探究 flink1.11 Application 模式
随着流式计算的兴起,实时分析成为现代商业的利器。越来越多的平台和公司基于Apache Flink 构建他们的实时计算平台,并saas化。
这些平台旨在通过简化应用的提交来降低最终用户的使用负担。通常的做法是,会提供一个诸如管理平台的web程序,方便使用者提交应用,并且该平台集成了一些权限,监控等内容。这个管理平台我可以叫作部署服务。
但是现在这些平台遇到一个大问题是部署服务是一个消耗资源比较大的服务,并且很难计算出实际资源限制。比如,如果我们取负载的平均值,则可能导致部署服务的资源真实所需的值远远大于限制值,最坏的情况是在一定时间影响所有的线上应用。但是如果我们将取负载的最大值,又会造成很多不必要的浪费。基于此,Flink 1.11 引入了另外一种部署选项 Application Mode, 该模式允许更加轻量级,可扩展的应用提交进程,将之前客户端的应用部署能力均匀分散到集群的每个节点上。
为了理解这个问题以及Application Mode 是如何解决这个问题,我们将在下文介绍当前flink中应用执行的模式。
Flink 中的应用执行
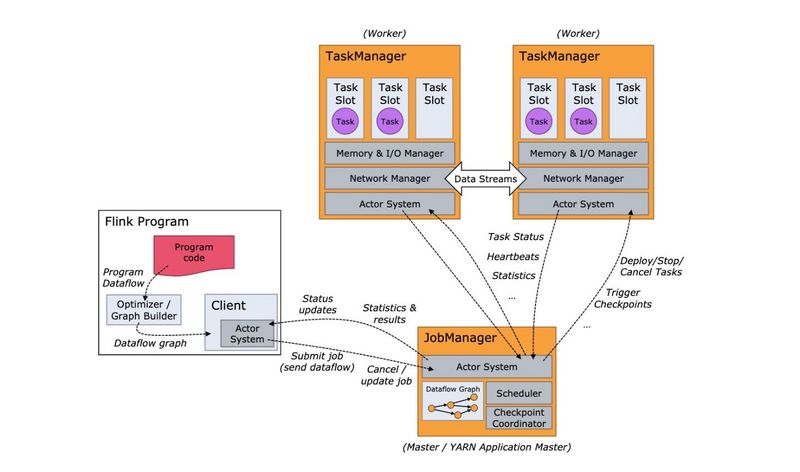
Flink中应用的执行会涉及到三部分:_Client,JobManager 和 TaskManagers。_Client 负责提交应用到集群,JobManager 负责应用执行期间一些必要的记录工作,TaskManager 负责具体的应用执行。具体的架构图如下:
当前部署模式
在引入Application Mode(Flink1.11) 之前,Flink 支持 Session 和 Per-Job 两种mode,这两种有不同的集群生命周期和资源隔离。
Session 模式
Session 模式假定已经存在一个集群,并任何的提交的应用都在该集群里执行。因此会导致资源的竞争。该模式的优势是你无需为每一个提交的任务花费精力去分解集群。但是,如果Job异常或是TaskManager 宕掉,那么该TaskManager运行的其他Job都会失败。除了影响到任务,也意味着潜在需要更多的恢复操作,重启所有的Job,会并发访问文件系统,会导致该文件系统对其他服务不可用。此外,单集群运行多个Job,意味着JobManager更大的负载。这种模式适合启动延迟非常重要的短期作业。
Per-Job 模式
在Per-Job模式下,集群管理器框架(例如YARN或Kubernetes)用于为每个提交的Job启动一个 Flink 集群。Job完成后,集群将关闭,所有残留的资源(例如文件)也将被清除。此模式可以更好地隔离资源,因为行为异常的Job不会影响任何其他Job。另外,由于每个应用程序都有其自己的JobManager,因此它将记录的负载分散到多个实体中。考虑到前面提到的Session模式的资源隔离问题,Per-Job模式适合长期运行的Job,这些Job可以接受启动延迟的增加以支持弹性。
总而言之,在Session 模式下,集群生命周期独立于集群上运行的任何Job,并且集群上运行的所有Job共享其资源。Per-Job模式选择为每个提交的Job承担拆分集群的费用,以提供更好的资源隔离保证,因为资源不会在Job之间共享。在这种情况下,集群的生命周期将与job的生命周期绑定在一起。
应用提交
Flink 应用的执行包含两个阶段:
pre-flight: 在main()方法调用之后开始。runtime: 一旦用户代码调用execute()就会触发该阶段。
