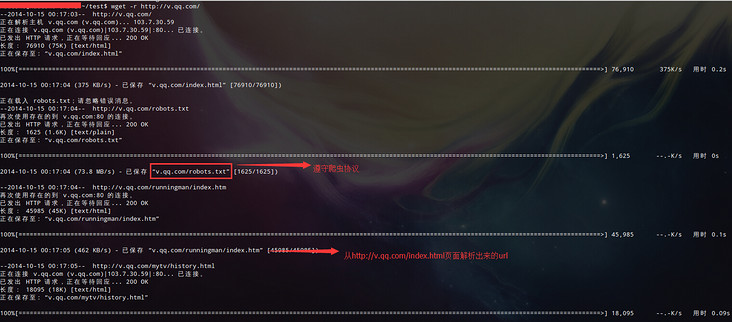
回答:
1楼说的非常的对,我来稍做补充吧。
为什么需要为个index.html呢?
基本的Web服务器都使用index.html来做为索引页,什么意思,就是只输入目录不输出文件就能出现的页面,这个我们叫它索引页。
因为这个文件里面列出了当前目录下所有文件的名称以及下载的URL地址,所以例如wget 这类的命令可以通过这里面获取访从哪里下载,有哪些文件需要下载的信息。
为什么服务器上会不存在index.html这个文件呢?
因为确实Nginx服务器上就没有这个文件,只有go1.2.1.linux-amd64.tar.gz,index.html可以是管理员手动写的一个文件,当然如果管理员没有手动写这个文件,那怎么办,Web服务器也提供了这个功能,就是如果你没有index.html的话我可以帮你写,但里里面的内容是当前目录下所有文件或目录的url链接信息。(这个功能的开启需要在服务器上开启,Apache 加上 Options Indexes Nginx加上:autoindex on;)
回答:
wget -m -np $url
以上是 wget/curl问题 的全部内容, 来源链接: utcz.com/p/193556.html