【Java】我所知道的十大常用算法之克鲁斯尔算法(最小生成树)
前言需求
今天我们学习的是克鲁斯尔算法,我们还是从一个场景里引入看看
")
有7个村庄(A, B, C, D, E, F, G) ,现在需要修路把7个村庄连通
1.各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里
问:如何修路保证各个村庄都能连通,并且总的修建公路总里程最短?
一、什么是克鲁斯尔算法?
克鲁斯卡尔(Kruskal)算法:用来求加权连通图的最小生成树的算法。
基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路
具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止
那么什么是回路?接下来请看示例解析
二、通过示例来认识算法
在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树
")
那么我们根据G4这张图来看看有哪些不同连接方式
")
")
")
举例出来的三张图代表了G4有多种的不同连接方式,说明是多样化的
那么什么时候是最小生成树呢?
就是众多连接方式中里:最小的,则成为最优的,是最小生成树
图解思路分析克鲁斯尔算法
我们以上图G4举例,来使用克鲁斯尔算法进行演示
假设:我们当前使用数组R来保存最小的生成树结果
第一步:选取G4图中最小的权值边E-F开始,因为它的权值为2
")
第二步:选取G4图中第二小的权值边C-D,因为它的权值为3
")
第三步:选取G4图中第三小的权值边D-E,因为它的权值为4
")
这时我们选取G4图中第四小的权值边C-E,因为它的权值为5
")
这时我们选取G4图中第五小的权值边C-F,因为它的权值为6
")
我们发现这会造成回路,但是什么是回路?我们先来分析看看
当我们将E-F、C-D、D-E加入到数组R中时,这几条边都有了终点
关于终点的说明:
一、将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是"与它连通的最大顶点"。
- C的终点是F
- D的终点是F
- E的终点是F
- F的终点是F
")
二、之前<C,E>虽然是权值最小的边,但是C和E的终点都是F,即它们的终点相同。
我们加入的边的两个顶点不能都指向同一个终点,否则将构成回路。
若将<C,E>加入最小生成树的话,会形成回路。这就是判断回路的方式。
第四步:选取G4图中第六小的权值边B-F,因为它的权值为7
")
第五步:选取G4图中第七小的权值边E-G,因为它的权值为8
")
这时我们选取G4图中第八小的权值边F-G,因为它的权值为9
")
这时我们选取G4图中第九小的权值边F-G,因为它的权值为10
")
第六步:选取G4图中第十小的权值边A-B,因为它的权值为12
")
权值12、14会造成回路,至此最小生成树构造完成
它包括的边依次是:<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>
克鲁斯算法思路小结
根据前面的图解算法,我们能够了解到,克鲁斯卡尔算法重点需要解决的以下两个问题:
问题一:对图的所有边按照权值大小进行排序。
问题二:将边添加到最小生成树中时,怎么样判断是否形成了回路。
克鲁斯算法代码思路
1.使用邻接矩阵来表示图所之间连接关系与权重值")
")
//使用邻接矩阵描述权重值表示0 代表无int[][] weight = new int[][]{
{00,12,00,00,00,16,14},
{12,00,10,00,00,07,00},
{00,10,00,00,05,06,00},
{00,00,03,00,04,00,00},
{00,00,05,04,00,02,08},
{16,07,06,00,02,00,09},
{14,00,00,00,00,07,00}
};
2.需要一个存放顶点的char数组
//char[] 数组存放顶点个数char[] data = new char[]{'A','B','C','D','E','F','G'};
3.创建对象存放节点数据、邻接矩阵、节点个数
public class KruskaCase {private int edgeNum;//表示边个数
private char[] data;//存放结点数据
private int[][] weight;//存放邻接矩阵
//用来代替00 表示不能连通
private static final int INF = Integer.MAX_VALUE;
}
4.创建初始化方法将存放顶点的数组与矩阵初始化
public class KruskaCase {//....省略关键代码
public KruskaCase(char[] vertexs,int[][] matrix) {
//初始化顶点个数和边的个数
int len = vertexs.length;
//初始化顶点存放数组
this.data = new char[len];
for(int i = 0; i<len; i++){
this.data[i] = vertexs[i];
}
//初始化邻接矩阵
this.weight = new int[len][len];
for (int i =0;i<len;i++){
