超融合架构hdfscorosync+保时捷718maker之crmgn使用(二)
上一篇博客我们聊到了crmsh的安装以及配置一个资源到corosync+pacemaker高可用集群上的相关命令的用法,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13592484.html;今天我们继续来说crmsh的其他常用命令的用法;
node常用命令
show:查看指定节点的定义信息,如果未指定节点表示查看集群所有节点的定义信息;
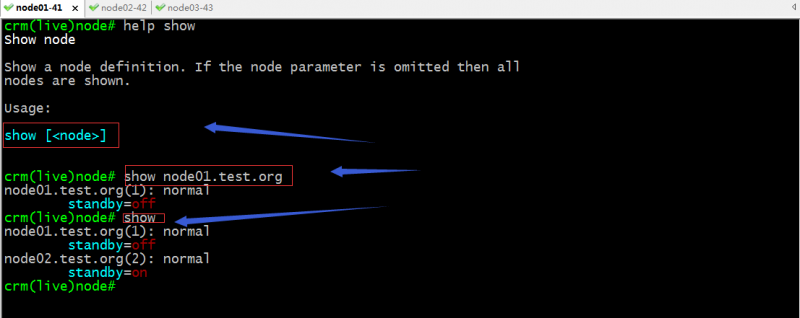
standby:设置指定节点为standby状态;默认不指定表示设置当前crmsh所在节点为standby状态;standby状态表示该节点为备用状态,不运行任何资源;
命令语法格式
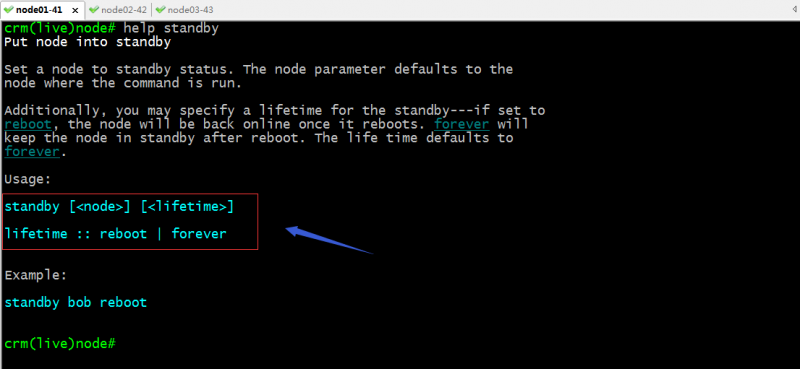
提示:lifetime指定standby状态的生命周期,reboot表示设置对应节点为standby状态,直到它重启后失效,意思是只要对应节点重启以后,standby状态就会转换为online状态;forever表示设置指定节点永久都是standby,只要不手动设置为online状态,它就会一直是standby状态,即便重启对应节点;默认不指定lifetime都表示永久将指定节点设置为备用状态;
示例:设置node01为standby状态
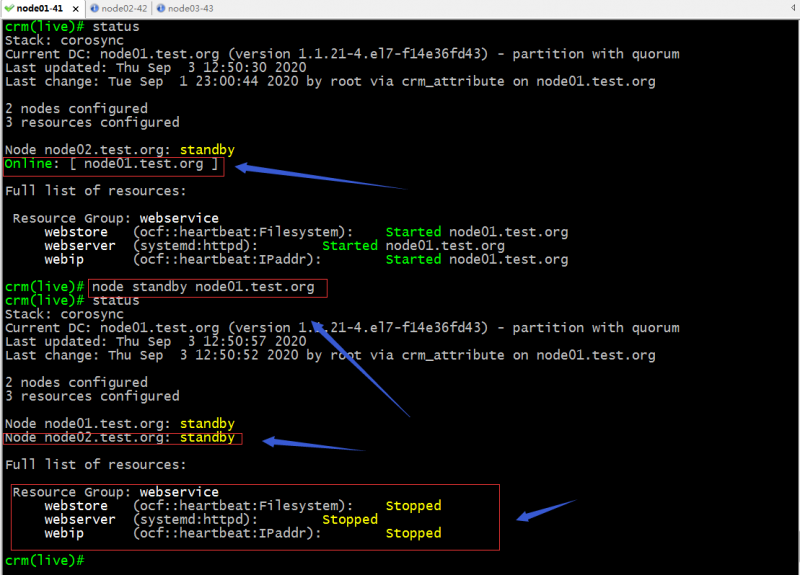
