【Java】图解多线程
关注“Java后端技术全栈”
回复“面试”获取全套面试资料
进程与线程
「进程」
进程的本质是一个正在执行的程序,程序运行时系统会创建一个进程,并且「给每个进程分配独立的内存地址空间,用来保证每个进程地址不会相互干扰」。
同时,在 CPU 对进程做时间片的切换时,保证进程切换过程中仍然要从进程切换之前运行的位置处开始执行。所以进程通常还会包括程序计数器、堆栈指针。
相对好理解点的案例:电脑上开启QQ就是开启一个进程、打开IDEA就是开启一个进程、浏打开览器就是开启一个进程.....
当我们的电脑开启你太多的运用(QQ,微信,浏览器、PDF、word、IDEA等)后,电脑就很容易出现卡顿,甚至死机,这里最主要原因就是CPU一直不停地切换导致的。
下图是单核CPU情况下,多进程之间的切换:

有了进程以后,可以让操作系统从宏观层面实现多应用并发。
而并发的实现是通过 CPU 时间片不端切换执行的,对于单核 CPU来说,在任意一个时刻只会有一个进程在被CPU 调度。
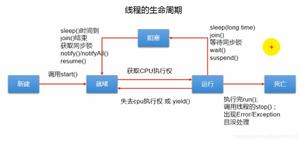
线程的生命周期
既然是生命周期,那么就很有可能会有阶段性的或者状态的,比如人的一生一样:
线程状态
关于线程的生命周期网上有不一样的答案,有说五种也有说六种。
Java中线程确实有6种,这是有理有据的,可以看看java.lang.Thread类中有个这么一个枚举。
public enum State { NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
这就是Java线程对应的状态,组合起来就是Java中一个线程的生命周期。下面是这个枚举的注释:

每种状态简单说明:
- NEW(初始):线程被创建后尚未启动。
- RUNNABLE(运行):包括了操作系统线程状态中的Running和Ready,也就是处于此状态的线程可能正在运行,也可能正在等待系统资源,如等待CPU为它分配时间片。
- BLOCKED(阻塞):线程阻塞于锁。
- WAITING(等待):线程需要等待其他线程做出一些特定动作(通知或中断)。
- TIME_WAITING(超时等待):该状态不同于WAITING,它可以在指定的时间内自行返回。
- TERMINATED(终止):该线程已经执行完毕。
线程生命周期

借用网上的这张图,这张图描述的很清楚了,这里就不在啰嗦。
何为线程安全?
我们经常会听说某个类是线程安全,某个类不是线程安全的。那么究竟什么叫做线程安全呢?
我们引用《Java Concurrency in Practice》里面的定义:
也可以这么理解:
可以简单的理解为:“你随便怎么调用,出了问题算我输”。
这个定义对于类来说是十分严格的,即使是Java API中标为线程安全的类也很难满足这个要求。
比如Vector是标记为线程安全的,但实际上并不能满足这个条件,举个例子:
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{ public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
//....基本上所有方法都是synchronized修饰的
}
来看下面一个案例:
判断Vector中第0个元素是不是空字符,如果是空字符就将其删除。
package com.java.tian.blog.utils;import java.util.Vector;
public class SynchronizedDemo{
static Vector<String> vct = new Vector<String>();
public void remove() {
if("".equals(vct.get(0))) {
vct.remove(0);
}
}
public static void main(String[] args) {
vct.add("");
SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
new Thread(new Runnable() {
@Override
public void run() {
synchronizedDemo.remove();
}
},"线程1").start();
new Thread(new Runnable() {
@Override
public void run() {
synchronizedDemo.remove();
}
},"线程2").start();
}
}
上面的逻辑看起来没有问题,实际上是有可能导致错误的:假设第0个元素是空字符,判断的时候得到的结果是true。

