HTML(页面内容)转 PDF 问题 --itextsharp ?
使用版本itextsharp 5.5.4 itextsharp.xmlworker5.5.4
最终希望效果:http://html2pdf.seven49.net/en/Home/Default.htm
遇到的问题
对于自行写的简单的html 能成功转换成 pdf
而对于 复杂的网站界面就 无法实现了
主要报错原因是 html标签的不规范(严谨)
例如:
读取 http://segmentfault.com/u/izhinia
错误提示: iTextSharp.tool.xml.exceptions.RuntimeWorkerException: Invalid nested tag head found, expected closing tag link.
读取

报错:
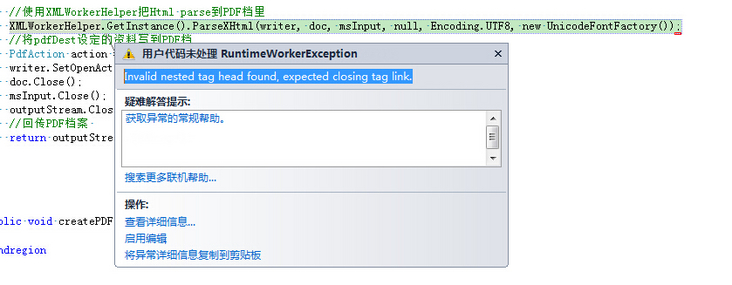
读取 http://www.afterlogic.com/mailbee-net/docs-itextsharp/
错误提示: iTextSharp.tool.xml.exceptions.RuntimeWorkerException: Invalid nested tag head found, expected closing tag link.
读取
Byte[] pageData = MyWebClient.DownloadData("http://www.baidu.com/"); //从指定网站下载数据

报错
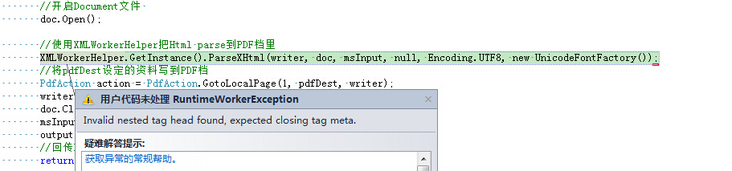
iTextSharp.tool.xml.exceptions.RuntimeWorkerException: Invalid nested tag head found, expected closing tag meta.
博客园我也创建了一个小组,下面是小组地址:
http://home.cnblogs.com/group/topic/71624.html
下面是我实现的代码和效果图(这里只实现了简单的html+css):
图片效果
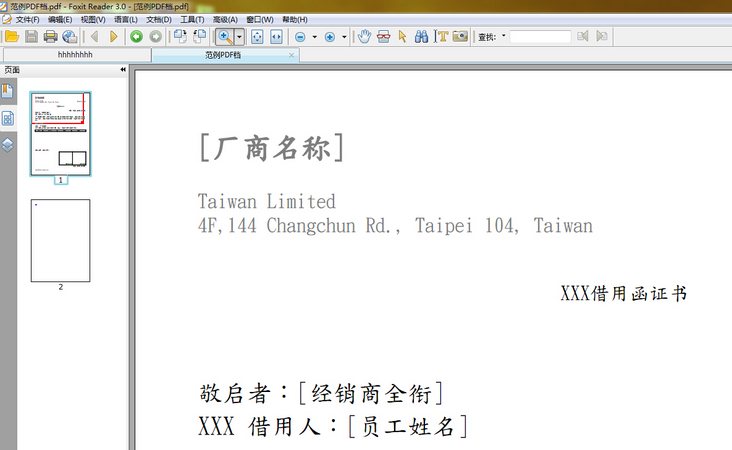
下面是我的代码:
/// <summary> /// 判断是否有乱码
/// </summary>
/// <param name="txt"></param>
/// <returns></returns>
public bool isMessyCode(string txt)
{
var bytes = Encoding.UTF8.GetBytes(txt); //239 191 189
for (var i = 0; i < bytes.Length; i++)
{
if (i < bytes.Length - 3)
if (bytes[i] == 239 && bytes[i + 1] == 191 && bytes[i + 2] == 189)
{
return true;
}
}
return false;
}
/// <summary>
/// 获取网站内容,包含了 HTML+CSS+JS
/// </summary>
/// <returns>String返回网页信息</returns>
public string getWebContent()
{
try
{
WebClient MyWebClient = new WebClient();
MyWebClient.Credentials = CredentialCache.DefaultCredentials;
//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = MyWebClient.DownloadData("D:\\test1.html");
//从指定网站下载数据
string pageHtml = Encoding.UTF8.GetString(pageData);
//如果获取网站页面采用的是GB2312,则使用这句
bool isBool = isMessyCode(pageHtml);//判断使用哪种编码 读取网页信息
if (!isBool)
{
string pageHtml1 = Encoding.UTF8.GetString(pageData);
pageHtml = pageHtml1;
}
else
{
string pageHtml2 = Encoding.Default.GetString(pageData);
pageHtml = pageHtml2;
}
return pageHtml;
}
catch (WebException webEx)
{
Console.WriteLine(webEx.Message.ToString());
return webEx.Message;
}
}
/// <summary>
/// 执行此Url,下载PDF档案
/// </summary>
/// <returns></returns>
public ActionResult DownloadPdf()
{
WebClient wc = new WebClient();
//从网址下载Html字串
wc.Encoding = System.Text.Encoding.UTF8;
string htmlText = getWebContent();