提示:正常情况只要把指定节点设置为standby状态,在其上运行的所有资源都将会迁移至别的节点,如果集群中的所有节点都为standby模式,对应资源将无法运行,所以我们可以看到我们在上托管的web服务处于停止状态;
ready:设置指定节点为非维护模式,也就是将指定节点设置为准备上线状态;
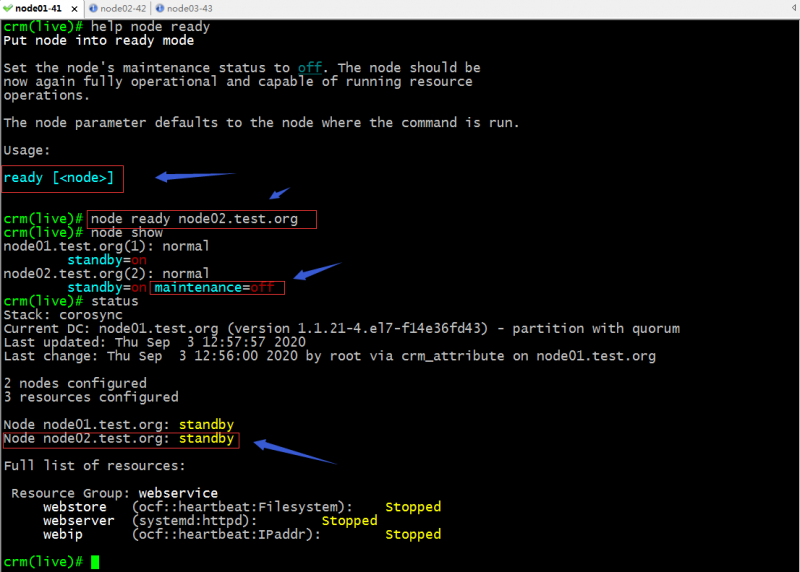
提示:把指定节点设置为ready状态,它默认会在node定义信息中添加一项maintenance=off的属性,意思指定该节点为非维护状态;但是如果对应节点为standby状态,即便我们设置了指定主机为ready状态,它也不会上线,我们可以理解为standby的状态优先级要高于ready状态;意思就是只要对应节点为standby状态,对其节点设置为ready不起作用;
online:设置指定节点为在线状态;
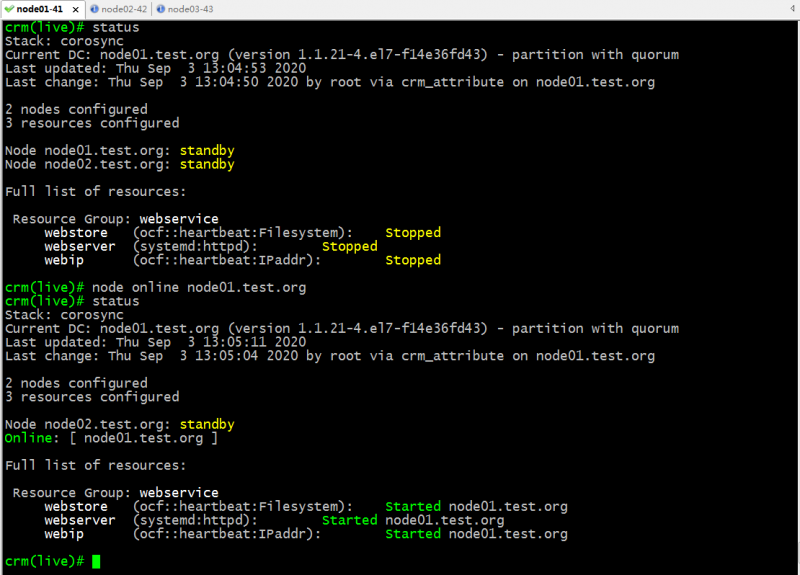
提示:设置指定为online状态以后,对应托管在集群上的资源会自动运行起来;
attribute:设置指定节点的指定定义属性;
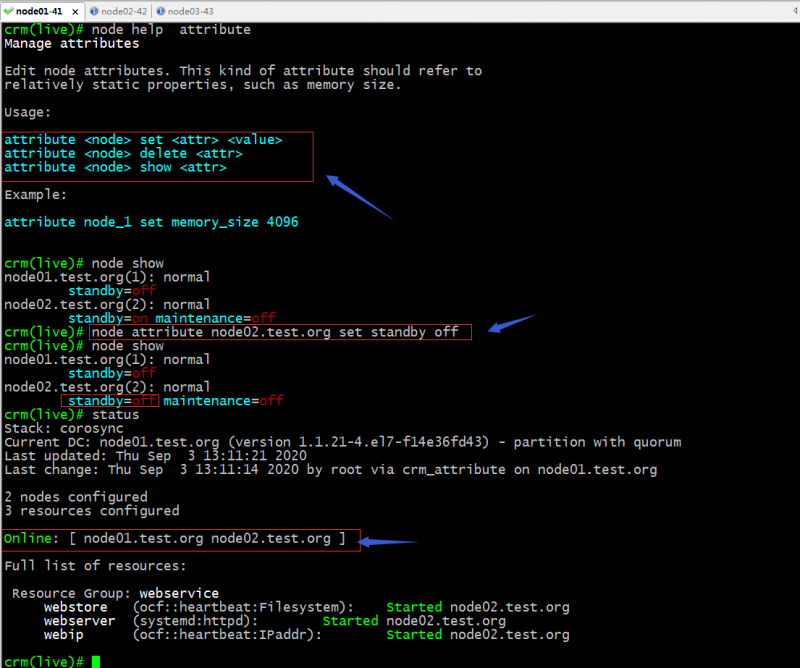
提示:可以看到把node02上的standby属性修改为off以后,对应节点就上线了;对应资源也从node01迁移到node02上了;正常没有设置任何资源对节点的倾向性的情况下,资源默认不会迁移,之所以迁移是我们在创建组的时候它在配置信息中生成了一条资源对节点的倾向性;如下所示
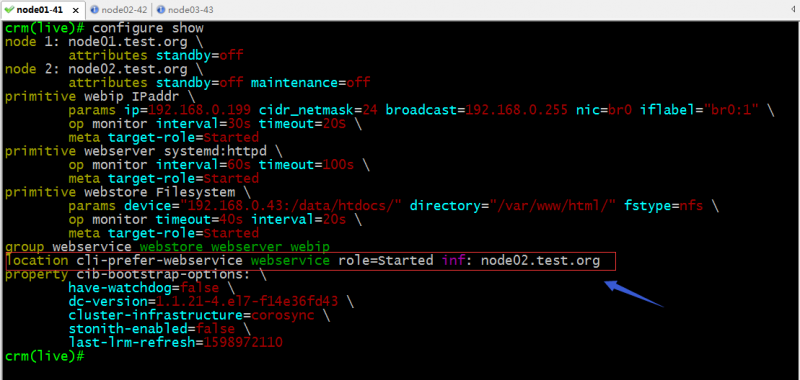
