CS20 Class_1 Operations
文章目录
- Operations
- Basic operations
- 使用特定的设备
- 创建不同的图
- 显示log的输出级别
- TensorBoard显示
- Base op
Operations
数据流图,TensorFlow将计算的定义与其执行分开,通过GraphsGraphs和SessionSession来完成。
先定义一个GraphsGraphs,然后使用SessionSession中的相关的操作
Basic operations
import tensorflow as tfa = tf.add(3,5)
print(a)
Tensor("Add:0", shape=(), dtype=int32)
a = tf.add(3,5)with tf.Session()as sess:
print(sess.run(a))
x =2y =3
add_op = tf.add(x, y)
mul_op = tf.multiply(x, y)
useless = tf.multiply(x, add_op)
pow_op = tf.pow(add_op, mul_op)
with tf.Session()as sess:
#z = sess.run(pow_op)
z, not_useless = sess.run([pow_op, useless])
tf.Session.run(fetches,
feed_dict=None,
options=None,
run_metadata=None)
使用特定的设备
with tf.device('/cpu:0'):a = tf.constant([1.0,2.0,3.0,4.0,5.0,6.0], shape=[2,3], name='a')
b = tf.constant([1.0,2.0,3.0,4.0,5.0,6.0], shape=[3,2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
SessionSession会有一些常见的配置,最常用的是log_device_placementlog\_device\_placement和allow_soft_placementallow\_soft\_placement
为了避免出现你指定的设备不存在这种情况, 你可以在创建的 SessionSession 里把参数 allow_soft_placementallow\_soft\_placement设置为 TrueTrue, 这样 TensorFlowTensorFlow 会自动选择一个存在并且支持的设备来运行operationoperation
log_device_placementlog\_device\_placement 将该属性设置为 TrueTrue 的时候,程序日志中将记录计算图中每个节点是在哪个设备中进行计算的。
config = tf.ConfigProto(log_device_placement=True,allow_soft_placement=True)
sess = tf.Session(config=config)
创建不同的图
g = tf.Graph()with g.as_default():
x = tf.add(3,5)
sess = tf.Session(graph=g)
with tf.Session()as sess:
sess.run(x)
如果是处理默认的图
g = tf.get_default_graph()显示log的输出级别
import osos.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#1 代表这是默认的显示等级,显示所有信息
#2 代表只显示 warning 和 Error
#3 代表只显示 Error
TensorBoard显示
如果可视化,需要把log日志输出
writer = tf.summary.FileWriter([logdir],[graph])import tensorflow as tfa = tf.constant(2,name ="a")
b = tf.constant(3, name ="b")
x = tf.add(a, b, name ="add")
writer = tf.summary.FileWriter('./graphs', tf.get_default_graph())
with tf.Session()as sess:
# writer = tf.summary.FileWriter('./graphs', sess.graph)
# if you prefer creating your writer using session's graph
print(sess.run(x))
writer.close()
python3 [my_program.py]tensorboard --logdir="./graphs/lazy_loading"--port 6006#6006 or any port you want
这时打开浏览器,推荐使用google浏览器,http://localhost:6006/
Base op
tf.constant(value, dtype=None, shape=None, name='Const', verify_shape=False)# constant of 1d tensor (vector)
a = tf.constant([2,2], name="vector")
# constant of 2x2 tensor (matrix)
b = tf.constant([[0,1],[2,3]], name="matrix")
tf.zeros(shape, dtype=tf.float32, name=None)
# create a tensor of shape and all elements are zeros
tf.zeros([2,3], tf.int32)==>[[0,0,0],[0,0,0]]
# input_tensor [[0, 1], [2, 3], [4, 5]]
tf.zeros_like(input_tensor)==>[[0,0],[0,0],[0,0]]
tf.ones(shape, dtype=tf.float32, name=None)
# create a tensor of shape and all elements are ones
tf.ones([2,3], tf.int32)==>[[1,1,1],[1,1,1]]
# input_tensor is [[0, 1], [2, 3], [4, 5]]
tf.ones_like(input_tensor)==>[[1,1],[1,1],[1,1]]
tf.fill(dims, value, name=None)
# create a tensor filled with a scalar value.
tf.fill([2,3],8)==>[[8,8,8],[8,8,8]]
tf.lin_space(start, stop, num, name=None)
# create a sequence of num evenly-spaced values are generated beginning at start.
# If num > 1, the values in the sequence increase by (stop - start) / (num - 1), so that the last one is exactly stop.
# comparable to but slightly different from numpy.linspace
tf.lin_space(10.0,13.0,4, name="linspace")==>[10.011.012.013.0]
tf.range([start], limit=None, delta=1, dtype=None, name='range')
# create a sequence of numbers that begins at start and extends by increments of delta up to but not including limit
# 'start' is 3, 'limit' is 18, 'delta' is 3
tf.range(start, limit, delta)==>[3,6,9,12,15]
# 'start' is 3, 'limit' is 1, 'delta' is -0.5
tf.range(start, limit, delta)==>[3,2.5,2,1.5]
# 'limit' is 5
tf.range(limit)==>[0,1,2,3,4]
Note that unlike NumPy or Python sequences, TensorFlow sequences are not iterable.
tf.ones([2,2], np.float32)# ⇒ [[1.0 1.0], [1.0 1.0]]For tf.Session.run(fetches):if the requested fetch is a Tensor , output will be a NumPy ndarray.
