xpath解析页面获取td内容中文乱码问题
抓取网站数据使用xpath处理,但是出现了乱码的情况,在使用etree函数前打印处理啊是不乱码的
但是,使用etree解析之后获取数据就出现了乱码的情况,这是什么情况?
我也查了些资料,但是试了下都无济于事。
https://segmentfault.com/a/11...
代码:
# coding:utf-8import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
}
index_url = 'http://113.140.66.226:8024/sxAQIWeb/PageCity.aspx?cityCode=NjEwMTAw'
index_res = requests.get(index_url, headers=headers)
html = etree.HTML(index_res.content)
form_data = {
'ctl00$ContentPlaceHolder1$ScriptManager1': 'ctl00$ContentPlaceHolder1$UpdatePanel1|ctl00$ContentPlaceHolder1$btnSearch',
'__EVENTTARGET': '',
'__EVENTARGUMENT': '',
'ctl00$ContentPlaceHolder1$city': 'PageCity.aspx?cityCode=NjEwMTAw',
'ctl00$ContentPlaceHolder1$d12': '2019-07-01',
'__VIEWSTATE': html.xpath("/html//input[@id='__VIEWSTATE']")[0].xpath('@value')[0],
'__VIEWSTATEGENERATOR': html.xpath("/html//input[@id='__VIEWSTATEGENERATOR']")[0].xpath('@value')[0],
'__EVENTVALIDATION': html.xpath("/html//input[@id='__EVENTVALIDATION']")[0].xpath('@value')[0],
'__ASYNCPOST': 'true',
'ctl00$ContentPlaceHolder1$btnSearch': '查 询',
}
result_res = requests.post(data=form_data, url=index_url, headers=headers)
result_html = etree.HTML(result_res.content)
tr_html_list = result_html.xpath('//table/tr')
for index, tr_html in enumerate(tr_html_list, 0):
if index == 0:
continue
print tr_html.xpath('td')[0].text.strip() # 日期
print tr_html.xpath('td')[1].text.strip() # 城市
print tr_html.xpath('td')[2].text.strip() # AQI
print tr_html.xpath('td')[3].text.strip() # 空气质量级别
print tr_html.xpath('td')[4].text.strip() # 级别
print tr_html.xpath('td')[5].text.strip() # 首要污染物
print tr_html.xpath('td')[6].text.strip() # 排名
break
结果:

回答:
把result_res.content改成result_res.text就可以了
纠正一下上面这个答案,我今天看了下官方文档,官方文档建议不要直接解析 Unicode 字符串,result_res.text 的返回值是 Unicode 字符串(我使用的Python3,也就是str类型)。
需要纠正的部分服下
result_res = requests.post(data=form_data, url=index_url, headers=headers)result_html = etree.HTML(
result_res.content, parser=etree.HTMLParser(encoding='utf8'))
# 继续使用result_res.content,因为这样效率才高,
# 官方推荐手动设置一个带编码方案的解析器,
# 详见: https://lxml.de/FAQ.html#why-can-t-lxml-parse-my-xml-from-unicode-strings
# 出现此错误的原因是原HTML文本头中没有使用mate标记编码方案,导致解析器无法识别编码方案
# <head><meta http-equiv="X-UA-Compatible" content="IE=edge" /><title>
目前觉得这是最好的方法
回答:
index_res = requests.get(index_url, headers=headers)index_res.encoding = 'utf-8'
以上是 xpath解析页面获取td内容中文乱码问题 的全部内容, 来源链接: utcz.com/a/164835.html
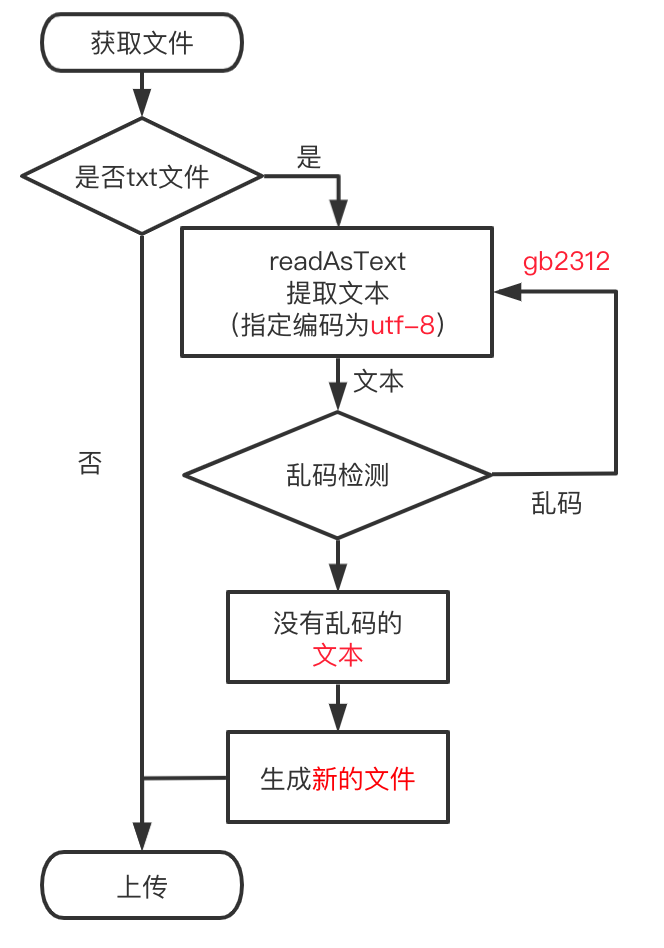
![[1217]滑稽可笑的程序代码2.txt](/wp-content/uploads/thumbs/688996_thumbnail.jpg)