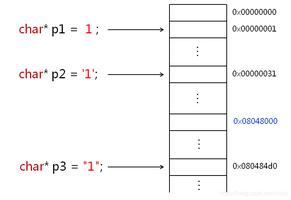
我用python爬下来网址怎么带个括号和单引号啊

我看别人最后都是一串一串网址没有【】和''的
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.error
import sqlite3
def main():
baseurl = "http://www.prnasia.com/m/mediafeed/rss?id=2303&t=240"
datalist = getData(baseurl)
savepath = ".\wenjian"
saveData(savepath)
findLink = re.compile('<a href="https://q.cnblogs.com/q/130354/(.*?)" target="_blank">')
def getData(baseurl):
datalist = []
# html= askUrl("http://www.prnasia.com/m/mediafeed/rss?id=2303&t=240")
# for i in range(0,1):
url = baseurl
html = askUrl(url)
soup = BeautifulSoup(html, "html.parser")
for presscolumn in soup.find_all('div', class_="presscolumn"):
data = []
item = str(presscolumn)
link = re.findall(findLink, item)
print(link)
data.append(link)
return datalistdef askUrl(url):
head = {
"User-Agent": "Mozilla/5.0(Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def saveData(savepath):
print("save....")
if name == "main":
main()
回答
python">import requestsfrom lxml import etree
url = 'http://www.prnasia.com/m/mediafeed/rss?id=2303&t=240'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
res = requests.get(url, headers=headers)
res_dome = etree.HTML(res.text)
print(res_dome.xpath('//h3/a/@href'))
以上是 我用python爬下来网址怎么带个括号和单引号啊 的全部内容, 来源链接: utcz.com/a/68856.html