【Java】Springboot2.x整合ElasticSearch7.x实战(三)
大概阅读10分钟
本教程是系列教程,对于初学者可以对 ES 有一个整体认识和实践实战。
还没开始的同学,建议先读一下系列攻略目录:Springboot2.x整合ElasticSearch7.x实战目录
本篇幅是继上一篇 Springboot2.x整合ElasticSearch7.x实战(二) ,适合初学 Elasticsearch 的小白,可以跟着整个教程做一个练习。
[toc]
第五章 Mapping详解
Mapping 是整个 ES 搜索引擎中最重要的一部分之一,学会构建一个好的索引,可以让我们的搜索引擎更高效,更节省资源。
什么是 Mapping?
Mapping 是Elasticsearch 中一种术语, Mapping 类似于数据库中的表结构定义 schema,它有以下几个作用:
1. 定义索引中的字段的名称2. 定义字段的数据类型,比如字符串、数字、布尔
3. 字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position(位置) 等
在 ES 早期版本,一个索引下是可以有多个 Type ,从 7.0 开始,一个索引只有一个 Type,也可以说一个 Type 有一个 Mapping 定义。
了解了什么是 Mapping 后,接下来对 Mapping 的设置坐下介绍:
Maping设置
dynamic (动态Mapping)
官网参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.1/mapping.html
PUT users{
"mappings": {
"_doc": {
"dynamic": false
}
}
}
在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。
")
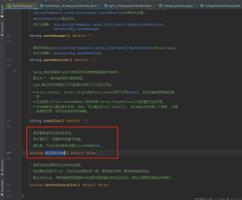
比如一个新的文档,这个文档包含一个字段,当 Dynamic 设置为 true 时,这个文档可以被索引进 ES,这个字段也可以被索引,也就是这个字段可以被搜索,Mapping 也同时被更新;当 dynamic 被设置为 false 时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃;当设置成 strict 模式时候,数据写入直接出错。
index
另外还有 index 参数,用来控制当前字段是否被索引,默认为 true,如果设为 false(有些业务场景,某些字段不希望被搜索到),则该字段不可被搜索。
# index属性控制 字段是否可以被索引PUT user_test
{
"mappings": {
"properties": {
"firstName":{
"type": "text"
},
"lastName":{
"type": "text"
},
"mobile" :{
"type": "text",
"index": false
}
}
}
}
index_options
")
参数 index_options 用于控制倒排索引记录的内容,有如下 4 种配置:
- doc:只记录 doc id
- freqs:记录 doc id 和 term frequencies
- positions:记录 doc id、term frequencies 和 term position
- offsets:记录 doc id、term frequencies、term position 和 character offects
另外,text 类型默认配置为 positions,其他类型默认为 doc,记录内容越多,占用存储空间越大。
null_value
null_value 主要是当字段遇到 null 值时的处理策略,默认为 NULL,即空值,此时 ES 会默认忽略该值,可以通过设定该值设定字段的默认值,另外只有 KeyWord 类型支持设定 null_value。
- 示例
# 设定Null_valueDELETE users
PUT users
{
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text"
},
"lastName" : {
"type" : "text"
},
"mobile" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
PUT users/_doc/1
{
"firstName":"Zhang",
"lastName": "Fubing",
"mobile": null
}
PUT users/_doc/2
{
"firstName":"Zhang",
"lastName": "Fubing2"
}
# 查看结果,有且仅有_id为2的记录
GET users/_search
{
"query": {
"match": {
"mobile":"NULL"
}
}
}
_all
这个属性现在使用很少,不做深入讲解
参考官网:https://www.elastic.co/guide/...
copy_to
这个属性用于将当前字段拷贝到指定字段。
- _all在7.x版本已经被copy_to所代替
- 可用于满足特定场景
- copy_to将字段数值拷贝到目标字段,实现类似_all的作用
- copy_to的目标字段不出现在_source中
DELETE usersPUT users
{
"mappings": {
"properties": {
"firstName":{
"type": "text",
"copy_to": "fullName"
},
"lastName":{
"type": "text",
"copy_to": "fullName"
}
}
}
}
PUT users/_doc/1
{
"firstName":"Li",
"lastName": "Sunke"
}
//没有新建字段
GET users/_doc/1
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"firstName" : "Li",
"lastName" : "Sunke"
}
}
GET users/_search?q=fullName:(Li sunke)
以前的用法是:
curl -XPUT 'localhost:9200/my_index?pretty' -H 'Content-Type: application/json' -d'{
"mappings": {
"my_type": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name" # 1
},
"last_name": {
"type": "text",
"copy_to": "full_name" # 2
},
"full_name": {
"type": "text"
}
}
}
}
}
'
curl -XPUT 'localhost:9200/my_index/my_type/1?pretty' -H 'Content-Type: application/json' -d'
{
"first_name": "John",
"last_name": "Smith"
}
'
curl -XGET 'localhost:9200/my_index/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"full_name": { # 3
"query": "John Smith",
"operator": "and"
}
}
}
}
'
- first_name(名字)和 last_name(姓氏)字段复制到full_name 字段;
- first_name(名字)和 last_name(姓氏)字段仍然可以分别查询;
- full_name 可以通过 first_name(名字)和 last_name(姓氏)来查询;
一些要点:
- 复制的是字段值,而不是 term(词条)(由分析过程产生).