提示:红框中的配置表示webservice这个组资源无限倾向性node02,意思只要node02在线,webservice这个组资源就会运行到node02上;
server:查看当前集群节点的主机名列表;
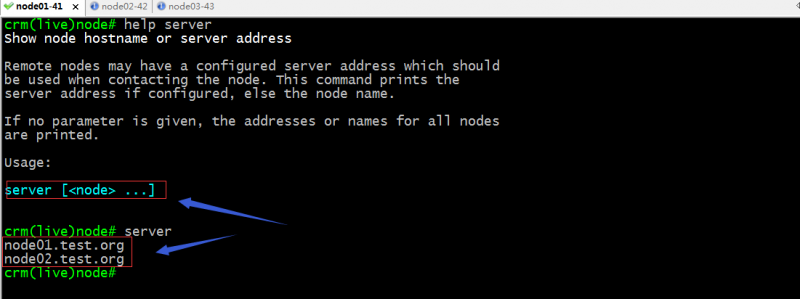
resource常用命令
ban:从指定节点把指定资源移除,类似手动将指定节点的指定资源迁出;
命令语法格式

提示:rsc是指定资源的名称;lifetime指定其ban的操作的生命周期,同standby命令的生命周期类似;force表示强制操作;
示例:将webip从node01迁出
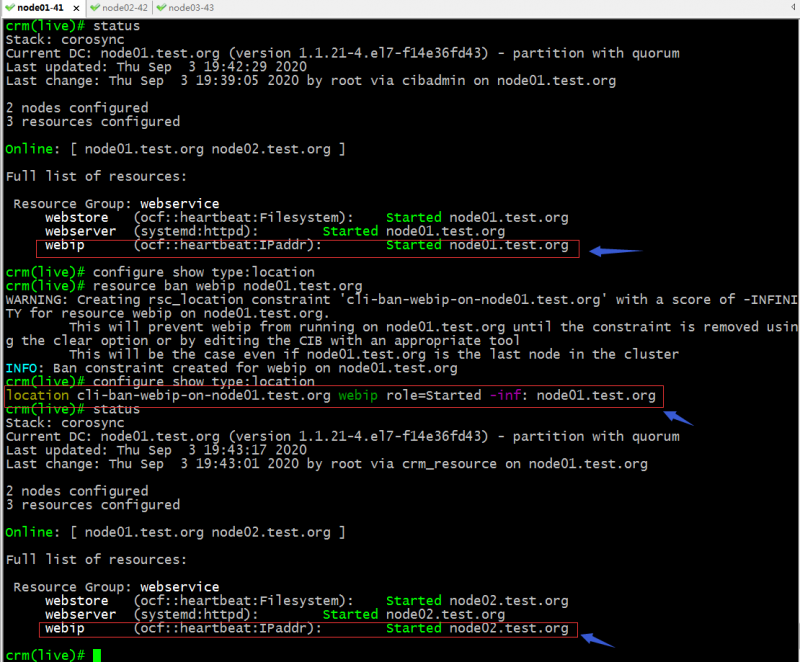
提示:可以看到我们把webip从node01迁出以后,它会在配置文件中创建一条资源对节点倾向性的规则,并且指明webip对我们ban指定的节点的倾向性为负无穷,这意味着只要有其他节点可以运行,对应资源绝不运行在node01上;由于webip同webserver、webstore都同属webservice这个组,所以对应组内的资源也会跟着webip的迁移而迁移;
cleanup:清除指定节点的状态信息;
示例:清除资源迁移过程中的错误信息;
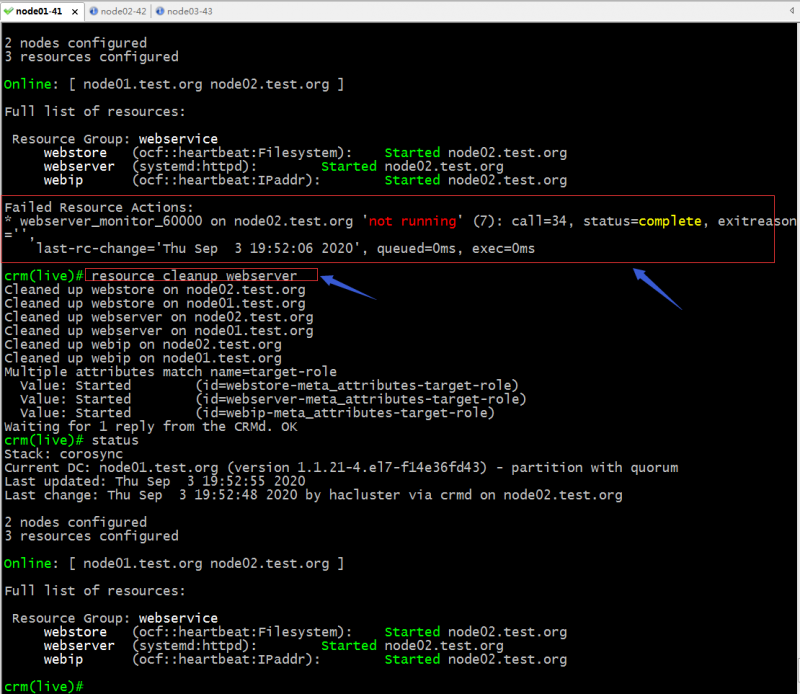
提示:默认情况我们指定资源没有在组内,它默认只会清除我们指定资源相关的状态信息,从上面截图可以看到,我们指定资源在组内,所以它将组内所有资源的状态信息一并清除了;
clear:清除指定资源约束关系;
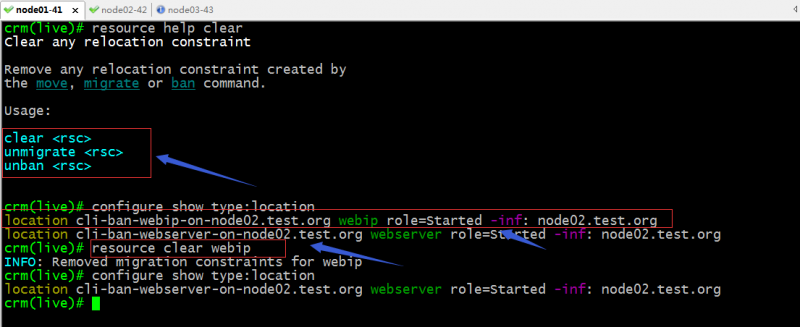
