6.1 常用的损失函数(18种)
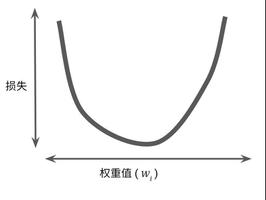
0 损失函数的概念损失函数是用来衡量模型输出与真实标签的差异。
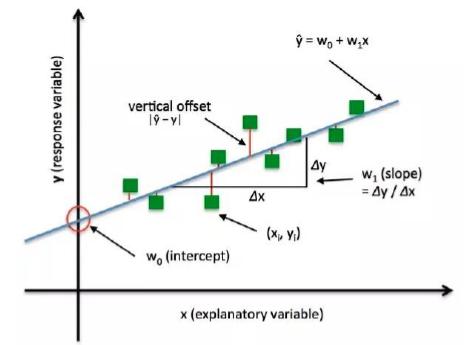
比如下面的一元线性回归的实验:
绿色的点是样本。蓝色的直线是训练好的一个模型。 我们可以看到这个模型并没有很好的拟合到每一个数据点。所以数据点会产生一个loss。红色的线段就是模型之间的差距。
损失函数、代价函数和目标函数有什么区别?
损失函数是计算一个样本的差异。 代价函数是计算整个样本集的loss的平均值。
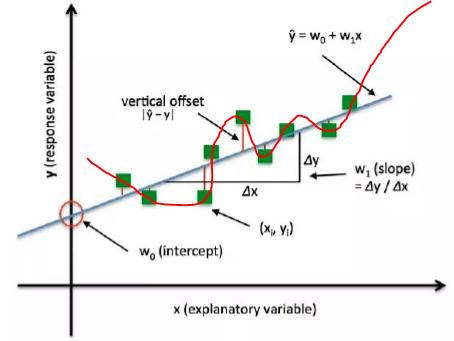
目标函数是更广泛的概念。目标通常包含cost 和正则化项。cost就是代价函数,是衡量模型输出与真实标签的差异。但是是不是代价函数越小越好呢?其实不一定,因为有时候会过拟合。 比如,训练了下面的模型:
可以看到这条曲线可以很好的拟合每一个数据点,所以它的cost是0。但是这个模型是不是好的模型呢?显然不是,这就是由于模型太复杂导致过拟合。所以在追求cost比较小的时候,同时也要对这个模型做一些限制,约束。在机器学习中,这些约束项就成为正则项。通常采用L1、L2、系数约束等。
在后面,不失一般性,后面都会用Loss function来统称。
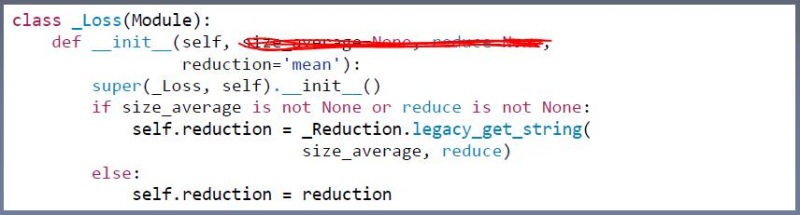
看一下pytorch中的loss。
pytorch中的loss还是继承于Module。所以说Loss还是相当于网络层。 共有三个参数,其中前两个即将(已经)被舍弃了,以后不要用了。因为它的功能在reduction中完全可以实现。
下面看一下RMB分类中使用过的交叉熵损失函数,它是怎么创建的,以及怎么使用的。
~~~
接来来介绍一下的损失函数。
1 nn.CrossEntropyLoss 交叉熵损失函数