- _source 字段不会被修改来显示复制的值.
- 相同的值可以复制到多个字段,通过 "copy_to": [ "field_1", "field_2" ] 来操作.
分词器analyzer和arch_analyzer
PUT /my_index{
"mappings": {
"properties": {
"text": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
}
}
}
}
}
}
#使用_analyze 测试分词器
GET my_index/_analyze
{
"field": "text",
"text": "The quick Brown Foxes."
}
GET my_index/_analyze
{
"field": "text.english",
"text": "The quick Brown Foxes."
}
构建Mapping方式
我们知道 Mapping 是可以通过我们插入的文档自动生成索引,但是可能还是有一些问题。例如:生成的字段类型不正确,字段的附加属性不满足我们的需求。这是我们可以通过显式Mapping的方式来解决。俩种方法:
- 参考官网api,纯手写
- 构建临时索引;写入一些样本数据;通过Maping API 查询临时文件的动态Mapping 定义;修改后、再使用此配置创建索引;删除临时索引;
推荐第二种,不容易出错,效率高。
类型自动识别
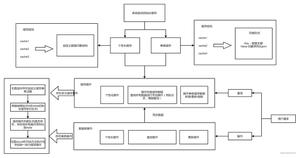
ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:
")
- Demo:
# 写入文档,查看 MappingPUT mapping_test/_doc/1
{
"firstName": "Chan", -- Text
"lastName": "Jackie", -- Text
"loginDate": "2018-07-24T10:29:48.103Z" -- Date
}
# Dynamic Mapping,推断字段的类型
PUT mapping_test/_doc/1
{
"uid": "123", -- Text
"isVip": false, -- Boolean
"isAdmin": "true", -- Text
"age": 19, -- Long
"heigh": 180 -- Long
}
# 查看 Dynamic Mapping
GET mapping_test/_mapping
映射参数
")
mappings 中field定义选择:
"field": {"type": "text", //文本类型
"index": "false"// ,设置成false,字段将不会被索引
"analyzer":"ik"//指定分词器
"boost":1.23//字段级别的分数加权
"doc_values":false//对not_analyzed字段,默认都是开启,analyzed字段不能使用,对排序和聚合能提升较大性能,节约内存,如果您确定不需要对字段进行排序或聚合,或者从script访问字段值,则可以禁用doc值以节省磁盘空间:
"fielddata":{"loading" : "eager" }//Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
"fields":{"keyword": {"type": "keyword","ignore_above": 256}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
"include_in_all":ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
"index_options":"docs"//4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
"norms":{"enable":true,"loading":"lazy"}//分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
"null_value":"NULL"//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
"position_increament_gap":0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
"store":false//是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
"search_analyzer":"ik"//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
"similarity":"BM25"//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
"term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
}
总结一下:
- 与域数据格式及约束相关的参数:normalizer,format,ignore_above,ignore_malformed,coerce
- 与索引相关的参数:index,dynamic,enabled
- 与存储策略相关的参数:store, fielddata,doc_values
- 分析器相关参数:analyzer,search_analyzer
- 其它参数:boost,copy_to,null_value
对于这些参数的描述主要基于笔者的理解,可能有不准确之处。实际上这些参数与ES的实现机制(如存储结构,索引结构密切有关),只能在实际应用中去慢慢体会。
字段数据类型
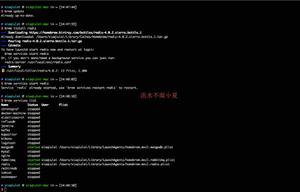
ES 字段类型类似于 MySQL 中的字段类型,ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型,具体的数据类型如下图所示:
")
核心类型
