淘宝直播“一猜到底”——移动端实时语音识别技术方案及应用
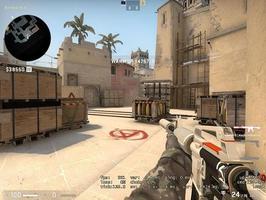
双11淘宝直播App·一猜到底
过去一年淘宝直播快速发展,截止2020年9月底,80个淘宝直播产业基地在全国落地开花,从农村走出10万农民主播,直播真正意义上成为帮助商家和消费者完成交易的利器,同时通过各种互动玩法让直播购物变得有趣好玩。在2020年双11开始阶段,淘宝直播App升级了18年直播答题「点题成金」的玩法,推出「一猜到底」新玩法。如果说传统的直播答题是「选择题」,一猜到底的玩法更像是几万人同时在线的「抢答题」,将答题方式从文字选择升级成语音抢答,给出猜中价格高低提示,让用户增加了更多的参与的乐趣。
为了实现比肩综艺现场的直播竞猜体验,我们一次压上了由达摩院语音实验室、阿里云PAI团队、淘系技术直播App和端智能MNN团队组成的全明星阵容,通力协作之下,一举实现了工业界首个用于直播的移动端语音识别。
(更多内容干货可关注【淘系技术】公众号)
业务流程和技术挑战

「一猜到底」整体玩法链路如上图所示,主播口播开始后,用户需要在人数和时间未满前,按住按钮,通过语音报出价格,系统通过本地语音识别能力进行识别和结果比对,提示用户所报价格“过高”还是“过低”,直到答对或者超时结束。在每一关有限的作答时间内,用户往往需要多次竞答,才能逼近商品的真实价格。于是,实时语音识别能不能准确且快速地识别用户的报价,直接决定了「一猜到底」的成败。
不同于一般的语音识别应用,一场顶流的淘宝直播,可以聚集百万乃至千万的用户围观。这么多用户同时进行语音识别,会出现非常多的请求,如果采用云端识别对服务压力和服务质量都有非常大的挑战。项目开始时实验了端侧和云侧识别的两种方案,发现云侧方案难以支撑这样的活动,最终选择了端侧方案,确定端侧识别方案之后,发现也不是康庄大道,主要存在以下技术难点:
- 高精度高性能的本地语音识别
目前行业比较成熟的是服务端的语音识别方案,完全照搬服务端方案到移动端也不现实,需要创建一套适合移动端运行的语音识别方案。同时,直播场景下的语音答题噪声较大,对语音识别的准确度要求较高,语音识别速度也会对用户的答题速度造成巨大影响。
- 语音模型和资源包体积过大
考虑到活动特性,端侧的语音识别引擎需要内置在包内,而且越小越好。经过客户端研发评估,如何做到15MB以内甚至更小的语音模型是关键,因此需要极致的模型压缩能力支持。
- 端侧资源有限,性能压力大
直播场景本身就已经很占用资源,叠加直播场景下做语音识别,对语音识别过程中的CPU、内存占用,都有很大的要求,高性能的推理和优化成为模型落地的最大拦路虎。
移动端实时语音识别技术大揭秘

阿里达摩院语音实验室早在2015年就研发出了第一代移动端离线语音识别方案,近来结合PAI模型压缩、MNN高性能推理引擎,实现了移动端离线和流式端到端语音识别方案,满足语音指令、语音识别、实时翻译等场景需求。根据「一猜到底」项目需求,我们选取"基于SAN-M的离线端到端语音识别"方案,通过极致的模型压缩和性能优化,最终实现模型大小小于15MB、内存占用低于60MB、1s语料识别快于50ms的高性能方案。
基于SAN-M的离线端到端语音识别
目前,最具代表性的离线端到端语音识别模型LAS[1]和Transformer[2]都是基于Attention-Encoder-Decoder的。LAS采用基于BLSTM的Encoder和基于单向LSTM的Decoder;而Transformer则采用Multi-head Self-Attention模块组建Encoder网络,采用Masked Multi-head Self-Attention组建Decoder网络。
在公开评测任务集上,Transformer较LAS在性能上有优势,同时由于采用了Multi-head,训练并行化效率更高。我们分析了Self-Attention和DFSMN memory block[3,4]之间的关联性:Self-Attention可以理解为采用了context-dependent系数进行全局建模,而DFSMN的memory block则采用了context-independent系数进行局部建模。对于语音识别,局部声学建模和全局语义建模都非常重要,因此我们提出了如下图所示的SAN-M模型结构,高效地融合了Self-Attention和DFSMN memory block。

