Metal新特性:大幅度提升iOS端性能
前言
Metal 是一个和 OpenGL ES 类似的面向底层的图形编程接口,通过使用相关的 api 可以直接操作 GPU ,最早在 2014 年的 WWDC 的时候发布。Metal 是 iOS 平台独有的,意味着它不能像 OpenGL ES 那样支持跨平台,但是它能最大的挖掘苹果移动设备的 GPU 能力,进行复杂的运算,像 Unity 等游戏引擎都通过 Metal 对 3D 能力进行了优化, App Store 还有相应的运用 Metal 技术的游戏专题。
阿里巴巴淘系技术部的闲鱼团队是比较早在客户端侧选择Flutter方案的技术团队,当前的闲鱼工程里也是一个较为复杂的Native-Flutter混合工程。作为一个2C的应用,性能和用户体验一直是闲鱼技术团队在开发中比较关注的点。而Metal这样的直接操作GPU的底层接口无疑会给闲鱼技术团队突破性能瓶颈提供一些新的思路。
下面会详细阐述一下这次大会Metal相关的新特性,以及对于闲鱼技术和整个淘系技术来说,这些新特性带来了哪些技术启发与思考。
( WWDC 2020精彩内容思否专栏:https://segmentfault.com/blog...
本篇内容来自于阿里巴巴淘系技术部,无线开发工程师岑彧。
更多精彩内容可关注【淘系技术】公众号。)
Metal相关新特性
1.Harness Apple GPUs with Metal
这一章其实主要介绍的是Apple GPU的在图形渲染上的原理和工作流,是一些比较底层的硬件原理。当我们使用Metal进行App或者是游戏的构建的时候,Metal会利用GPU的tile-based deferred rendering (TBDR)架构给应用和游戏带来非常可观的性能提升。这一章主要就是介绍GPU的的架构和能力,以及TBDR架构进行图像渲染的原理和流程。总之就是号召开发者们使用Metal来构建应用和游戏。因为这个session没有涉及到上层的软件开发,就不对视频的具体内容进行赘述了。详情可见:Harness Apple GPUs with Metal
2.Optimize Metal apps and games with GPU counters
这一章主要介绍了Xcode中的GPU性能分析工具Instrument,这个工具现在已经支持了GPU的性能分析。然后从多个方面分析了GPU的性能瓶颈,以及性能瓶颈出现时的优化点。总体来说就是通过性能分析工具来优化我们的App或者游戏,让整个画面更加流畅。整个章节主要分为五个部分:
1.总体介绍
这个环节主要是快速回顾了一下Apple的GPU的架构和渲染流程。然后因为很多渲染任务都需要在不同的硬件单元上进行,例如ALU和TPU。他们对不同的吞吐量有着不同的度量。有很多GPU的性能指标需要被考虑,所以推出了GPU性能计数器。这个计数器可能测量到GPU的利用率,过高和过低都会造成我们的渲染性能瓶颈。关于计数器的具体使用,参考官方的video效果会更好:Optimize Metal apps and games with GPU counters(6:37~9:57),主要使用了Instrument工具,关于工具的全面详细的使用可以参考WWDC19的session videoGetting Started with Instruments
2.性能瓶颈分析
这一章主要介绍了造成GPU性能瓶颈的各个方面以及它们的优化点。主要分为六个方面,如下图所示: 
1.Arithmetic(运算能力)
GPU中通常通过ALU(Arithmetic Logic Unit)来处理各种运算,例如位操作,关系操作等。他是着色器核心的一部分。在这里一些复杂的操作或者是高精度的浮点运算都会造成一些性能瓶颈,所以给出以下建议来进行优化: 
如上图所示,我们可以使用近似或者是查找表的方式来替换复杂的运算。此外,我们可以将全精度的浮点数替换为半精度的浮点数。尽量避免隐式转换,避免32位浮点数的输入。以及确保所有的着色器都使用Metal的“-ffast-math”来进行编译。
2.Texture Read and Write
GPU通过Texture Processing Unit来处理纹理的读写操作。当然在读写的过程中也会遇到一些性能瓶颈问题。这里从读和写两个部分分别来给出优化点:
1.Read