byte[] pdfFile = this.ConvertHtmlTextToPDF(htmlText);
return File(pdfFile, "application/pdf", "d:\\范例PDF档1.pdf");
}
/// <summary>
/// 将Html文字 输出到PDF档里
/// </summary>
/// <param name="htmlText"></param>
/// <returns></returns>
public byte[] ConvertHtmlTextToPDF(string htmlText)
{
if (string.IsNullOrEmpty(htmlText))
{
return null;
}
//避免当htmlText无任何html tag标签的纯文字时,转PDF时会挂掉,所以一律加上<p>标签
htmlText = "<p>" + htmlText + "</p>";
MemoryStream outputStream = new MemoryStream();//要把PDF写到哪个串流
byte[] data = Encoding.UTF8.GetBytes(htmlText);//字串转成byte[]
MemoryStream msInput = new MemoryStream(data);
Document doc = new Document();//要写PDF的文件,建构子没填的话预设直式A4
PdfWriter writer = PdfWriter.GetInstance(doc, outputStream);
//指定文件预设开档时的缩放为100%
PdfDestination pdfDest = new PdfDestination(PdfDestination.XYZ, 0, doc.PageSize.Height, 1f);
//开启Document文件
doc.Open();
//使用XMLWorkerHelper把Html parse到PDF档里
XMLWorkerHelper.GetInstance().ParseXHtml(writer, doc, msInput, null, Encoding.UTF8, new UnicodeFontFactory());
//将pdfDest设定的资料写到PDF档
PdfAction action = PdfAction.GotoLocalPage(1, pdfDest, writer);
writer.SetOpenAction(action);
doc.Close();
msInput.Close();
outputStream.Close();
//回传PDF档案
return outputStream.ToArray();
}
//设置字体类
public class UnicodeFontFactory : FontFactoryImp
{
private static readonly string arialFontPath = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.Fonts),
"arialuni.ttf");//arial unicode MS是完整的unicode字型。
private static readonly string 标楷体Path = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.Fonts),
"KAIU.TTF");//标楷体
public override Font GetFont(string fontname, string encoding, bool embedded, float size, int style, BaseColor color, bool cached)
{
BaseFont bfChiness = BaseFont.CreateFont(@"C:\Windows\Fonts\simhei.ttf", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
//可用Arial或标楷体,自己选一个
BaseFont baseFont = BaseFont.CreateFont(标楷体Path, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
return new Font(baseFont, size, style, color);
}
}
另外一种方法就是先把html的界面生成图片 ,然后用生成的图片来生成pdf 结果:情况效果图(不理想,达不到需求)代码就不贴了,如果需要,请私信!
回答:
http://stackoverflow.com/questions/564650/convert-html-to-pdf-in-net
回答:
跪求代码,邮箱625833348@qq.com
回答:
跪求代码,邮箱379314367@qq.com
回答:
上面报错应该是html标签没闭合或者不规范吧
回答:
跪求"先把html的界面生成图片 ,然后用生成的图片来生成pdf 结果"的代码,邮箱410251819@qq .com
以上是 HTML(页面内容)转 PDF 问题 --itextsharp ? 的全部内容, 来源链接: utcz.com/p/189980.html