提示:可以看到我们指定资源的位置约束关系被清除掉了;其实我们在执行手动迁移资源时,它默认会在配置信息中给我们创建位置约束配置,clear相当于对迁移产生的约束配置做清除;
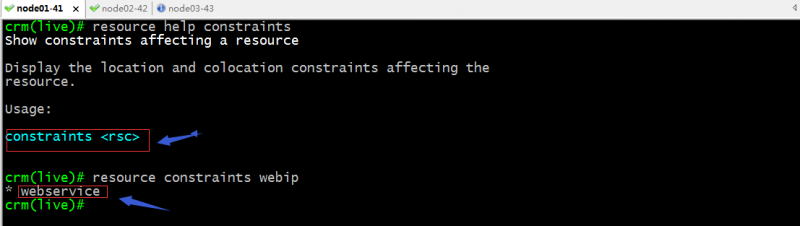
constraints:显示影响指定资源的约束;
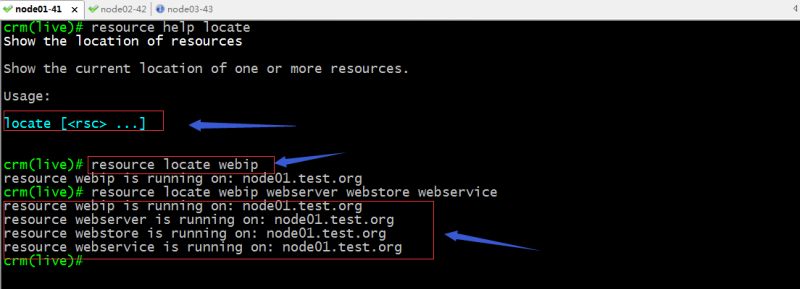
locate:显示资源运行的位置;
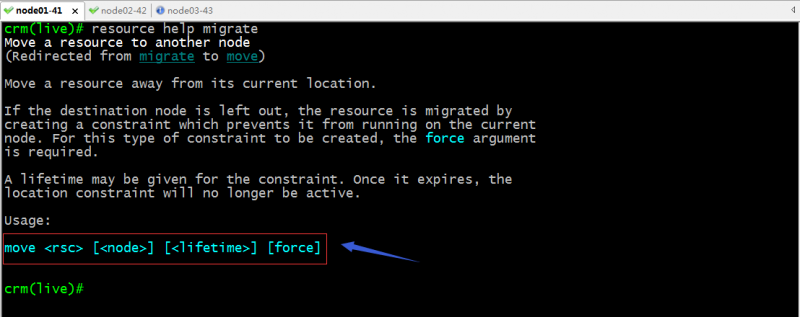
migrate/move:将指定资源手动迁移至指定节点;
命令语法格式
示例:将webip迁移至node02;
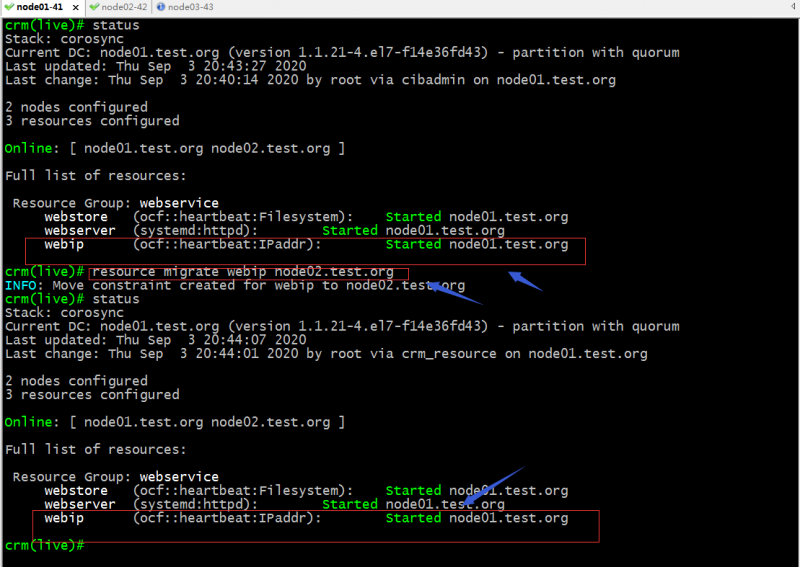
提示:可以看到对应webip这个资源并没有迁移;其实原因是webip同webserver、webstore在同一个组,而webserver对node02是负无穷,所以导致webservice迁移不到node02上去,所以组内的webip受组的约束,它也会签不上去;

提示:其实执行migrate/move操作它都会在配置文件中生成一条位置约束的配置;并且会配置对迁往的节点的倾向性为正无穷;如果资源在同一个组中,组中资源对同一节点的倾向性规则是:负无穷大于正无穷,正无穷大于特定的分数;计算一个组对节点的倾向性,就是组中各资源对节点倾向性之和;所以上面没有迁移成功的原因是webserver对node02的倾向性为负无穷;
删除webserver对node02的倾向性,看看webip是否会迁移至node02上?