两个线程同时执行上面的remove方法,(「极端的情况」)都「可能」get到的是"",然后都去删除第0个元素,这个元素有可能已经被其它线程删除了,因此Vector不是绝对线程安全的。(上面这个案例只是做演示而已,在你的业务代码里面这么写的话,线程安全真的就不能靠Vector来保证了)。
通常情况下我们说的线程安全都是相对线程安全,相对线程安全只要求调用单个方法的时候不需要同步就可以得到正确的结果,但数多个方法组合调用的时候也是有可能导致多线程问题的。
如果想让上面的操作执行正确,我们需要在调用Vector方法的时候添加额外的同步操作:
package com.java.tian.blog.utils;import java.util.Vector;
public class SynchronizedDemo {
static Vector<String> vct = new Vector<String>();
public void remove() {
synchronized (vct) {
//synchronized (SynchronizedDemo.class) {
if ("".equals(vct.get(0))) {
vct.remove(0);
}
}
}
public static void main(String[] args) {
vct.add("");
SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
new Thread(new Runnable() {
@Override
public void run() {
synchronizedDemo.remove();
}
}, "线程1").start();
new Thread(new Runnable() {
@Override
public void run() {
synchronizedDemo.remove();
}
}, "线程2").start();
}
}
根据Vector的源代码可知:Vector的每个方法都使用了synchronized关键字修饰,因此锁对象就是这个对象本身。在上面的代码中我们尝试获取的也是vct对象的锁,可以和vct对象的其它方法互斥,因此这样做可以保证得到正确的结果。
如果Vector内部使用的是其它锁同步的,并封装了锁对象,那么我们无论如何都无法正确执行这个“先判断后修改”的操作。
假设被封装的对象锁为obj,get()和remove()方法对应的锁都是obj,而整个操作过程获取的是vct的锁,一个线程调用get()方法成功后就释放了obj的锁,这时这个线程只持有vct的锁,而其它线程可以获得obj的锁并抢先一步删除了第0个元素。
Java为开发者提供了很多强大的工具类,这些工具类里面有的是线程安全的,有的不是线程安全的。在这里我们列举几个面试常考的:
线程安全的类:Vector、Hashtable、StringBuffer
非线程安全的类:ArrayList、HashMap、StringBuilder
有人可能会反问:为什么Java不把所有的类都设计成线程安全的呢?这样对于我们开发者来说岂不是更爽吗?我们就不用考虑什么线程安全问题了。
事情都是具有两面性的,获得线程安全但是性能会有所下降,毕竟锁的开销是摆在那里的。线程不安全但是性能会有所提升,具体场景还得看业务更偏向于哪一个。
一个问题引发的思考:
public class SynchronizedDemo { static int count;
public void incre() {
try {
//每个线程都睡一会,模仿业务代码
Thread.sleep(100 );
} catch (InterruptedException e) {
e.printStackTrace();
}
count++;
}
public static void main(String[] args) {
SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
synchronizedDemo.incre();
}
}).start();
}
try {
//让主线程等待所有线程执行完毕
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count);
}
}
上面这段代码输出的结果是不确定的,结果是小于等于1000。

1000线程都去对count进行++操作。
对象内存布局
对象在内存中的存储可以分为 3 块区域,分别是对象头、实例数据和对齐填充。
其中,对象头包括两部分内容,一部分是对象本身的运行时数据,像 GC 分代年龄、哈希码、锁状态标识等等,官方称之为“Mark Word”,如果忽略压缩指针的影响,这部分数据在 32 位和 64 位的虚拟机中分别占 32 位和 64 位。
但是对象需要存储的运行时数据很多,32 位或者 64 位都不一定能存的下,考虑到虚拟机的空间效率,这个 Mark Word 被设计成一个非固定的数据结构,它会根据对象的状态复用自己的存储空间,对象处于不同状态的时候,对应的 bit 表示的含义可能会不一样,见下图,以 32 位 Hot Spot 虚拟机为例:

从上图中我们可以看出,如果对象处于未锁定状态(无锁态),那么 Mark Word 的 25 位用于存储对象的哈希码,4 位用于存储对象分代年龄,1 位固定为 0,两位用于存储锁标志位。
这个图对于理解后面提到的轻量级锁、偏向锁是非常重要的,当然我们现在可以先着重考虑对象处于重量级锁状态下的情况,也就是锁标志位为 10。同时我们看到,无锁态和偏向锁状态下,2 位锁标志位都是“01”,留有 1 位表示是否可偏向,我们姑且叫它“偏向位”。
「注」:对象头的另一部分则是类型指针,虚拟机可以通过这个指针来确认该对象是哪个类的实例。但是我们要注意,并不是所有的虚拟机都必须以这种方式来确定对象的元数据信息。对象的访问定位一般有句柄和直接指针两种,如果使用句柄的话,那么对象的元数据信息可以直接包含在句柄中(当然也包括对象实例数据的地址信息),也就没必要将这些元数据和实例数据存储在一起了。至于实例数据和对齐填充,这里暂不做讨论。
前面我们提到了,Java 中的每个对象都与一个 monitor 相关联,当锁标志位为 10 时,除了 2bit 的标志位,指向的就是 monitor 对象的地址(还是以 32 位虚拟机为例)。这里我们可以翻阅一下 OpenJDK 的源码,如果我们需要下载openJDK的源码:

找到。这里先看一下markOpp.hpp文件。该文件的相对路径为:
openjdkhotspotsrcsharevmoops下图是文件中的注释部分:

我们可以看到,其中描述了 32 位和 64 位下 Mark World 的存储状态。也可以看到64位下,前25位是没有使用的。
我们也可以看到 markOop.hpp 中定义的锁状态枚举,对应我们前面提到的无锁、偏向锁、轻量级锁、重量级锁(膨胀锁)、GC 标记等:
enum { locked_value = 0,//00 轻量级锁 unlocked_value = 1,//01 无锁
monitor_value = 2,//10 重量级锁
marked_value = 3,//11 GC标记
biased_lock_pattern = 5 //101 偏向锁,1位偏向标记和2位状态标记(01)
};
从注释中,我们也可以看到对其的简要描述,后面会我们详细解释:
这里我们的重心还是是重量级锁,所以我们看看源码中 monitor 对象是如何定义的,对应的头文件是 objectMonitor.hpp,文件路径为:
openjdkhotspotsrcsharevmruntime我们来简单看一下这个 objectMonitor.hpp 的定义:
// initialize the monitor, exception the semaphore, all other fields // are simple integers or pointers
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,//等待线程数
_recursions = 0;//重入次数
_object = NULL;
_owner = NULL;//持有锁的线程(逻辑上,实际上除了THREAD,还可能是Lock Record)
_WaitSet = NULL;//线程wait之后会进入该列表
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;//等待获取锁的线程列表,和_EntryList配合使用
FreeNext = NULL ;
_EntryList = NULL ;//等待获取锁的线程列表,和_cxq配合使用
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;//当前持有者是否为THREAD类型,如果是轻量级锁膨胀而来,还没有enter的话,
//_owner存储的可能会是Lock Record
_previous_owner_tid = 0;
}
简单的说,当多个线程竞争访问同一段同步代码块时,如果线程获取到了 monitor,那么就会把 _owner 设置成当前线程,如果是重入的话,_recursions 会加 1,如果获取 monitor 失败,则会进入 _cxq队列。
锁被释放时,_cxq中的线程会被移动到 _EntryList中,并且唤醒_EntryList 队首线程。当然,选取唤醒线程有几个不同的策略(Knob_QMode),还是后面结合源码解析。
「注」:_cxq和 _EntryList本质上是ObjectWaiter 类型,它本质上其实是一个双向链表 (具有前后指针),只是在使用的时候不一定要当做双向链表使用,比如 _cxq 是当做单向链表使用的,_EntryList是当做双向链表使用的。
什么场景会导致线程的上下文切换?
导致线程上下文切换的有两种类型:

自发性上下文切换是指线程由 Java 程序调用导致切出,在多线程编程中,执行调用上图中的方法或关键字,常常就会引发自发性上下文切换。
非自发性上下文切换指线程由于调度器的原因被迫切出。常见的有:线程被分配的时间片用完,虚拟机垃圾回收导致或者执行优先级的问题导致。
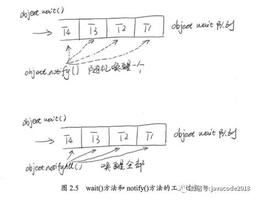
waity /notify