它的功能是将nn.LogSoftmax()于nn.NLLLoss()结合,进行交叉熵计算。需要注意的是,他并不是公式意义上的交叉熵函数,而是有一些不同之处。不同之处在用使用softmax()对数据进行了一个归一化,把数据值归一化概率值。这是因为交叉熵损失函数常常用于分类任务当中,而分类任务通常是需要计算两个输出的概率值。
交叉熵,信息熵,相对熵之间的关系:
熵,准确来说叫做信息熵,它是由信息论之父香农,从热力学的概念借鉴而来的一个名词。是用来描述一个事件的不确定性。一个事件越不确定,他的熵越大。熵的计算公式如下:
熵是自信息的期望。那什么是自信息呢?自信息是用于衡量单个输出、单个事件的不确定性。公式如下:
p(x)是事件x的概率。例如明天下雨的概率是0.3,那明天下雨的自信息就是-log(0.3)。而熵是整个概率分布的不确定性。
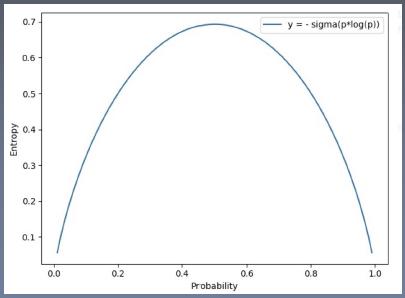
为了更好的理解熵的大小的关于事件不确定性的关系,我们来看示意图:
这是一个伯努利分布(两点分布)的一个信息熵。可以看到,当事件的概率是0.5的时候,它的信息熵最大。也就是概率是0.5的时候,不确定性最大。
下面来看相对熵,又叫KL散度。它是用来衡量两个分布之间的差异。但是注意,它并不是一个距离,因为它不具有对称性。
P是真实的分布,也就是训练集中样本的分布。而Q是模型输出的分布。
最后,我们来看交叉熵的公式:
三者关系:
因此:相对熵 = 交叉熵 - 信息熵。
刚才说了,P是真实的分布,也就是训练集中样本的分布。而Q是模型输出的分布。 所以在机器学习模型中,最小化交叉熵等价于优化相对熵。为什么呢?由于训练集是固定的,所以H(P)是一个常数。
下面开始学习这个函数。
在没有权值的时候,计算公式是:
x是输出的概率值,class是类别值。
weight:为各个类别的loss设置权值。 ignore index:指示某个类别不计算loss. reduction:计算模式。 size_average\reduce:不用了。
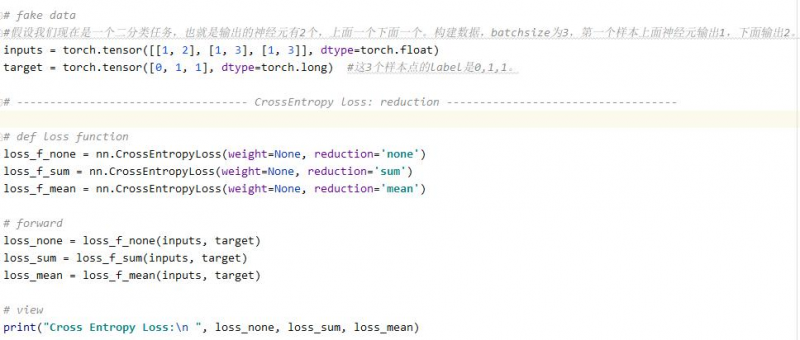
例1:
结果:
可以看到逐个计算交叉熵损失为:1.3133, 0.1269, 0.1269. 求和为:1.5671 平均为:0.5224