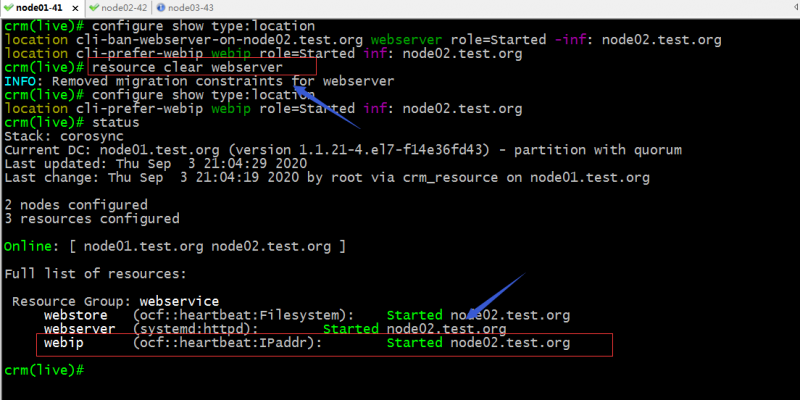
提示:可以看到删除了webserver对node02的倾向性以后,webip从node01迁往了node02,对应组也跟着迁往node02上了;
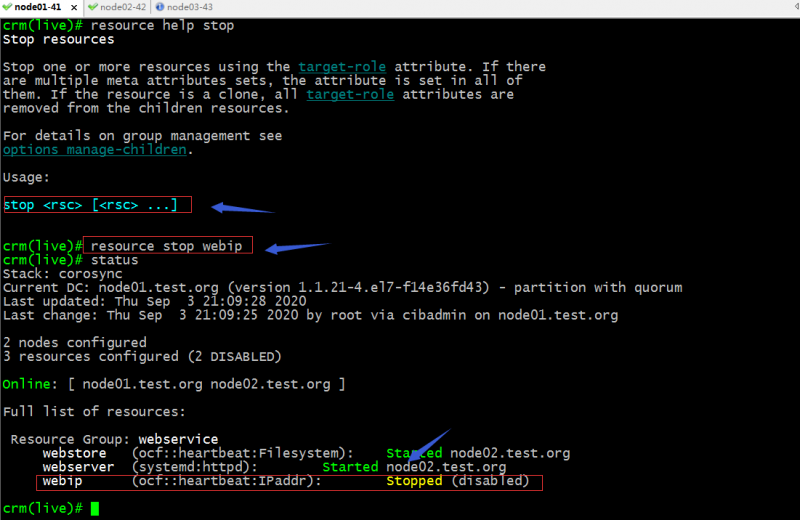
stop:停止指定资源;
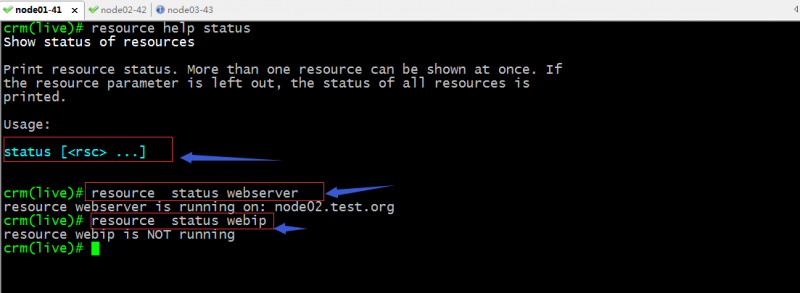
status:查看指定资源的状态信息
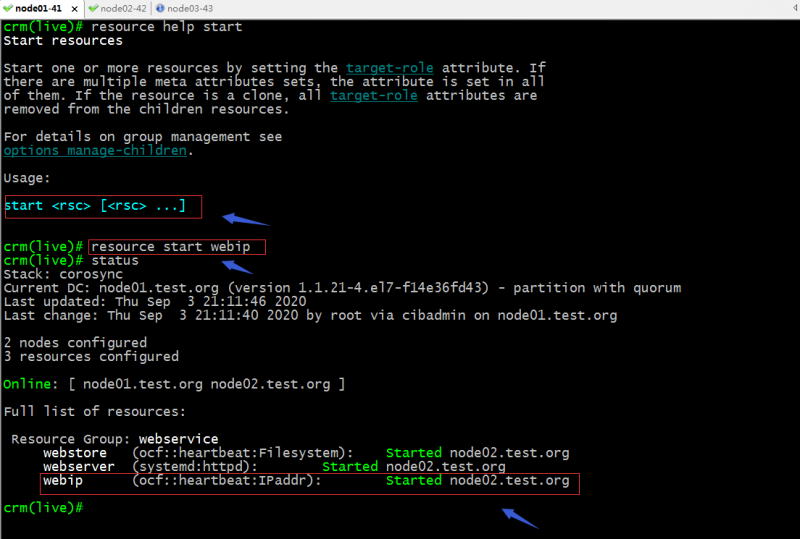
start:启动指定资源;
restart:重启指定资源;
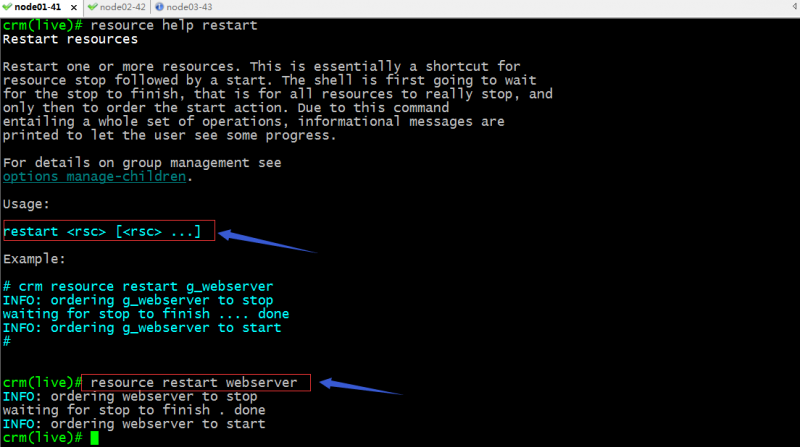
configure相关指令
delete:删除指定资源定义;
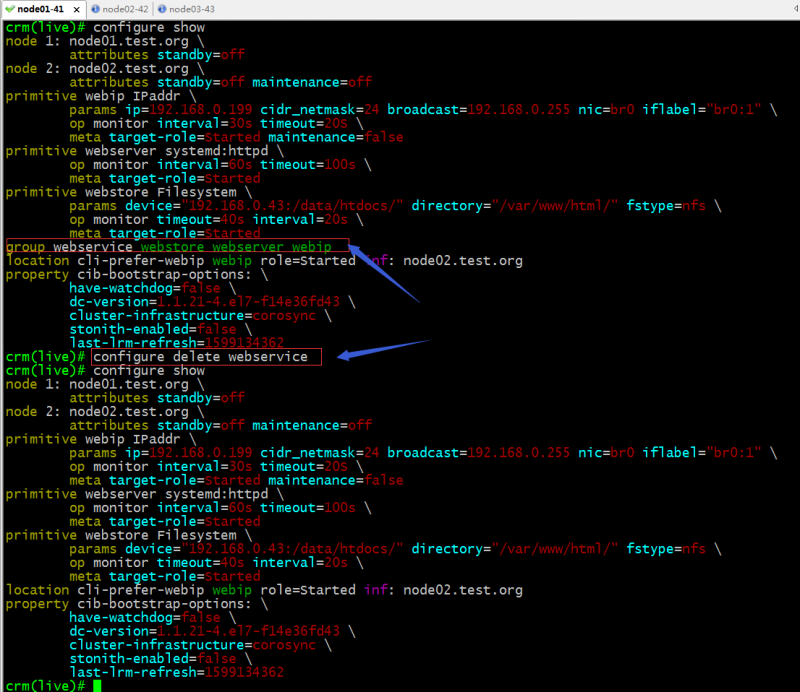
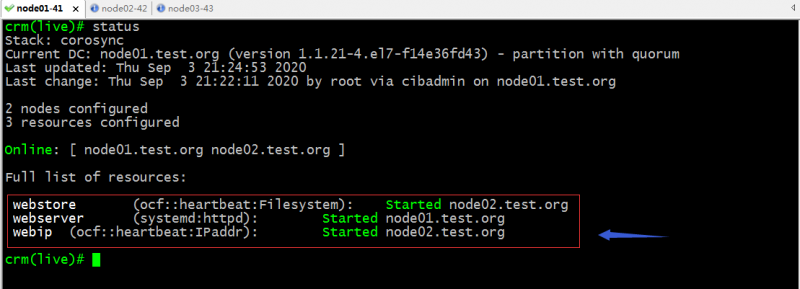
提示:删除了组资源以后,对应资源会重新分散的运行到各个节点,如果有位置约束的,会根据位置约束去运行,没有位置约束会负载均衡的方式分散在集群各节点;如下所示
location:设置指定资源对节点的倾向性;
命令语法帮助
Usage:location <id> <rsc> [<attributes>] {<node_pref>|<rules>}
rsc :: /<rsc-pattern>/
| { resource_sets }
| <rsc>
attributes :: role=<role> | resource-discovery=always|never|exclusive
node_pref :: <score>: <node>
rules ::
rule [id_spec] [$role=<role>] <score>: <expression>
[rule [id_spec] [$role=<role>] <score>: <expression> ...]
id_spec :: $id=<id> | $id-ref=<id>
score :: <number> | <attribute> | [-]inf
expression :: <simple_exp> [<bool_op> <simple_exp> ...]
bool_op :: or | and
simple_exp :: <attribute> [type:]<binary_op> <value>
| <unary_op> <attribute>
| date <date_expr>