for (int j =0; j<len;j++){
this.weight[i][j] = matrix[i][j];
}
}
//统计边的个数
for (int i =0;i<len;i++){
for (int j = i+1; j<len;j++){
if(matrix[i][j]!=INF){
edgeNum++;
}
}
}
}
//打印矩阵信息
public void printShow(){
for (int i =0;i<data.length;i++){
for (int j =0; j<data.length;j++){
System.out.printf("%10d",weight[i][j]);
}
System.out.println();
}
}
}
接下来我们使用demo 完成图的创建与输出
public static void main(String[] args) {//char[] 数组存放顶点个数
char[] data = new char[]{'A','B','C','D','E','F','G'};
int[][] weight ={
{0,12,INF,INF,INF,16,14},
{12,0,10,INF,INF,7,INF},
{INF,10,0,INF,5,6,INF},
{INF,INF,3,0,4,INF,INF},
{INF,INF,5,4,0,02,8},
{16,7,6,INF,2,0,9},
{14,INF,INF,INF,INF,7,0}
};
KruskaCase kruskaCase = new KruskaCase(data,weight);
kruskaCase.printShow();
}
")
")
刚刚问题一:对图的所有边按照权值大小进行排序
所以我们需要创建一个边的对象保存一个点、另一个点、权值
class Edata{char start;//边的一个点
char end;//边的另一个点
int weight;//权值
public Edata(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public String toString() {
return "Edata{" +"start=" + start +", end=" + end +", weight=" + weight +'}';
}
}
举个例子比如:A-B/B-A 这两条边 做示范
")
我们这里统计上图所中的边数方法,还需要讲解一下
//统计边的个数for (int i =0;i<len;i++){
for (int j = i+1; j<len;j++){
if(matrix[i][j]!=INF){
edgeNum++;
}
}
}
第二个for为什么要从j = i+1 开始呢,这里其实可以看我画的矩阵图
")
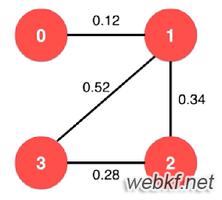
我们从G4 这张图里呢,能数的出来其实是十二条边,那么我们怎么得到?
如果从每个位置都获取一遍,那么就会出现问题,可以看看下面代码
//统计边的个数for (int i =0;i<len;i++){
for (int j = 0; j<len;j++){
if(matrix[i][j]!=INF){
edgeNum++;
}
}
}
这种方法会将A-B、B-A都统计进来,就会变成24条边。但其实他们是一条边
")
所以我们只需要i+1 采用红色斜线开始统计,这样就可以统计出来了
")
接下来我们使用冒泡解决问题一,当然你回顾:往期文章
对比不同的排序方式,选择你喜欢的方式进行排序
总而言之就是将他们的权值值进行从小到大的排序
class KruskaCase{//...省略之前关键代码
private void sortEdges(Edata[] edata){
for (int i =0;i<edata.length -1;i++){
for (int j =0; j<edata.length -1 -i;j++){
if(edata[j].weight>edata[j+1].weight){
Edata temp = edata[j];
edata[j] = edata[j+1];
edata[j+1] = temp;
}
}
}
}
}
现在我们有了边的对象,也有排序的方法,但是没有组合边的数组方法
我们需要将(A-B,或者B-A)权值为12 这样的边对象存放到一个数组中
class KruskaCase{//省略之前关键代码....
private Edata[] getEdata(){
int index = 0;
//根据统计的边条数存放节点
Edata[] edata = new Edata[edgeNum];
for (int i = 0; i<data.length;i++){
for (int j = i+1; j<data.length;j++){
if(weight[i][j] !=INF){
edata[index++] = new Edata(data[i],data[j],weight[i][j]);
}
}
}
return edata;
}
}
为什么是j = i + 1 ?
因为我们上面讲过不要避免重复统计,A-B/B-A 只需要统计一遍即可
为什么weighti !=INF?