如上图所示,我们可以尝试使用mipmaps。此外,可以考虑更改过滤选项。例如,使用双线性代替三线性,降低像素大小。确保使用了纹理压缩,对Asset使用块压缩(如ASTC),对运行时生成的纹理使用无损纹理压缩。
2.Write

如上图所示,我们应该注意到像素的大小,以及每个像素中唯一MSAA样本的数量。此外,可以尝试一些优化一些逻辑写法。
3.Tile Memory Load and Store
图块内存是一组存储Thread Group和ImageBlock数据的高性能内存。当从ImageBlock或是Threadgroup读取或写入像素数据时,比如在使用Tile着色器时或者是计算分派时,可以访问到Tile内存。那当使用GPU性能计数器发现这个方面的性能瓶颈时,我们可以如下图所示进行优化。

考虑减少threadgroup的并行,或者是SIMD/Quadgroup操作。此外,确保将线程组的内存分配和访问对齐到16字节。最后,可以考虑重新排序内存访问模式。
4.Buffer Read and Write
在Metal中,缓冲区只被着色器核心访问。在这个地方发现了性能瓶颈。我们可以如下图所示进行优化: 
可以更大力度的压缩打包数据,例如使用例如packed_half3这样小的类型。此外,可以尝试向量化加载和存储。例如使用SIMD类型。避免寄存器溢出,以及可以使用纹理来平衡工作负载。
5.GPU Last Level Cache
如果在这个方面,我们的GPU性能计数器显示一个过高的值。我们可以如下图这样优化: 
如果纹理或者是缓存区也同样显示一个过高的值,我们可以把这个优化放到第一优先级。我们可以考虑减小工作集的大小。如果Shader正在使用Device Atomics,我们可以尝试重构我们的代码来使用Threadgroup Atomics。
6.Fragment Input Interpolation
分段输入插值。分段输入在渲染阶段由着色器核心进行插值。着色器核心有一个专用的分段输入插值器。这个是比较固定和高精度的功能。我们能优化的点不多,如下图所示: 
尽可能的移除传递给分段着色器的顶点属性。
3.内存带宽
内存带宽也是影响我们GPU性能的一个重要因素。如果在GPU性能计数器的内存带宽模块看到一个很高的值。我们就应该如下图所示来进行优化:

如果纹理和缓存区也同样显示比较高的值,那优化优先级应该排到第一位。优化方案也是较少Working Set的大小。此外,我们应该只加载当前渲染过程需要的数据,只存储未来渲染过程需要的数据。然后就是确保使用纹理压缩。
4.Occupancy

如果我们看到整体利用率比较低,这意味着Shader可能已经耗尽了一些内部资源,比如tile或者threadgroup内存。也可能是线程完成执行的速度比GPU创建新线程的速度快。
5.避免重复绘制

我们通过GPU计数器可以统计到重复绘制的区域,我们应该高校使用HSR来避免这样的重绘。我们可以如图所示的顺序来进行绘制。
3.Build GPU binaries with Metal
这一章主要给开发者们介绍了一种使用Metal的编程工作流,可以通过优化Metal的渲染编译模型来增强渲染管线,这个优化可以在应用程序启动,特别是首次启动时大大减少PSO(管线状态对象)的加载时间。可以让我们的图形渲染更加的高效。整个章节主要分为四个部分:
1.Metal的Shader编译模型概述
众所周知,Metal Shading Language是Apple为开发者提供的Shader编程语言,Metal会将编程语言编译成为一个叫做AIR的中间产物,然后AIR会在设备上进一步编译,生成每个GPU所需的特定的机器码。整个过程如下图所示:

上述过程在每个管线的生命周期中都会发生,当前Apple为了加速管线的重新编译和重新创建流程,会缓存一些Metal的方法变体,但是这个过程还是会造成屏幕的加载耗时过长。而且在当前的这个编译模型中,应用程序不能在不同的PSO(管线状态对象)中重用之前生成的机器码子程序。
所以我们需要一种方法来减少这个整个管线编译(即源代码->AIR->GPU二进制代码)的时间成本,还需要一种机制来支持不同PSO之间共享子程序和方法,这样就不需要将相同的代码多次编译或者是多次加载到内存中。这样开发者们就可以使用这套工具来优化App首次的启动体验。
2.Metal二进制文件介绍
Metal二进制文件就是解决上述需求的方法之一,现在开发者们可以直接使用Metal为二进制文件来控制PSO的缓存。开发者可以收集已编译的PSO,然后将它们存储到设备中,甚至可以分发到其他兼容的设备中(同样的GPU和同样的操作系统),这种二进制文件可以看做一种Asset。下面是一些例程和示意图:


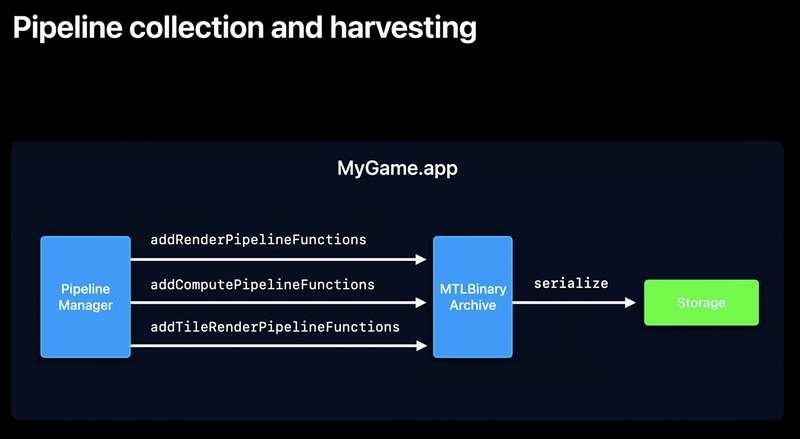

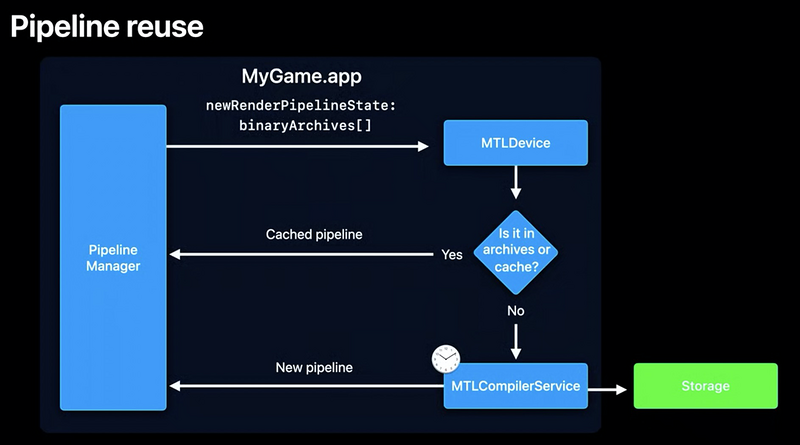

总的来说就是这个Metal二进制文件可以提供开发者手动管理管线缓存的方法,这样就可以从一个设备中获取这些文件并部署到其他兼容的设备上,在iOS环境下,极大地减少了第一次安装游戏或应用以及设备重启后的管道创建时间。可以优化应用的首次启动体验和冷启动体验。
3.Metal对动态库的支持
动态库将允许开发者编写可重用的库代码,却可以减少重新编译程序的时间和内存成本,这个特性将会允许开发者将计算着色器和程序库动态链接。而且和二进制文件一样,动态库也是可序列化和可转移的。这也是解决上述需求的方案之一。
在PSO生成的时候,每个应用程序都需要为程序library生成机器码,而且使用相同的程序库编译多个管线会导致生成重复的机器码。由于大量的编译和内存的增加,这个可能会导致更长的管线加载时间。而动态库就可以解决这个问题。