type :: string | version | number
binary_op :: lt | gt | lte | gte | eq | ne
unary_op :: defined | not_defined
date_expr :: lt <end>
| gt <start>
| in start=<start> end=<end>
| in start=<start> <duration>
| spec <date_spec>
duration|date_spec ::
hours=<value>
| monthdays=<value>
| weekdays=<value>
| yearsdays=<value>
| months=<value>
| weeks=<value>
| years=<value>
| weekyears=<value>
| moon=<value>
Examples:
location conn_1 internal_www 100: node1
location conn_1 internal_www \
rule 50: #uname eq node1 \
rule pingd: defined pingd
location conn_2 dummy_float \
rule -inf: not_defined pingd or pingd number:lte 0
# never probe for rsc1 on node1
location no-probe rsc1 resource-discovery=never -inf: node1
示例:设置webstore对node01的倾向性为100分;

示例:设置webserver对node01的倾向性为正无穷;
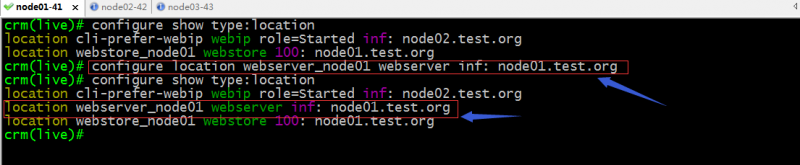
提示:资源对节点的倾向性除了定义其倾向性,它还取决于对节点的粘性;如下所示
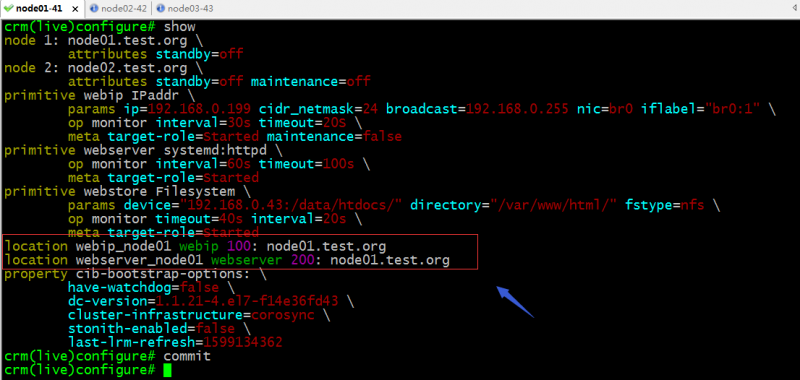
提示:假如集群有两个节点,分别是node01和node02,其中webip对node01的倾向性为100,webserver对node01的倾向性为200;
验证:把node01设置为standby状态,看看对应webip和webserver是否会迁往node02呢?
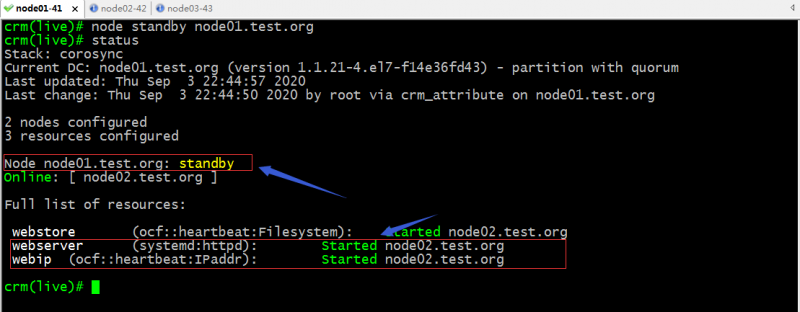
提示:正常情况webip和webserver都运行在node02上了;
如果node01再次上线,webip和webserver都会迁回node01?