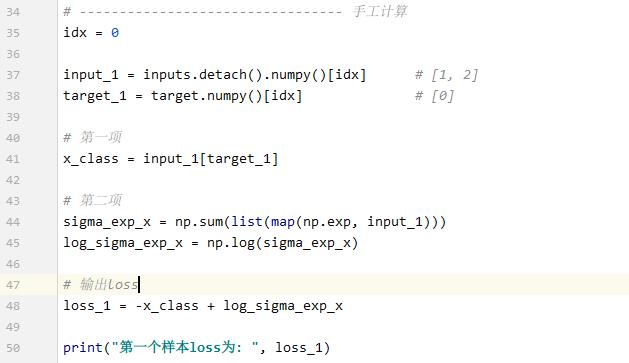
我们用手工算一下试试:
结果:
可以看到,结果一样。 可以验证我们的公式是正确的。
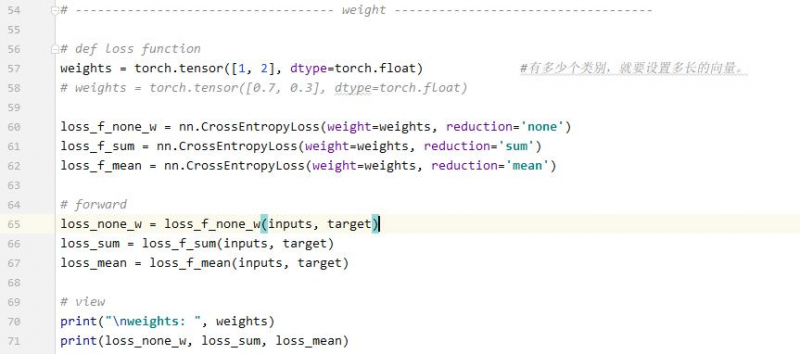
例2:weight参数
结果:
上面不加权值的结果为:
可以看到,第二类的权值为2。因此第二类的都乘以了2。0.3642是加权平均。
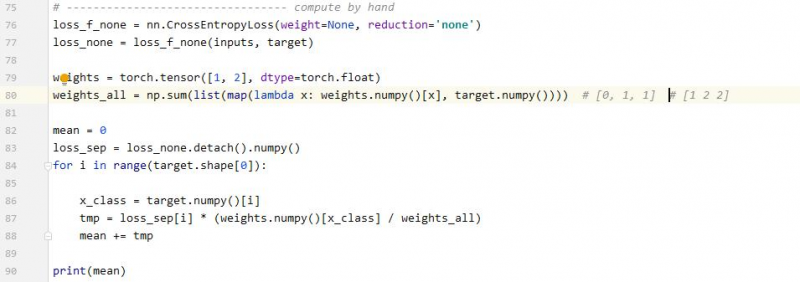
手工计算:
结果:
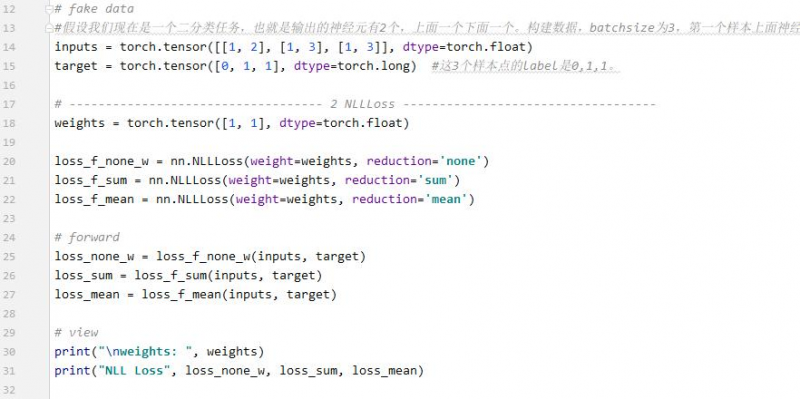
2 nn.NLLLoss
只是执行了符号的功能。不要被他的名字欺骗了。输出就是-x.
例:
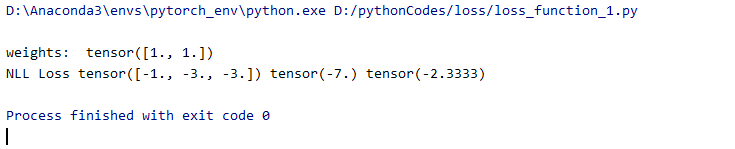
结果:
为什么会得到-1,-3,-3呢。第一个样本是第0类,所以只对第1个神经元进行计算,对1取符号,得到-1。 第二个样本是第1类,所以只对第2个神经元进行计算,对3取负号,得到-3。 第三个样本是第1类,所以只对第2个神经元进行计算,对3取负号,得到-3。
3 nn.BCELoss
是交叉熵损失函数的一个特例,是二分类的交叉熵损失函数。
4 nn.BCEWithLogitsLoss
5 nn.L1Loss
6 nn.MSELoss
7 nn.SmoothL1Loss
8 nn.PoissionNLLLoss
9 nn.KLDivLoss
10
|

 下面
下面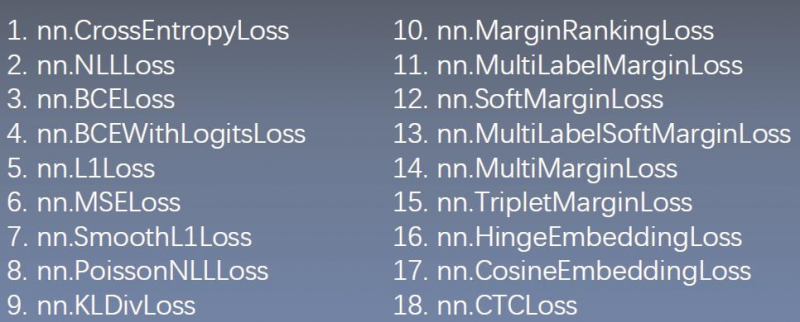
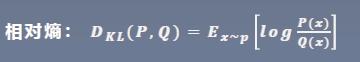
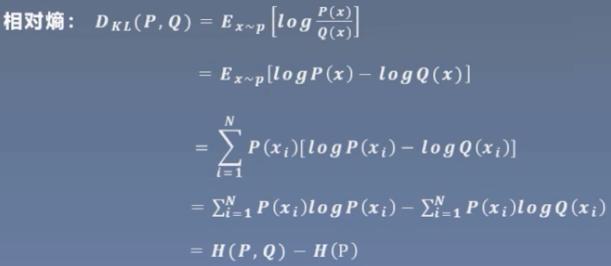
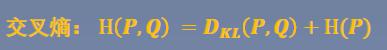

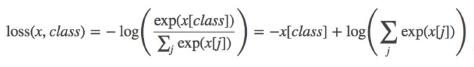






以上是 6.1 常用的损失函数(18种) 的全部内容, 来源链接: utcz.com/a/53086.html