main()方法使用Flink的API(DataStream API,Table API,DataSet API)之一构造用户程序。当main()方法调用env.execute()时,用户定义的pipeline将转换为Flink运行时可以理解的形式,称为job graph,并将其传送到集群中。
尽管有一些不同,但是 对于 Session 模式 和 Per-Job模式 , pre-flight 阶段都是在客户端完成的。
对于那些在自己本地计算机上提交任务的场景(本地计算机包含了所有运行Job所需的依赖),这通常不是问题。但是,对于通过诸如部署服务之类的远程进行提交的场景,此过程包括:
- 下载应用所需的依赖
- 执行
main()方法提取job graph - 将依赖和
job graph传输到集群 - 有可能需要等待结果
这样客户端大量消耗资源,因为它可能需要大量的网络带宽来下载依赖项并将二进制文件运送到集群,并且需要CPU周期来执行main()方法。随着更多用户共享同一客户端,此问题会更加明显。
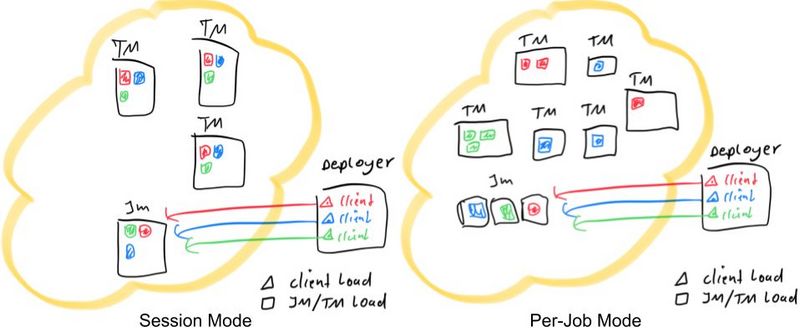
红色,蓝色和绿色代表3个应用程序,每个应用程序三个并发。黑色矩形代表不同的进程:TaskManagers,JobManagers和 Deployer(集中式部署服务)。并且我们假设在所有情况下都只有一个Deployer进程。彩色三角形表示提交进程的负载,而彩色矩形表示TaskManager和JobManager进程的负载。如图所示,不管是per-job 还是 session 模式, 部署程序承担相同的负载。它们的区别在于Job的分配和JobManager的负载。在session模式下,集群中的所有作业只有一个JobManager,而在per-job模式下,每个Job都有一个JobManager。另外,在session 模式下的Job 被随机分配给TaskManager,而在per-job 模式下,每个TaskManager只有单个Job。
Application 模式
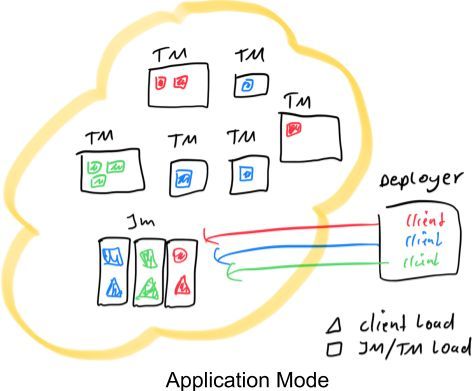
Application 模式 尝试去将per-job 模式的资源隔离性和轻量级,可扩展的应用提交进程相结合。为了实现这个目的,它会每个Job 创建一个集群,但是 应用的main()将被在JobManager 执行。
每个应用程序创建一个集群,可以看作创建仅在特定应用程序的Job之间共享的session集群,并在应用程序完成时销毁。通过这种架构,Application模式可以提供与 per-job 模式相同的资源隔离和负载平衡保证,但前提是保证一个完整应用程序的粒度。显然,属于同一应用程序的Job应该被关联起来,并视为一个单元。
在JobManager 中执行 main()方法,更大大减轻客户端的资源消耗。更进一步讲,由于每个应用程序有一个JobManager,因此可以更平均地分散网络负载。上图对此进行了说明,在该图中,这次客户端负载已转移到每个应用程序的JobManager。
与per-job 模式相比,Application 模式允许提交由多个Job组成的应用程序。Job执行的顺序不受部署模式的影响,但受启动Job的调用的影响。使用阻塞的 execute()方法,将是一个顺序执行的效果,结果就是"下一个"Job的执行被推迟到“该”Job完成为止。相反,一旦提交当前作业,非阻塞executeAsync()方法将立即继续提交“下一个”Job。