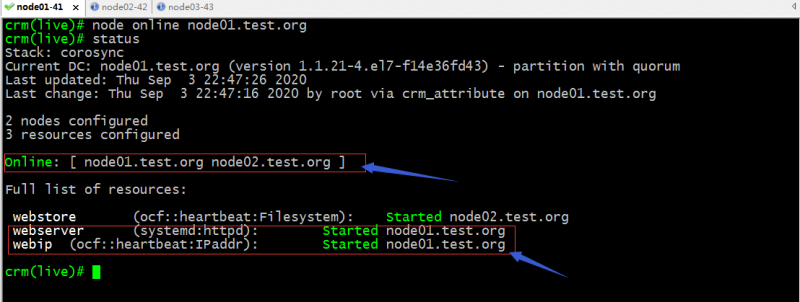
提示:默认情况它们都迁回了node01上;
设置默认资源对节点的粘性为500,然后再次把node01设置为standby模式,再上线,看看对应资源是否还会从node02迁回node01呢?
crm(live)configure# property default-resource-stickiness=default-resource-stickiness (integer, [(null)]):
Deprecated (use resource-stickiness in rsc_defaults instead)
crm(live)configure# property default-resource-stickiness=500
crm(live)configure# verify
ERROR: Warnings found during check: config may not be valid
crm(live)configure# commit
ERROR: Warnings found during check: config may not be valid
Do you still want to commit (y/n)? y
crm(live)configure# cd
crm(live)# status
Stack: corosync
Current DC: node01.test.org (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Thu Sep 3 22:56:52 2020
Last change: Thu Sep 3 22:56:39 2020 by root via cibadmin on node01.test.org
2 nodes configured
3 resources configured
Online: [ node01.test.org node02.test.org ]
Full list of resources:
webstore (ocf::heartbeat:Filesystem): Started node02.test.org
webserver (systemd:httpd): Started node01.test.org
webip (ocf::heartbeat:IPaddr): Started node01.test.org
crm(live)# node standby node01.test.org
crm(live)# status
Stack: corosync
Current DC: node01.test.org (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Thu Sep 3 22:57:16 2020
Last change: Thu Sep 3 22:57:10 2020 by root via crm_attribute on node01.test.org
2 nodes configured
3 resources configured
Node node01.test.org: standby
Online: [ node02.test.org ]
Full list of resources:
webstore (ocf::heartbeat:Filesystem): Started node02.test.org
webserver (systemd:httpd): Started node02.test.org
webip (ocf::heartbeat:IPaddr): Started node02.test.org
crm(live)# node online node01.test.org
crm(live)# status
Stack: corosync
Current DC: node01.test.org (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Thu Sep 3 22:57:34 2020
Last change: Thu Sep 3 22:57:26 2020 by root via crm_attribute on node01.test.org
2 nodes configured
3 resources configured
Online: [ node01.test.org node02.test.org ]
Full list of resources:
webstore (ocf::heartbeat:Filesystem): Started node02.test.org
webserver (systemd:httpd): Started node02.test.org
webip (ocf::heartbeat:IPaddr): Started node02.test.org
crm(live)#
提示:设置default-resource-stickiness时检查时提示错误,那个错误是说发现有警告信息,配置可能不生效,其实我们可以不用管它,直接提交就行;修改了资源默认对节点的粘性以后,再次把node01设置为standby状态,资源都迁往了node02上;node01再次上线资源却没有迁回node01上;这也就是我们刚才设置的资源默认对节点的粘性的原因,只有资源对node01的倾向性与node02的倾向性相差大于500,资源才会在node01恢复正常以后,从node02迁回node01;
colocation:定义资源与资源在一起的倾向性;
命令语法格式帮助
Usage:colocation <id> <score>: <rsc>[:<role>] <with-rsc>[:<role>]
[node-attribute=<node_attr>]
colocation <id> <score>: <resource_sets>
[node-attribute=<node_attr>]
resource_sets :: <resource_set> [<resource_set> ...]
resource_set :: ["("|"["] <rsc>[:<role>] [<rsc>[:<role>] ...] \
[<attributes>] [")"|"]"]
attributes :: [require-all=(true|false)] [sequential=(true|false)]
Example:
colocation never_put_apache_with_dummy -inf: apache dummy
colocation c1 inf: A ( B C )
示例:定义webip、webserver、webstore三者在一起的倾向性为正无穷
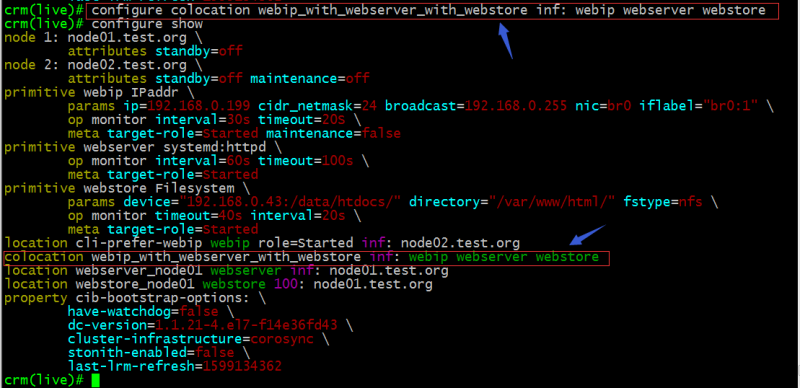
提示:定义资源与资源在一起倾向性为正无穷意味着这些资源必须要在一起,不能分开;如果是负无穷则表示相反的意思;
验证:查看集群状态信息,看看webip、webserver、webstore是否运行在同一节点?
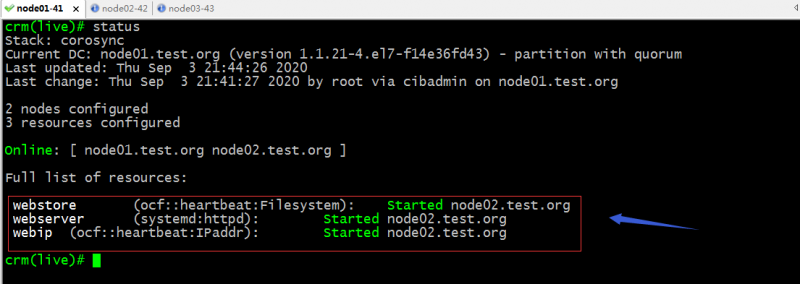
验证:将webip手动迁移至node01看看webserver和webstore是否会跟着迁移到node01上?