sess = tf.Session()
a = tf.zeros([2,3], np.int32)
print(type(a))# ⇒ <class 'tensorflow.python.framework.ops.Tensor'>
a = sess.run(a)<<<< Avoid doing this. Use a_out = sess.run(a)
print(type(a))# ⇒ <class 'numpy.ndarray'>
Only use constants for primitive types.Use variables or readers for more data that requires more memory
# create variables with tf.Variable
s = tf.Variable(2, name="scalar")
m = tf.Variable([[0,1],[2,3]], name="matrix")
W = tf.Variable(tf.zeros([784,10]))
tf.Variable holds several ops:
x = tf.Variable(...)
x.initializer # init op
x.value()# read op
x.eval()# 读取里面的值
x.assign(...)# write op
x.assign_add(...)# and more
变量的创建方式建议使用下面的方式
# create variables with tf.get_variables = tf.get_variable("scalar", initializer=tf.constant(2))
m = tf.get_variable("matrix", initializer=tf.constant([[0,1],[2,3]]))
W = tf.get_variable("big_matrix", shape=(784,10), initializer=tf.zeros_initializer())
tf.get_variable(
name,
shape=None,
dtype=None,
initializer=None,
regularizer=None,
trainable=True,
collections=None,
caching_device=None,
partitioner=None,
validate_shape=True,
use_resource=None,
custom_getter=None,
constraint=None
)
变量使用之前需要进行初始化
The easiest way is initializing all variables at once:with tf.Session()as sess:
sess.run(tf.global_variables_initializer())
Initialize only a subset of variables:
with tf.Session()as sess:
sess.run(tf.variables_initializer([a, b]))
Initialize a single variable
W = tf.Variable(tf.zeros([784,10]))
with tf.Session()as sess:
sess.run(W.initializer)
Initializer is an op. You need to execute it within the context of a session
# W is a random 700 x 100 variable objectW = tf.Variable(tf.truncated_normal([700,10]))
with tf.Session()as sess:
sess.run(W.initializer)
print(W.eval())# Similar to print(sess.run(W))
W = tf.Variable(10)
W.assign(100)
with tf.Session()as sess:
sess.run(W.initializer)
print(W.eval())# >> 10 why ?
#W.assign(100) creates an assign op. That op needs to be executed in a session to take effect.
W = tf.Variable(10)
assign_op = W.assign(100)
with tf.Session()as sess:
sess.run(W.initializer)
sess.run(assign_op)
print(W.eval())# >> 100
my_var = tf.Variable(10)
With tf.Session()as sess:
sess.run(my_var.initializer)
# increment by 10
sess.run(my_var.assign_add(10))# >> 20
# decrement by 2
sess.run(my_var.assign_sub(2))# >> 18
TensorflowTensorflow的SessionSession维持变量的分离
W = tf.Variable(10)sess1 = tf.Session()
sess2 = tf.Session()
sess1.run(W.initializer)
sess2.run(W.initializer)
print(sess1.run(W.assign_add(10)))# >> 20
print(sess2.run(W.assign_sub(2)))# >> 8
print(sess1.run(W.assign_add(100)))# >> 120
print(sess2.run(W.assign_sub(50)))# >> -42
sess1.close()
sess2.close()
ControlDependenciesControl Dependencies
tf.Graph.control_dependencies(control_inputs)# defines which ops should be run first
# your graph g have 5 ops: a, b, c, d, e
g = tf.get_default_graph()
with g.control_dependencies([a, b, c]):
# 'd' and 'e' will only run after 'a', 'b', and 'c' have executed.
d =...
e = …
占位符
# create a placeholder for a vector of 3 elements, type tf.float32a = tf.placeholder(tf.float32, shape=[3])
b = tf.constant([5,5,5], tf.float32)
# use the placeholder as you would a constant or a variable
c = a + b # short for tf.add(a, b)
with tf.Session()as sess:
print(sess.run(c, feed_dict={a:[1,2,3]}))# the tensor a is the key, not the string ‘a’
# >> [6, 7, 8]
tf.placeholder(dtype, shape=None, name=None)
shape=None means that tensor of any shape will be accepted as value for placeholder.
shape=Noneis easy to construct graphs, but nightmarish for debugging
You have to do it one at a time
with tf.Session()as sess:
for a_value in list_of_values_for_a:
print(sess.run(c,{a: a_value}))
The trap of lazy loading
x = tf.Variable(10, name='x')y = tf.Variable(20, name='y')
z = tf.add(x, y)
with tf.Session()as sess:
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('graphs/normal_loading', sess.graph)
for _ inrange(10):
sess.run(z)
writer.close()
x = tf.Variable(10, name='x')
y = tf.Variable(20, name='y')
with tf.Session()as sess:
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('graphs/lazy_loading', sess.graph)
for _ inrange(10):
sess.run(tf.add(x, y))
print(tf.get_default_graph().as_graph_def())
writer.close()
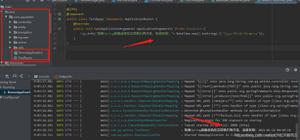
可以看到图片如下
上面的图片是normal_loading,下面的是lazy_loading。
normal_loading中定义了x和y变量,同时定义了x+yx+y的操作zz,无论在Seession中做多少次加法只会有一个节点,而在lazy_loading中多次执行x+yx+y的操作,会产生多个节点,每个节点都是x+yx+y,这个就是lazy_loading带来的问题,会严重影响图的读的速度
解决办法
1、把ops的计算和运行的定义分开
2、Use Python property to ensure function is also loaded once the first time it is called*
第二个解决办法具体可参考参考文献4
参考文献:
1、https://web.stanford.edu/class/cs20si/syllabus.html
2、http://wiki.jikexueyuan.com/project/tensorflow-zh/how_tos/using_gpu.html
3、https://www.jianshu.com/p/2da98dcbca77
4、https://danijar.com/structuring-your-tensorflow-models/
以上是 CS20 Class_1 Operations 的全部内容, 来源链接: utcz.com/a/58941.html