SAN-M模块如上左图所示,将Self-Attention和DFSMN memory block融合一个模块,有效的结合了Self-Attention的全局长时建模能力和memory block的局部长时建模能力。基于SAN-M模块构建了如上右图的Encoder-Decoder离线语音识别系统(SAN-M-E2E-ASR),并在开源的1000小时AISHELL-2中文识别任务中获得了当前该任务的最优性能(CER=5.61%);在工业量级的2万小时中文识别任务中,该系统也显著优于我们之前线上的CTC系统和标准Transformer系统。
针对本次识别场景,我们最终实现了不到40MB的端到端模型,而识别性能则可以媲美上一代整体超过100GB大小的云端DFSMN-CTC系统。我们在finetune数据上进行了不同维度的挑选和搭配,并做了不同策略的数据扩增来覆盖多样的识别情况。针对模型输出的token,也进行了一定压缩,并拉低了与本次任务无关的token概率来降低误识别率。在ITN模块,我们采用精小的FST(Finite State Transducer)来实现规则网络,用状态转移来实现文字到阿拉伯数字的转换,通过边上权重来控制其转换方向,并在简略读法、谐音、容错上也做了一系列路径优化。
基于PAI-MNN云端一体化模型压缩
虽然达摩院语音实验室通过定制化语音识别模型设计,将原有的170MB模型裁剪至不到40MB,但是考虑到移动端的资源情况,我们还需要通过PAI-MNN云端一体化模型压缩方案,进一步将模型基本无损地压缩到15MB以内。

从训练、模型压缩到优化部署的PAI-MNN云端一体方案
PAI混合精度量化流程

PAI混合精度量化流程
上图显示了PAI团队 (PAI: Platform of A. I. in Alibaba)研发的无数据标注干预的自动混合精度量化流程(Label-free AMP Pipeline, AMP: Automatic Mixed Precision),包括量化误差预补偿、离线标定、量化噪声分析与混合精度决策四个阶段,主要创新点包括:
- 支持端到端Transformer的离线后量化:
- PAI团队的后量化方法,引入了循环张量探针,以支持端到端Transformer的离线后量化。
- 相比于拆图量化、量化训练等,端到端后量化具备快捷、高效的优势;
集成了丰富的后量化策略,为后量化的精度鲁棒性提供了坚实保证,基本策略包括:
KL算法的改进,能够有效减少输入/输出张量的量化噪声;
EasyQuant(参考文献 [5])的使用,可进一步减少输入/输出张量的量化误差,尤其能改善INT7等更低精度量化的效果;
Bias Correction(参考文献 [6])通过补偿网络权重的量化偏差(均值与方差的偏差),以减少权重量化噪声;同时对Bias Correction的适当改进,增强了对SAN-M ASR模型的补偿效果;
ADMM(参考文献 [7])亦可优化权重量化参数,减少权重量化噪声;也适当改进了ADMM的使用,从而在交替方向迭代范围内,确保权重量化误差最小;
Weight Adjustment(参考文献 [8])在Kernel weight按Per-tensor量化时,通过Per-channel形式的等价均衡变换,可以减少Weight量化误差。
- 无Label干预的混合精度量化流程:
- 该流程从模型输入到混合精度决策,无需数据标注(Label)的干预,简洁易用、快捷有效;
- 量化误差按逐层统计,且能准确反映每个网络层的量化敏感度,为混合精度(INT8/FP32混合)决策提供了可靠基础;
- 通过控制回退的网络层数,可选择出精度与模型容量折中最佳的帕累托最优解,完成多目标优化;
- 生成的混合精度量化表,能够对接移动端推理框架MNN,以生成低延迟、高推理精度的运行时推理引擎;从而构成了完整的工具链路,即从混合精度量化、到移动端的推理部署;
- AMP Pipeline不仅适用于移动端,也适用于CPU/GPU优化部署,体现了PAI云端一体的优势所在。
基于PAI AMP Pipeline,有效实现了SAN-M模型的离线后量化(PTQ: Post-training Quantization)。为了保持算法模型识别精度,经AMP INT8量化之后(回退3个Op,分类层保留为FP32实现)。
为了解决压缩率的问题,MNN模型转换和优化工具对回退的算子统一使用权重8bit存储、float计算的方式进行优化,进一步压缩模型大小。通过一套统一格式的模型压缩文件,经过PAI AMC优化的模型可以顺滑无缝地转换到MNN的格式。
MNN模型转换工具基于现有的图优化流程,根据该模型压缩文件将float模型转换成MNN模型的同时完成离线量化,具体过程如下:
- 根据量化表中提供的tensor name,在TensorFlow的计算图中生产和消费该tensor的边上同时插入一个自定义的量化和反量化算子。
- 将TensorFlow的计算图转换成MNN的计算图,其中自定义的量化和反量化算子转换成MNN量化(FloatToInt8)和反量化(Int8ToFloat)算子。
- 算子融合:将支持量化的算子、输入的反量化算子和输出的量化算子融合成一个Int8的算子。
- 最后消除成对的MNN量化和反量化算子。