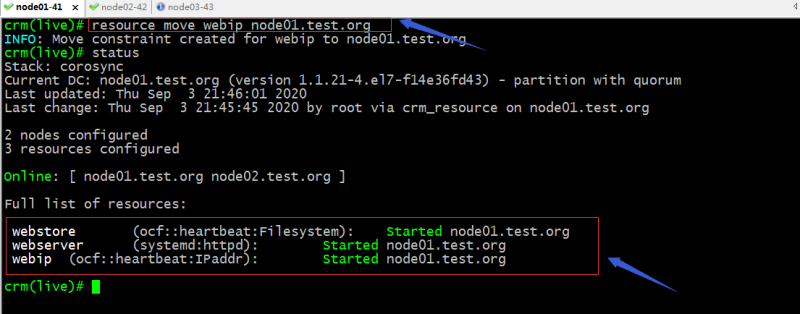
提示:可以看到手动迁移webip,webserver和webstore也会跟着迁移,这有点类似组的关系;
order:定义资源顺序约束;
命令语法帮助
Usage:order <id> [{kind|<score>}:] first then [symmetrical=<bool>]
order <id> [{kind|<score>}:] resource_sets [symmetrical=<bool>]
kind :: Mandatory | Optional | Serialize
first :: <rsc>[:<action>]
then :: <rsc>[:<action>]
resource_sets :: resource_set [resource_set ...]
resource_set :: ["["|"("] <rsc>[:<action>] [<rsc>[:<action>] ...] \
[attributes] ["]"|")"]
attributes :: [require-all=(true|false)] [sequential=(true|false)]
Example:
order o-1 Mandatory: apache:start ip_1
order o-2 Serialize: A ( B C )
order o-3 inf: [ A B ] C
order o-4 first-resource then-resource
提示:symmetrical表示是否启动对称停止顺序,默认是true;所谓对称停止顺序就是根据我们定义的启动顺序,先启动的后停止,后启动的先停止;Mandatory表示强制约束;optional表示可选;Serialize表示序列化,顺序启动,顺序停止;常用mandatory来约束启动顺序;
示例:强制约束webstore在webserver启动之前启动,webserver在webip之前启动
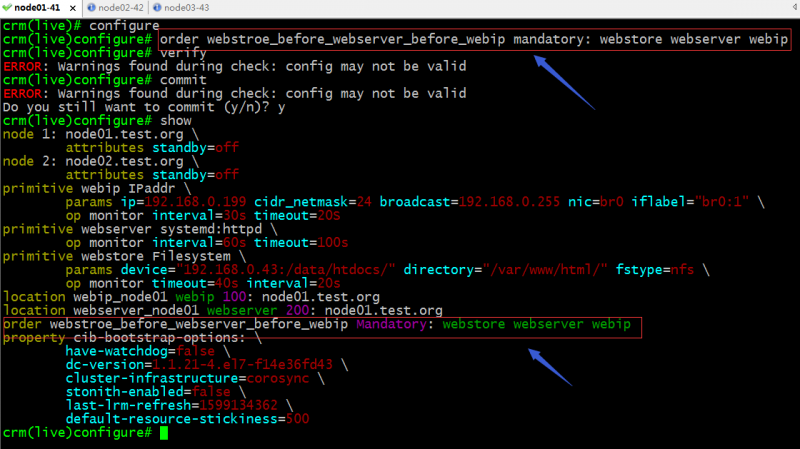
提示:以上配置表示webstore最先启动,其次是webserver,最后是webip;停止顺序则为相反的顺序,先停止webip,其次webserver,最后webstore;如果不想定义为对称停止顺序,可以将symmetrical设置为false即可;
验证:将node02设置为standby状态,查看集群状态,看看这三个资源的启动和停止方式是否是我们定义的顺序?
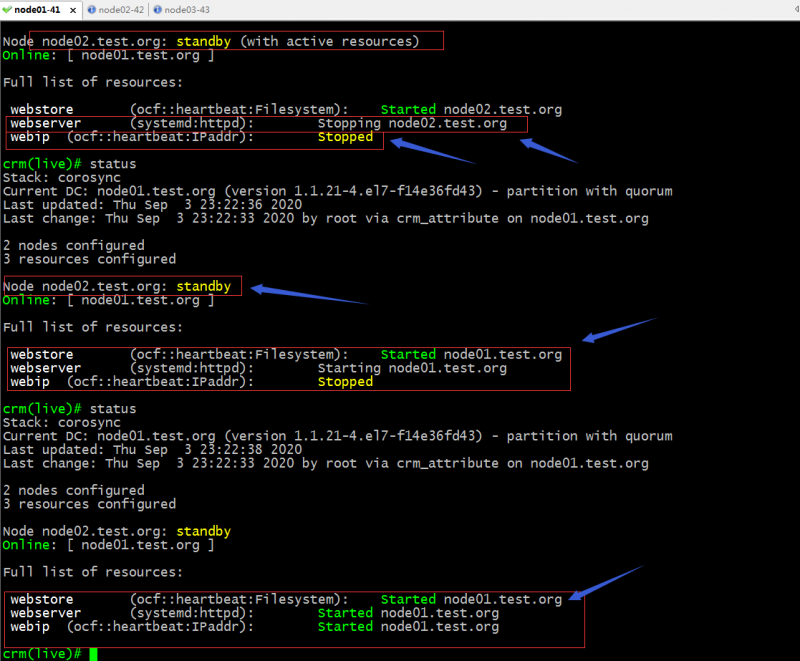
提示:可以看到把node02设置为standby状态以后,资源都迁往node01上去了;最开始停止的是webip,其次是webserver,最后是webstore;启动时,最先启动webstore,然后webserver,最后webip;和我们定义的启动顺序是一样的;
以上是 超融合架构hdfscorosync+保时捷718maker之crmgn使用(二) 的全部内容, 来源链接: utcz.com/a/49786.html