Metal Dynamic Library允许开发者以机器码的形式动态链接,加载和共享工具方法。代码可以在多个计算管线中重用,消除了重复编译和多个相同子程序的存储。而且这个 MTLDynamicLibrary是可序列化的,可以作为应用程序的Asset使用。MTLDynamicLibrary其实就是多个计算管线调用的导出方法的集合。
大致的工作流程如下:我们首先创建一个MTLLibrary作为我们指定的动态库,这个可以将我们的metal代码编译为AIR。然后我们调用方法makeDynamicLibrary,这个方法需要指定一个唯一的installname,在管线创建时,linker将会使用这个名字来加载动态库。这个方法可以将我们的动态库编译成为机器码。这就完成了动态库的创建。
对于动态库的使用来说:通过设置MTLCompileOptions里的libraries参数,就可以完成动态库的加载和使用了。代码如下:

4.开发工具介绍
这个部分主要介绍了构建Metal二进制文件和构建动态库的具体工具和方法。以视频的形式可能会更好的表现,详情可见:Build GPU binaries with Metal (从22:51开始)
4.Debug GPU-side errors in Metal
这一章主要介绍的是GPU侧的bug,当前如果我们的应用程序出现了GPU侧的bug,他的错误日志常常都不能让开发者很直观的定位到错误的代码范围和调用栈。所以在最新的Xcode中,增强了关于GPU侧的debug机制。可以像在代码侧发成的错误一样不但能定位到错误原因,还有错误的调用堆栈和各种信息都可以详细的查看到。让开发者能更好的修复代码造成的GPU侧的渲染错误。
1.Enhanced Command Buffer Errors
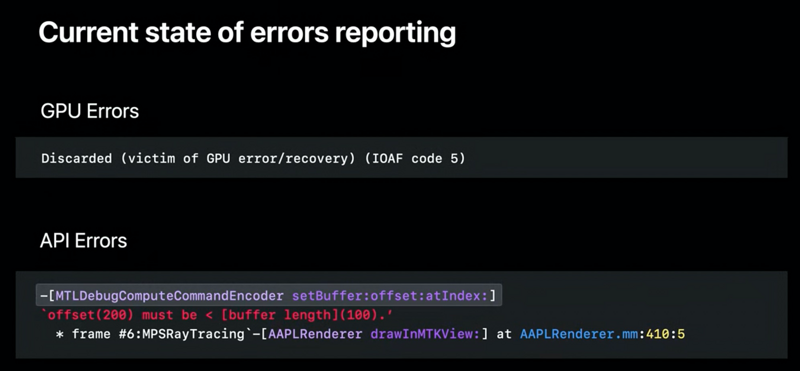
这是当前的错误日志上报,我们可以看到GPU侧的错误日志不像Api的错误日志一样可以让开发者很快的定位到错误原因和错误的代码位置。

而最新的Metal debugging工具就增强了这方面的能力,让Shader的code也可以像Api代码一样提供错误定位和分类能力。
我们通过以下代码便可以启用增强版的commandbuffer错误机制