最终,SAN-M模型在众包测试集上的WER绝对损失低于0.1%、SER绝对损失低于0.5%、理论压缩比约为3.19倍。
基于MNN推理引擎的实时高性能计算

为了在移动端上实现实时的端到端语音识别模型推理计算,MNN在全链路上做了诸多优化。
端到端语音识别模型基于Transformer结构,包含一个对输入音频特征编码的Encoder和一个自回归解码的Decoder。这类模型结构要求MNN支持Control Flow、Dynamic Shape和Zero Shape等特性,因此,MNN首先在框架层面对这些特性进行了支持和完善:
- MNN重构了Control Flow支持方案,提供用户透明的functional control flow实现,并支持了TensorFlow 1.x的控制流模型转换,为用户提供一站式的部署体验。
- 对于Dynamic Shape的支持,MNN将整图按照动态形状算子划分为多个分段子图。在代码层面,一个子图对应一个Module,Module支持嵌套,即整图被表达为一个由Module组成的调用树,树的每个叶子节点可以使用一个Session来执行,Session每次执行前resize,重新进行shape推理和分配内存。
Zero Shape指的是模型中某些Tensor的shape存在0值,比如 (1, 0, 256),这种情况大多是为了给while-loop中某些循环变量提供初始值而引入的。MNN在形状推理和执行逻辑上对Zero Shape进行了支持。
之后,MNN根据达摩院模型新增了LayerNorm Fuse、Constant Folding、重复Reshape算子消除等图优化方法。图优化之后的计算图更容易和其他优化方法组合使用,比如,Constant Folding后MatMul的一个输入可能被替换成一个Constant节点,因此就可以转换成FullyConnected或Conv1x1进行加速,并且也更容易利用模型压缩方法对权重进行量化。
而后,语音模型的耗时重点仍然是矩阵乘法。MNN通过更优矩阵乘分块、基于 NC4HW4 布局优化前后内存布局转化、Strassen 算法改进等策略,优化了整体的卷积和矩阵乘的性能,ARM 架构上性能提高了 10%-20% ,保障了语音模型的高效运行。
同时,MNN最新提出的几何计算机制也在实时语音识别起到了重要作用。几何计算是MNN为了解决设备碎片化问题而提出的一种新机制,其核心在于把坐标映射标准化,以便统一实现与优化。在几何计算的支持下,我们可以较简单地合并相邻的纯形变算子,从而降低访存需求,提升模型运行性能。
最后,在PAI-MNN云端一体化模型压缩的加持下,我们利用量化表和有限回退机制,在精度损失可控的前提下,进一步降低了移动端上的计算总量。

在这一系列组合拳之下,我们才最终在目标设备上,将RTF降低到了目标值0.02以下,从而实现实时语音识别,让「一猜到底」得以走到每一个用户的面前。
总结与展望
通过这次项目合作,基于高性能推理引擎MNN,结合一流的语音模型设计和模型压缩技术,我们已经能在移动端上实现实时的语音识别,并通过了双11核心场景的考验。
但我们并未止步于此。
达摩院语音实验室在千人千面的个性化语音识别上的研究工作业已展开,在保护用户隐私的前提下实现如联系人、住址、搜索历史等词汇的识别。PAI团队会继续携手MNN团队,进一步探索围绕端侧设备的精简模型设计和自适应模型架构优化方案。而MNN团队,则会持续建设流式识别、混合计算、编译优化等机制,为ASR、NLP等AI应用在端侧的发力提供最高效、最稳定的坚实后盾。
相信在不远的未来,我们就能为用户带来更加有用、有趣的AI交互体验。
参考
===
[1] Chan W, Jaitly N, Le Q, et al. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition[C]//2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016: 4960-4964.
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[3] Zhang S, Lei M, Yan Z, et al. Deep-fsmn for large vocabulary continuous speech recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 5869-5873.
[4] Zhang S, Lei M, Liu Y, et al. Investigation of modeling units for mandarin speech recognition using dfsmn-ctc-smbr[C]//ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 7085-7089.
[5] Di Wu, Qi Tang, Yongle Zhao, Ming Zhang, Ying Fu, Debing Zhang, "EasyQuant: Post-training Quantization via Scale Optimization", arXiv preprint 2006.16669, 2020.
[6] Ron Banner, Yury Nahshan, Elad Hoffer, Daniel Soudry, "Post-training 4-bit quantization of convolution networks for rapid-deployment", arXiv preprint 1810.05723, 2018.
[7] Cong Leng, Hao Li, Shenghuo Zhu, Rong Jin, "Extremely Low Bit Neural Network: Squeeze the Last Bit Out with ADMM", arXiv preprint 1707.09870, 2017.
[8] Markus Nagel, Mart van Baalen, Tijmen Blankevoort, Max Welling, "Data-Free Quantization Through Weight Equalization and Bias Correction", arXiv preprint 1906.04721, 2019.
以上是 淘宝直播“一猜到底”——移动端实时语音识别技术方案及应用 的全部内容, 来源链接: utcz.com/a/66775.html