注意两个队列:
- 等待队列:notifyAll/notify唤醒的就是等待队列中的线程;
- 同步线程:就是竞争锁的所有线程,等待队列中的线程被唤醒后进入同步队列。
sleep与wait的区别
sleep
- 让当前线程休眠指定时间。
- 休眠时间的准确性依赖于系统时钟和CPU调度机制。
- 不释放已获取的锁资源,如果sleep方法在同步上下文中调用,那么其他线程是无法进入到当前同步块或者同步方法中的。
- 可通过调用interrupt()方法来唤醒休眠线程。
- sleep是Thread里的方法

wait
- 让当前线程进入等待状态,当别的其他线程调用notify()或者notifyAll()方法时,当前线程进入就绪状态
- wait方法必须在同步上下文中调用,例如:同步方法块或者同步方法中,这也就意味着如果你想要调用wait方法,前提是必须获取对象上的锁资源
- 当wait方法调用时,当前线程将会释放已获取的对象锁资源,并进入等待队列,其他线程就可以尝试获取对象上的锁资源。
- wait是Object中的方法


乐观锁、悲观锁、可重入锁.....
作为一个Java开发多年的人来说,肯定多多少少熟悉一些锁,或者听过一些锁。今天就来做一个锁相关总结。

悲观锁和乐观锁
悲观锁
顾名思义,他就是很悲观,把事情都想的最坏,是指该锁只能被一个线程锁持有,如果A线程获取到锁了,这时候线程B想获取锁只能排队等待线程A释放。
在数据库中这样操作:
select user_name,user_pwd from t_user for update;乐观锁
顾名思义,乐观,人乐观就是什么是都想得开,船到桥头自然直。乐观锁就是我都觉得他们都没有拿到锁,只有我拿到锁了,最后再去问问这个锁真的是我获取的吗?是就把事情给干了。
典型的代表:CAS=Compare and Swap 先比较哈,资源是不是我之前看到的那个,是那我就把他换成我的。不是就算了。
在Java中java.util.concurrent.atomic包下面的原子变量就是使用了乐观锁的一种实现方式CAS实现。
通常都是 使用version、时间戳等来比较是否已被其他线程修改过。
使用悲观锁还是使用乐观锁?
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
「响应效率」
如果需要非常高的响应速度,建议采用乐观锁方案,成功就执行,不成功就失败,不需要等待其他并发去释放锁。乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
「冲突频率」
如果冲突频率非常高,建议采用悲观锁,保证成功率。冲突频率大,选择乐观锁会需要多次重试才能成功,代价比较大。「重试代价」
如果重试代价大,建议采用悲观锁。悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
乐观锁如果有人在你之前更新了,你的更新应当是被拒绝的,可以让用户从新操作。悲观锁则会等待前一个更新完成。这也是区别。
公平锁和非公平锁
公平锁
顾名思义,是公平的,先来先得,FIFO;必须遵守排队规则。不能僭越。多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。

在ReentrantLock中默认使用的非公平锁,但是可以在构建ReentrantLock实例时候指定为公平锁。
ReentrantLock fairSyncLock = new ReentrantLock(true);假设线程 A 已经持有了锁,这时候线程 B 请求该锁将会被挂起,当线程 A 释放锁后,假如当前有线程 C 也需要获取该锁,那么在公平锁模式下,获取锁和释放锁的步骤为:
- 线程A获取锁--->线程A释放锁
- 线程B获取锁--->线程B释放锁;
- 线程C获取锁--->线程释放锁;
「优点」
所有的线程都能得到资源,不会饿死在队列中。
「缺点」
吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,CPU唤醒阻塞线程的开销会很大。
非公平锁
顾名思义,老子才不管你们谁先排队的,也就是平时大家在生活中很讨厌的。生活中排队的很多,上车排队、坐电梯排队、超市结账付款排队等等。但是不是每个人都会遵守规则站着排队,这就对站着排队的人来说就不公平了。等抢不到后再去乖乖排队。
多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。