错误一共有五种状态: 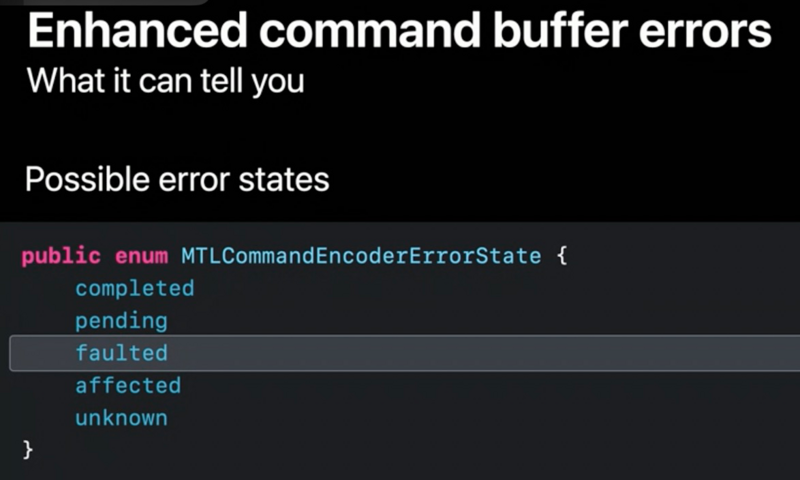
我们也可以通过以下代码来打印error:

开发者可以在开发时和测试时启用优化版的错误机制 
2.Shader Validation

如上图所示,这个功能可以在GPU侧发生渲染错误时自动定位和catch到错误并定位到代码,以及获取回溯栈帧。
我们可以在Xcode中按照以下流程来开启这个功能:
1.开启Metal中的两个Validation选项 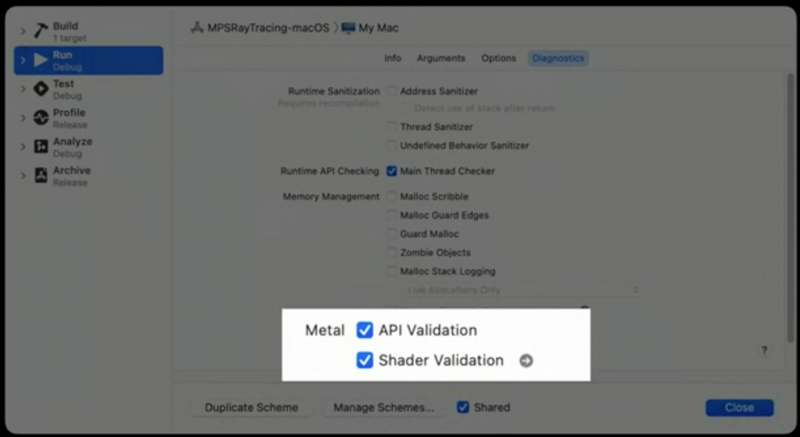
2.开启issue自动断点开关并配置类型和分类等选项 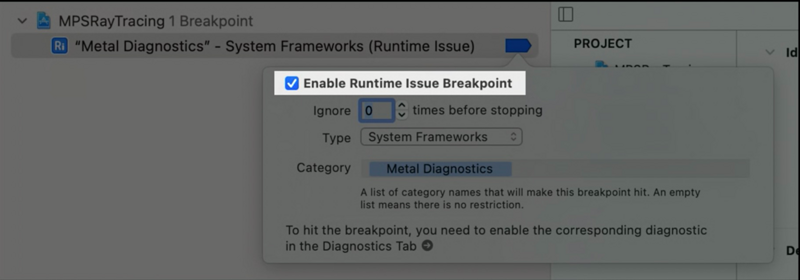
Video中用了一个demo来展示整个工作流,具体参见Debug GPU-side errors in Metal(11:25~14:45)大致流程如下图所示:

这是一个Demo应用程序,很明显它在渲染上出现了一些异常,但是因为是GPU侧的问题,所以开发者很难定位。但是通过上述的工作流开启Shader Validation之后。
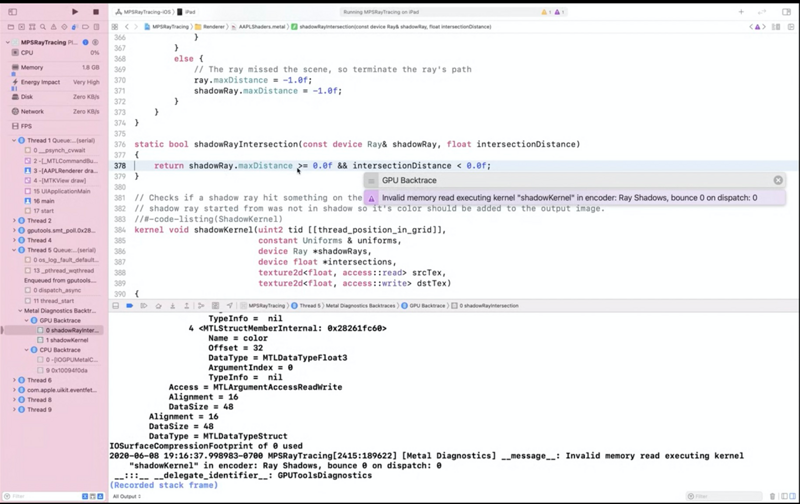
Xcode会自动断点到发生异常的地方,并展示出异常信息,这样就可以极大的提升开发者的错误修复效率。
5.Gain insights into your Metal app with Xcode 12
这一章主要讲的是Xcode12给Metal App提供了更多调试和分析的新工具。大致如下图所示: 
主要分为两个部分:
1.Metal Debugger
这个工具可以让开发者在App运行时,获取到想分析和调试的任何一帧,然后再进入Xcode提供的各种分析界面,总体情况,依赖情况,内存,带宽,GPU,Shader等各种具体的界面来对这一帧进行更加详细的分析和调试。整个过程使用视频的方式可能会更加高效,所以这里不会进行详细的赘述和分析。详情可以参见Gain insights into your Metal app with Xcode 12
2.Metal System Trace
整个工具跟之前提到过的Debugger相比,他的功能主要是让开发者可以随着时间的推移来捕获应用程序的各种信息和特征,可以让开发者很好的调试一些例如终端,帧丢失,内存泄漏等问题。而Debugger主要是对某一帧进行调试和分析。
他提供了一个叫做编码时间线的工具,可以让开发者查看到GPU在应用运行中的运行各种命令缓冲的情况。然后提供了一个叫做着色器时间线的工具,可以让开发者查看到各种着色器在代码运行期间运行的过程。然后还有GPU计数器的工具,这个工具我们在前文进行了详细的分析,主要是用于解决GPU的绘制性能问题的工具。然后最后一个工具就是内存分配跟踪工具,可以让开发者查看到应用程序运行过程中各种内存的分配和释放,可以帮助开发者解决内存泄漏问题或者是降低应用内存占用。
技术启发与思考
WWDC 20关于Metal的Session中,比较重要的就是官方提供了很多可供开发者进行GPU级别的调试工具以及性能分析工具。给比较成熟庞大而复杂的工程突破性能瓶颈,提供更加优秀的用户体验提供了一些思路。
闲鱼作为一个电商类App,随着功能和增多和以及工程的复杂化,在所难免的会遇到性能瓶颈,而闲鱼团队当前面对挑战的方式是从工程级别来进行优化。从Flutter的角度来看,WWDC 20 对于Metal的调试工具和性能分析工具的完善,无疑提供了更多的优化思路。这为未来运行在iOS上的应用的调优和突破性能瓶颈带来了新的思路和可能性。

对于跨平台框架,Apple有自家的SwiftUI,这也是此次大会的重点项目。不过无论是Flutter,还是SwiftUI,大家最后对应用的性能瓶颈突破和优化一定是殊途同归的,也就是深入到GPU级别来进行开发和调试以及性能分析。对于未来的客户端开发人员,理解GPU和进行GPU级别的编程肯定是不可或缺的技能点之一。
( WWDC 2020精彩内容思否专栏:https://segmentfault.com/blog...
本篇内容来自于阿里巴巴淘系技术部,无线开发工程师岑彧。
更多精彩内容可关注【淘系技术】公众号。)
以上是 Metal新特性:大幅度提升iOS端性能 的全部内容, 来源链接: utcz.com/a/49023.html