【Java】【Kafka】实战(二)Kafka使用 Producer 发送消息及 Consumer 接收消息消费
一、Kafka的Producer
Producer就是用于向Kafka发送数据。如下:
1、添加依赖:
<dependency><groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
2、发送消息
2.1 启动kafka(Kafka shell命令)
[[email protected] ~]# kafka-server-start.sh -daemon /opt/lns/server.properties2.2 创建topic:kb09two,3个分区,每个分区有1个副本
[[email protected] ~]# kafka-topics.sh --create --zookeeper 192.168.247.201:2181 --topic kb09two --partitions 3 --replication-factor 1[[email protected] ~]# kafka-topics.sh --zookeeper 192.168.247.201:2181 --list
2.3 创建生产者(Java代码)
public class MyProducer {public static void main(String[] args) {
Properties prop = new Properties();
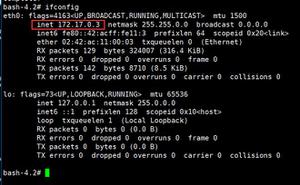
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.247.201:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
prop.put(ProducerConfig.ACKS_CONFIG,"-1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
for (int i = 0; i < 200; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("kb09two", "hello world" + i);
producer.send(producerRecord);
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("game over");
}
}
执行Java代码,发送消息
2.4 查看消息队列中每个分区中的数量(Kafka shell命令)
[[email protected] ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.247.201:9092 --topic kb09two --time -1 --offsets 1Kafka使用 Producer 发送消息及 Consumer 接收消息消费")
2.5 消费消息(Kafka shell命令)
[[email protected] ~]# kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic kb09two --from-beginningKafka使用 Producer 发送消息及 Consumer 接收消息消费")
补充内容
kafka 客户端 producer 配置参数Kafka使用 Producer 发送消息及 Consumer 接收消息消费")
Kafka使用 Producer 发送消息及 Consumer 接收消息消费")
二、Consumer概要
consumer中的关键术语:
消费者(consumer):从kafka中拉取数据并进行处理
消费者组(consumer group):一个消费者组由一个或者多个consumer实例组成
位移(offset):记录当前分区消费数据的位置
位移提交(offset commit):将消费完成的消息的最大offset提交确认
位移topic(_consumer_offset):保存消费位移的topic
1.消费方式:(poll/push)
Kafka Consumer采用的是主动拉取broker数据进行消费的。一般消息中间件存在推送(server推送数据给consumer)和拉取(consumer主动取服务器取数据)两种方式,这两种方式各有优劣。
如果是选择推送的方式最大的阻碍就是服务器不清楚consumer的消费速度,如果consumer中执行的操作又是比较耗时的,那么consumer可能会不堪重负,甚至会导致系统挂掉。
而采用拉取的方式则可以解决这种情况,consumer根据自己的状态来拉取数据,可以对服务器的数据进行延迟处理。但是这种方式也有一个劣势就是服务器没有数据的时候可能会一直轮询,不过还好Kafka在poll()有参数允许消费者请求在“长轮询”中阻塞,等待数据到达(并且可选地等待直到给定数量的字节可用以确保传输大小)。
2.Consumer常用参数说明
Kafka使用 Producer 发送消息及 Consumer 接收消息消费")
3.Consumer程序开发
构建Consumer
Consumer有三种消费交付语义
1、至少一次:消息不会丢失,但可能被重复处理(实现简单)
2、最多一次:消息可能丢失可能会被处理,但最多只会被处理一次(实现简单)
3、精确一次:消息被处理并且只会被处理一次(比较难实现)
一个消费者组G1里只有一个消费者(单线程)
public class MyConsumer {public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.247.201:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 消息key反序列化器
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);// 消息value反序列化器
prop.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,"30000"); // 消费者和群组协调器的最大心跳时间
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); // 设置手动提交方式
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); // 自动提交的时间
// 当消费者读取偏移量无效的情况下,需要重置消费起始位置,默认为latest(从消费者启动后生成的记录),另外一个选项值是 earliest,将从有效的最小位移位置开始消费
// (1)earliest ,会从该分区当前最开始的offset消息开始消费(即从头消费),如果最开始的消息offset是0,那么消费者的offset就会被更新为0.
// (2)latest,只消费当前消费者启动完成后生产者新生产的数据。旧数据不会再消费。offset被重置为分区的HW。
// (3)none,启动消费者时,该消费者所消费的主题的分区没有被消费过,就会抛异常。
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
prop.put(ConsumerConfig.GROUP_ID_CONFIG,"G1"); // 标识一个consumer组的名称
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
consumer.subscribe(Collections.singleton("kb09two"));
// 一个消费者组G1里只有一个消费者(单线程)
while (true){
ConsumerRecords<String, String> poll = consumer.poll(100);
for (ConsumerRecord<String, String> record : poll) {
System.out.println(record.offset()+"t"+record.key()+"t"+record.value());
}
}
模拟多消费者在同一个消费组G2(多线程)
public class MyConsumer {public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.247.201:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 消息key反序列化器
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);// 消息value反序列化器
prop.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,"30000"); // 消费者和群组协调器的最大心跳时间
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); // 设置手动提交方式
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); // 自动提交的时间
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
prop.put(ConsumerConfig.GROUP_ID_CONFIG,"G2");
// 模拟多消费者在同一个消费组G2(多线程)
for (int i = 0; i < 4; i++) {
new Thread(new Runnable() {
@Override
public void run() {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
consumer.subscribe(Collections.singleton("kb09two"));
while (true){
ConsumerRecords<String, String> poll = consumer.poll(100);
for (ConsumerRecord<String, String> record : poll) {
System.out.println(Thread.currentThread().getName()+"t"+
record.offset()+"t"+ record.key()+"t"+ record.value());
}
}
}
}).start();
}
}
}
以上是 【Java】【Kafka】实战(二)Kafka使用 Producer 发送消息及 Consumer 接收消息消费 的全部内容, 来源链接: utcz.com/a/92150.html