因为我们上面采用INF来代表它们之前不可连通,我们需要连通的边
接下来我们采用Demo将G4图中的矩阵,转换成边数组输出看看
public static void main(String[] args) {//char[] 数组存放顶点个数
char[] data = new char[]{'A','B','C','D','E','F','G'};
int[][] weight ={
{0,12,INF,INF,INF,16,14},
{12,0,10,INF,INF,7,INF},
{INF,10,0,INF,5,6,INF},
{INF,INF,3,0,4,INF,INF},
{INF,INF,5,4,0,02,8},
{16,7,6,INF,2,0,9},
{14,INF,INF,INF,INF,7,0}
};
KruskaCase kruskaCase = new KruskaCase(data,weight);
//kruskaCase.printShow();//输出G4图的矩阵
System.out.println(Arrays.toString(kruskaCase.getEdata()));
}
运行结果如下:
[Edata{start=A, end=B, weight=12},
Edata{start=A, end=F, weight=16},
Edata{start=A, end=G, weight=14},
Edata{start=B, end=C, weight=10},
Edata{start=B, end=F, weight=7},
Edata{start=C, end=E, weight=5},
Edata{start=C, end=F, weight=6},
Edata{start=D, end=E, weight=4},
Edata{start=E, end=F, weight=2},
Edata{start=E, end=G, weight=8},
Edata{start=F, end=G, weight=9}]
但是我们没有解决完第一个问题,我们来看看是什么?
问题一:对图的所有边按照权值大小进行排序
根据我们的输出结果说明我们还需要将其进行排序,从小到大
public static void main(String[] args) {//char[] 数组存放顶点个数
char[] data = new char[]{'A','B','C','D','E','F','G'};
int[][] weight ={
{0,12,INF,INF,INF,16,14},
{12,0,10,INF,INF,7,INF},
{INF,10,0,INF,5,6,INF},
{INF,INF,3,0,4,INF,INF},
{INF,INF,5,4,0,02,8},
{16,7,6,INF,2,0,9},
{14,INF,INF,INF,INF,7,0}
};
KruskaCase kruskaCase = new KruskaCase(data,weight);
//kruskaCase.printShow();//输出G4图的矩阵
Edata[] edata = kruskaCase.getEdata();
kruskaCase.sortEdges(edata);//进行排序
System.out.println(Arrays.toString(edata));
}
运行结果如下:
[Edata{start=E, end=F, weight=2},
Edata{start=D, end=E, weight=4},
Edata{start=C, end=E, weight=5},
Edata{start=C, end=F, weight=6},
Edata{start=B, end=F, weight=7},
Edata{start=E, end=G, weight=8},
Edata{start=F, end=G, weight=9},
data{start=B, end=C, weight=10},
Edata{start=A, end=B, weight=12},
Edata{start=A, end=G, weight=14},
Edata{start=A, end=F, weight=16}]
至此我们解决了第一个问题,接下来我们需要看看第二个问题
问题二:将边添加到最小生成树中时,怎么样判断是否形成了回路。
我们的处理思路方式是:
1.选择一条边的时候,求这条边的终点
2.将这条边的终点与最小生成树的终点进行重合判断,重合则回路
比如说我们之前的将E-F、C-D、D-E加入到数组R中时,这几条边都有了终点
- C的终点是F
- D的终点是F
- E的终点是F
- F的终点是F
")
当我们放入C-E的时候,我们需要求终点是什么点
这样就可以判断加入的边的两个顶点的终点是否与最小生成树里的终点重合
//获取传入下标为i的顶点的终点(),用于后面判断两个顶点的终点是否相同//ends 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成
private int getEnd(int[] ends,int i){
while (ends[i]!=0){
i = ends[i];
}
return i;
}
我们的思路是传入顶点的下标,那么就需要一个方法返回对应的顶点下标
public int getPosition(char ch){for (int i =0;i<data.length;i++){
if(data[i] == ch){
return i;//找到返回该下标
}
}
return -1;//代表找不到;
}
那么获取传入下标为i的顶点的终点,这个方法是什么意思?
会不会有小伙伴说这写的是什么?我怎么看不懂?
不急,我们进行举例分析讲解,为什么是这样
")
我们以当前的这个图,来举例说明分析讲解
根据前面的分析,我们也知道了图共有12条边
我们创建一个数组来保存每个顶点在最小生成树中的终点,初始化为0
int[] ends = new int[edgeNum]; //十二条边edgeNum=12我们创建一个数组来保存最小生成树中
EData[] rets= new EData[ edgeNum] ;//保存最小生成树那么我们对应的边集合对象是不是这样获取的呀?
//获取图中所有边的集合,一共有12边Edata[] edges =getEdges();
//进行从小到大的排序
sortEdges(edges);
我们回过头来看看当时的图解思路步骤第一步添加E-F 这条边
")
带入进我们之前的边集合是Edata{start=E, end=F, weight=2}
这时我们的E、F在我们之前数组中的下标位置是什么?
