
【JS】txt 文件转码
写在前面
前段时间遇到了一个比较有意思的bug,txt文件资源用浏览器打开预览的时候乱码。然后就想给大家分享一下,最后的处理方案。
问题&&分析
问题:需要把txt文件统一转成utf-8的编码格式
分析:txt常用的编码格式包括 ANSI、UTF-8、GB2312 ,再简体中文的系统下,ASNI 和 GB2312 是一样的,所以我们要处理的只有GB2312 和 UTF-8
⚠️:windows office 2003 的 txt 文件默认编码格式是 GB2312方案一
第一个方案就比较有意思了,用的是 FileReader.readAsText,这个属性可以指定文件编码格式,取出文件的纯文本。但是如果指定的编码格式和源文件编码格式不一样,提取出来的文本就会乱码。所以这里的思路是:
1⃣️ 先用“utf-8”拿一次文本
2⃣️ 检测 string 有没有中文,如果没有中文的话一律当成乱码处理(gb2312和utf-8的英文编码一样)
3⃣️ 如果前面检测出来乱码了,就用“gb2312”重新拿一次文本,这一次就不用检测了,拿出来的就是正常文本了
4⃣️ 用没有乱码的文本生成一个新的文件
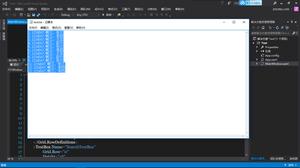
function txt2utf8(file, callback){let newBlob = null
const reader = new FileReader()
// readAsText 可以 指定编码格式 将文件提取成 纯文本
reader.readAsText(file,'utf-8')
reader.onload = e => {
const txtString = e.target.result
// utf-8 的 中文编码 正则表达式
const patrn=/[\uFE30-\uFFA0]/gi;
// 检测当前文本是否含有中文(如果没有,则当乱码处理)
// 两个格式的英文编码一样,所以纯英文文件也当成乱码再处理一次
if (!patrn.exec(txtString)) {
let reader_gb2312 = new FileReader()
// 再拿一次纯文本,这一次拿到的文本一定不会乱码
reader_gb2312.readAsText(file,'gb2312')
reader_gb2312.onload = e2 => {
newBlob = new Blob([e2.target.result])
callback&&callback(newBlob)
}
} else {
// 这里其实可以直接输出源文件,我是为了统一,都转成blob了
newBlob = new Blob([txtString])
callback&&callback(newBlob)
}
}
}
⚠️:不要调整 “utf-8” 和 “gb2312” 的顺序。因为readAsText内部的实现问题,用gb2312去拿utf-8的txt再做中文检测不准确。实现流程图:

方案二
这个方案比较粗暴,引了两个nodejs,前端也能跑。关于这个方案我只是做了个简单的尝试,不过扩展性上一个方案好不少,有兴趣的小伙伴可以试一试。
import iconv from 'iconv-lite'import jschardet from 'jschardet'
function txt2utf8(file, callback){
const reader = new FileReader()
reader.readAsBinaryString(file)
reader.onload = e => {
const txtBinary = e.target.result
// 用 jschardet 拿文件流编码 ,可能会存在偏差
const binaMg = jschardet.detect(txtBinary)
const buf = new Buffer(txtBinary, 'binary')
// 用 iconv 转码
const str = iconv.decode(buf, binaMg.encoding)
const newBlob = new Blob([str])
callback&&callback(newBlob)
}
}
⚠️:方案二只在本地调试过,本地跑起来没什么问题。具体的可用性和兼容性不确定。以上是 【JS】txt 文件转码 的全部内容, 来源链接: utcz.com/a/87458.html


![[1217]滑稽可笑的程序代码2.txt](/wp-content/uploads/thumbs/688996_thumbnail.jpg)