从图中可以看出核心类型可以划分为字符串类型、数字类型、日期类型、布尔类型、基于 BASE64 的二进制类型、范围类型。
字符串类型
其中,在 ES 7.x 有两种字符串类型:text 和 keyword,在 ES 5.x 之后 string 类型已经不再支持了。
text 类型适用于需要被全文检索的字段,例如新闻正文、邮件内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。
keyword 适合简短、结构化字符串,例如主机名、姓名、商品名称等,可以用于过滤、排序、聚合检索,也可以用于精确查询。
数字类型
数字类型分为 long、integer、short、byte、double、float、half_float、scaled_float。
数字类型的字段在满足需求的前提下应当尽量选择范围较小的数据类型,字段长度越短,搜索效率越高,对于浮点数,可以优先考虑使用 scaled_float 类型,该类型可以通过缩放因子来精确浮点数,例如 12.34 可以转换为 1234 来存储。
日期类型
在 ES 中日期可以为以下形式:
格式化的日期字符串,例如 2020-03-17 00:00、2020/03/17
时间戳(和 1970-01-01 00:00:00 UTC 的差值),单位毫秒或者秒
即使是格式化的日期字符串,ES 底层依然采用的是时间戳的形式存储。
布尔类型
JSON 文档中同样存在布尔类型,不过 JSON 字符串类型也可以被 ES 转换为布尔类型存储,前提是字符串的取值为 true 或者 false,布尔类型常用于检索中的过滤条件。
二进制类型
二进制类型 binary 接受 BASE64 编码的字符串,默认 store 属性为 false,并且不可以被搜索。
范围类型
范围类型可以用来表达一个数据的区间,可以分为5种:integer_range、float_range、long_range、double_range 以及 date_range。
复杂类型
复合类型主要有对象类型(object)和嵌套类型(nested):
对象类型
JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档:
{"name": {
"first": "wu",
"last": "px"
}
}
实际上 ES 会将其转换为以下格式,并通过 Lucene 存储,即使 name 是 object 类型:
{"name.first": "wu",
"name.last": "px"
}
嵌套类型
嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档:
{"group": "users",
"username": [
{ "first": "wu", "last": "px"},
{ "first": "hu", "last": "xy"},
{ "first": "wu", "last": "mx"}
]
}
username 字段是一个 JSON 数组,并且每个数组对象都是一个 JSON 对象。如果将 username 设置为对象类型,那么 ES 会将其转换为:
{"group": "users",
"username.first": ["wu", "hu", "wu"],
"username.last": ["px", "xy", "mx"]
}
可以看出转换后的 JSON 文档中 first 和 last 的关联丢失了,如果尝试搜索 first 为 wu,last 为 xy 的文档,那么成功会检索出上述文档,但是 wu 和 xy 在原 JSON 文档中并不属于同一个 JSON 对象,应当是不匹配的,即检索不出任何结果。
嵌套类型就是为了解决这种问题的,嵌套类型将数组中的每个 JSON 对象作为独立的隐藏文档来存储,每个嵌套的对象都能够独立地被搜索,所以上述案例中虽然表面上只有 1 个文档,但实际上是存储了 4 个文档。
地理类型
地理类型字段分为两种:经纬度类型和地理区域类型:
经纬度类型
经纬度类型字段(geo_point)可以存储经纬度相关信息,通过地理类型的字段,可以用来实现诸如查找在指定地理区域内相关的文档、根据距离排序、根据地理位置修改评分规则等需求。
地理区域类型
经纬度类型可以表达一个点,而 geo_shape 类型可以表达一块地理区域,区域的形状可以是任意多边形,也可以是点、线、面、多点、多线、多面等几何类型。
特殊类型
特殊类型包括 IP 类型、过滤器类型、Join 类型、别名类型等,在这里简单介绍下 IP 类型和 Join 类型,其他特殊类型可以查看官方文档。
IP 类型
IP 类型的字段可以用来存储 IPv4 或者 IPv6 地址,如果需要存储 IP 类型的字段,需要手动定义映射:
{"mappings": {
"properties": {
"my_ip": {
"type": "ip"
}
}
}
}
Join类型
Join 类型是 ES 6.x 引入的类型,以取代淘汰的 _parent 元字段,用来实现文档的一对一、一对多的关系,主要用来做父子查询。
Join 类型的 Mapping 如下:
PUT my_index{
"mappings": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
其中,my_join_field 为 Join 类型字段的名称;relations 指定关系:question 是 answer 的父类。
例如定义一个 ID 为 1 的父文档:
PUT my_join_index/1?refresh{
"text": "This is a question",
"my_join_field": "question"
}
接下来定义一个子文档,该文档指定了父文档 ID 为 1:
PUT my_join_index/_doc/2?routing=1&refresh{
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
join参考:https://www.elastic.co/guide/...
以上是 【Java】Springboot2.x整合ElasticSearch7.x实战(三) 的全部内容, 来源链接: utcz.com/a/96480.html