//原数组传入进来//char[] data = new char[]{'A','B','C','D','E','F','G'};
int p1 = getPosition('E');//下标为4
int p2 = getPosition('F');//下标为5
这时我们调用方法求他们的终点,不满足while条件则代表终点是自己
int m1 = getEnd(ends,p1);//E的终点是自个int m2 = getEnd(ends,p2);//F的终点是自个
然后我们需要判断E与F是否构成回路,没有则赋值新的终点
if(m!=n){ends[m]=n;
rets[0] = E-F;
}
这就表示E顶点在ends数组中,它的终点为:F顶点(下标)
同时我们最小生成树下标[0] 等于我们选中的E-F边
现在有没有一点点思路明白之前获取传入下标为i的顶点的终点的方法
")
")
这时一样,先获取顶点下标,在获取他们对应的终点是什么
若是不相等则赋值为新的终点
接下来我们分析一下这步骤,为什么我们能知道他们对应的顶点是
- C的终点是F
- D的终点是F
- E的终点是F
- F的终点是F
假如我们加入的C-F,这时候我们需要先找到C、F的下标
int p1 = getPosition('C');//下标为2int p2 = getPosition('F');//下标为5
这时我们调用方法求他们的终点,不满足while条件则代表终点是自己
int m1 = getEnd(ends,p1);//E的终点是自个int m2 = getEnd(ends,p2);//F的终点是自个
当我们传入m1下标的时候,它满足while条件则进行循环判断
")
会不断指向新的终点,直至不满足while条件判断,返回对应的终点下标
")
这就是为什么C的终点指向F,D的终点也指向F
现在你懂这两个辅助方法是什么意思了吗?
我们将这两个辅助方法,放入KruskaCase 类中,开始我们的算法编写
三、克鲁斯算法代码编写
public void kruskal(){int[] ends = new int[edgeNum];//用于保存顶点的终点
Edata[] rets = new Edata[edgeNum];//用于保存最小生成树的边
Edata[] edata = getEdata();//获取所有边的集合
sortEdges(edata);//将边集合排序
//System.out.println("图的边集合 =>"+Arrays.toString(edata));
int index = 0;//最小生成树边的下标
//遍历edata数组,将边添加到最小生成树中
for (int i = 0; i<edgeNum;i++){
//获取第i条边的一个顶点的下标
int p1 = getPosition(edata[i].start);
//获取第i条边的另一个顶点的下标
int p2 = getPosition(edata[i].start);
//获取p1的顶点的终点
int m = getEnd(ends,p1);
//获取p2的顶点的终点
int n = getEnd(ends,p2);
if(m!=n){
ends[m] = n;
rets[index++] = edata[i];
}
}
System.out.println("最小生成树为:");
for (int i = 0; i<index;i++){
System.out.println(rets[i]);
}
}
接下来我们使用demo测试看看,输出结果看看
public static void main(String[] args) {//char[] 数组存放顶点个数
char[] data = new char[]{'A','B','C','D','E','F','G'};
int[][] weight ={
{0,12,INF,INF,INF,16,14},
{12,0,10,INF,INF,7,INF},
{INF,10,0,INF,5,6,INF},
{INF,INF,3,0,4,INF,INF},
{INF,INF,5,4,0,02,8},
{16,7,6,INF,2,0,9},
{14,INF,INF,INF,INF,7,0}
};
KruskaCase kruskaCase = new KruskaCase(data,weight);
kruskaCase.printShow();//输出G4图的矩阵
kruskaCase.kruskal();
}
运行结果如下:
最小生成树为:
Edata{start=E, end=F, weight=2}
Edata{start=D, end=E, weight=4}
Edata{start=C, end=E, weight=5}
Edata{start=B, end=F, weight=7}
Edata{start=E, end=G, weight=8}
Edata{start=A, end=B, weight=12}
求最小生成树的相关文章算法
- 普里姆算法:最小生成树
参考资料
- 尚硅谷:数据结构与算法(韩顺平老师):克鲁斯尔算法
以上是 【Java】我所知道的十大常用算法之克鲁斯尔算法(最小生成树) 的全部内容, 来源链接: utcz.com/a/96180.html