上面说过在ReentrantLock中默认使用的非公平锁,两种方式:
ReentrantLock fairSyncLock = new ReentrantLock(false);或者:
ReentrantLock fairSyncLock = new ReentrantLock();都可以实现非公平锁。
「优点」
可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
「缺点」
大家可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
独享锁和共享锁
独享锁
独享锁也叫排他锁/互斥锁,是指该锁一次只能被一个线程锁持有。如果线程T对数据A加上排他锁后,则其他线程不能再对A加任何类型的锁。获得排他锁的线程既能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排他锁。获得共享锁的线程只能读数据,不能修改数据。
对于ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
- 读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
- 独享锁与共享锁也是通过
AQS来实现的,通过实现不同的方法,来实现独享或者共享。
可重入锁
若当前线程执行中已经获取了锁,如果再次获取该锁时,就会获取不到被阻塞。
public class RentrantLockDemo { public synchronized void test(){
System.out.println("test");
}
public synchronized void test1(){
System.out.println("test1");
test();
}
public static void main(String[] args) {
RentrantLockDemo rentrantLockDemo = new RentrantLockDemo();
//线程1
new Thread(() -> rentrantLockDemo.test1()).start();
}
}
当一个线程执行test1()方法的时候,需要获取rentrantLockDemo的对象锁,在test1方法汇总又会调用test方法,但是test()的调用是需要获取对象锁的。
可重入锁也叫「递归锁」,指的是同一线程外层函数获得锁之后,内层递归函数仍然有获取该锁的代码,但不受影响。
ThreadLocal设计原理
ThreadLocal名字中有个Thread表示线程,Local表示本地,我们就理解为线程本地变量了。
先看看ThreadLocal的整体:
最关心的三个公有方法:set、get、remove。
构造方法
public ThreadLocal() { }
构造方法里没有任何逻辑处理,就是简单的创建一个实例。
set方法
源码为:
public void set(T value) { //获取当前线程
Thread t = Thread.currentThread();
//这是什么鬼?
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
先看看ThreadLocalMap是个什么东东:

ThreadLocalMap是ThreadLocal的静态内部类。
set方法整体为:

ThreadLocalMap构造方法:
//这个属性是ThreadLocal的,就是获取hashcode(这列很有学问,但是我们的目的不是他)private final int threadLocalHashCode = nextHashCode();
private Entry[] table;
private static final int INITIAL_CAPACITY = 16;
//Entry是一个弱引用
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//数组默认大小为16
table = new Entry[INITIAL_CAPACITY];
//len 为2的n次方,以ThreadLocal的计算的哈希值按照Entry[]取模(为了更好的散列)
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
//设置阈值(扩容阈值)
setThreshold(INITIAL_CAPACITY);
}
然后我们看看map.set()方法中是如何处理的:
private void set(ThreadLocal<?> key, Object value) { Entry[] tab = table;
int len = tab.length;
//len 为2的n次方,以ThreadLocal的计算的哈希值按照Entry[]取模
int i = key.threadLocalHashCode & (len-1);
//找到ThreadLocal对应的存储的下标,如果当前槽内Entry不为空,
//即当前线程已经有ThreadLocal已经使用过Entry[i]
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 当前占据该槽的就是当前的ThreadLocal ,更新value结束
if (k == key) {
e.value = value;
return;
}
//当前卡槽的弱引用可能会回收了,key:null value:xxxObject ,
//需清理Entry原来的value ,便于垃圾回收value,且将新的value 放在该槽里,结束
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
//在这之前没有ThreadLocal使用Entry[i],并进行值存储
tab[i] = new Entry(key, value);
//累计Entry所占的个数
int sz = ++size;
// 清理key 为null 的Entry ,可能需要扩容,扩容长度为原来的2倍,并需要进行重新hash
if (!cleanSomeSlots(i, sz) && sz >= threshold){
rehash();
}
}
从上面这个set方法,我们就大致可以把这三个进行一个关联了:
Thread、ThreadLocal、ThreadLocalMap。

get方法


remove方法

expungeStaleEntry方法代码里有点大,所以这里就贴了出来。
//删除陈旧entry的核心方法private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
tab[staleSlot].value = null;//删除value
tab[staleSlot] = null;//删除entry
size--;//map的size自减
// 遍历指定删除节点,所有后续节点
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {//key为null,执行删除操作
e.value = null;
tab[i] = null;
size--;
} else {//key不为null,重新计算下标
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {//如果不在同一个位置
tab[i] = null;//把老位置的entry置null(删除)
// 从h开始往后遍历,一直到找到空为止,插入
while (tab[h] != null){
h = nextIndex(h, len);
}
tab[h] = e;
}
}
}
return i;
}
推荐阅读
JVM真香系列:轻松掌握JVM运行时数据区
《Maven实战》.pdf
以上是 【Java】图解多线程 的全部内容, 来源链接: utcz.com/a/89730.html