减少网络需求
如上所述,通过在JobManager上执行应用程序的main()方法,Application 模式可以节省很多提交应用所需的资源。但是仍有改进的空间。
专注于YARN, 因为社区对于yarn的优化支持更全面。即使使用 Application 模式,仍然需要客户端将用户jar发送到JobManager。此外,对于每个应用程序,客户端都必须将“ flink-dist”路径输送到集群,该目录包含框架本身的二进制文件,包括flink-dist.jar,lib/ 和plugin/ 目录。这两个可以占用客户端大量的带宽。此外,在每个提交中传送相同的flink-dist二进制文件不仅浪费带宽,而且浪费存储空间,只需允许应用程序共享相同的二进制文件就可以缓解。
对于Flink1.11 , 引入了下面的两个选项可供大家使用:
- 指定目录的远程路径,YARN可以在该目录中找到Flink分发二进制文件
- 指定YARN可以在其中找到用户jar的远程路径。
对于1.,我们利用YARN的分布式缓存,并允许应用程序共享这些二进制文件。因此,如果由于先前在同一TaskManager上执行的应用程序而导致某个应用程序恰巧在其TaskManager的本地存储上找到Flink的副本,则它甚至不必在内部下载它。
示例: Application 模式 on Yarn
有关完整说明,请参阅正式的Flink文档,尤其是涉及集群管理框架,例如YARN或Kubernetes。在这里,我们将提供有关YARN的一些示例:
Application 模式下,使用以下语句提交一个应用:
./bin/flink run-application -t yarn-application ./MyApplication.jar使用此命令,所有配置参数都可以通过其配置选项(以-D为前缀)来指定。有关可用配置选项的目录,请参阅Flink的配置页面。
例如,用于指定JobManager和TaskManager的内存大小的命令如下所示:
./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
./MyApplication.jar
为了进一步节省将Flink发行版传送到集群的带宽,请考虑将Flink发行版预上传到YARN可以访问的位置,并使用yarn.provided.lib.dirs配置选项,如下所示:
./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
./MyApplication.jar
最后,为了进一步节省提交应用程序jar所需的带宽,您可以将其预上传到HDFS,并指定指向./MyApplication.jar的远程路径,如下所示:
./bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
hdfs://myhdfs/jars/MyApplication.jar
这将使Job提交特别轻巧,因为所需的Flink jar和应用程序jar将从指定的远程位置获取,而不是由客户端传送到集群。客户端将唯一传送到集群的是你的应用程序配置,其中包括上述所有路径。
PS: 本文属于翻译,原文
以上是 探究 flink1.11 Application 模式 的全部内容, 来源链接: utcz.com/a/48927.html