我的程序跑了60多小时,就是为了让你看一眼JDK的BUG导致的内存泄漏。
这次的文章从JDK的J.U.C包下的ConcurrentLinkedQueue队列的一个BUG讲起。jetty框架里面的线程池用到了这个队列,导致了内存泄漏。
同时通过jconsole、VisualVM、jmc这三个可视化监控工具,让你看见“内存泄漏”的发生。有点意思,大家一起看看。
从一个BUG说起
前段时间翻到了一个 JDK 有点意思的 BUG,带大家一起瞅瞅。
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8137185
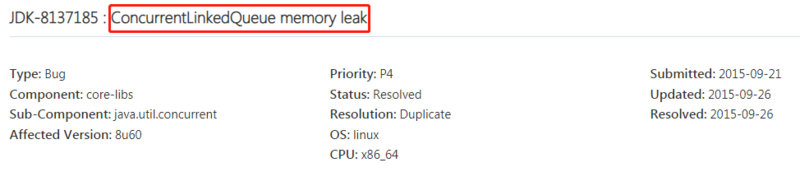
memory leak,内存泄漏。
是谁导致的内存泄漏呢?
ConcurrentLinkedQueue,这个队列。
这个 BUG 里面说,在 jetty 项目里面也爆出了这个 BUG:

我看了一下,觉得 jetty 的这个写的挺有意思的。
我按照 jetty 的这个讲吧,反正都是同一个 JDK BUG 导致的。地址如下:
https://bugs.eclipse.org/bugs/show_bug.cgi?id=477817
我用我八级半的蹩脚英语给大家翻译一下这个叫做 max 的同学说了些什么。
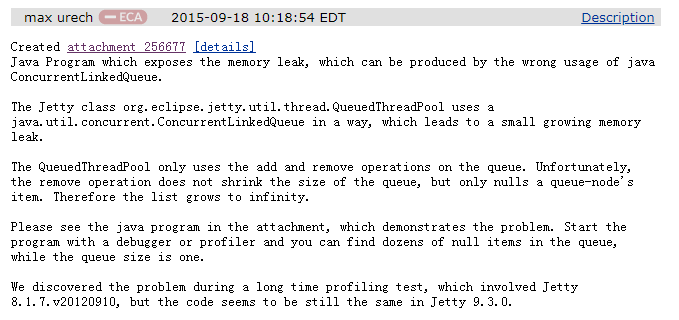
他说:在 Java 项目里面,错误的使用 ConcurrentLinkedQueue(文章后面用缩写 CLQ 代替)会导致内存泄漏的问题。
在 jetty 的 QueuedThreadPool 这个线程池里面,使用了 CLQ 这个队列,它会导致内存缓慢增长,最终引发内存泄漏。
虽然 QueuedThreadPool 仅仅使用了这个队列的 add 方法和 remove 方法。但不幸的是,remove 方法不会把队列的大小变小,只会使队列里面被删除的 node 为空。因此,该列表将增长到无穷大。
然后他给了一个附件,附件里面是一段程序,可以演示这个问题。
我们先不看他的程序,后面我们统一演示这个问题。
先给大家看一下 jetty 的 QueuedThreadPool 线程池。
看哪个版本的 jetty 呢?

可以看到这个 BUG 是在 2015 年 9 月 18 日被爆出来的。所以,我们找一个这个日期之前的版本就行。
于是我找了一个 2015 年 9 月 3 日发布的 maven 版本:
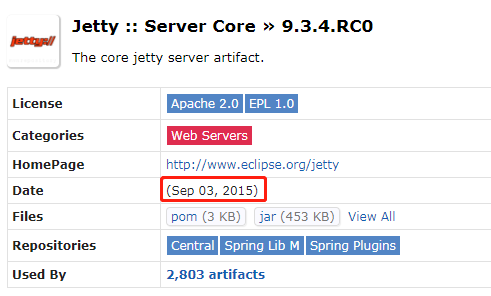
在这个版本里面的 QueuedThreadPool 是这样的:
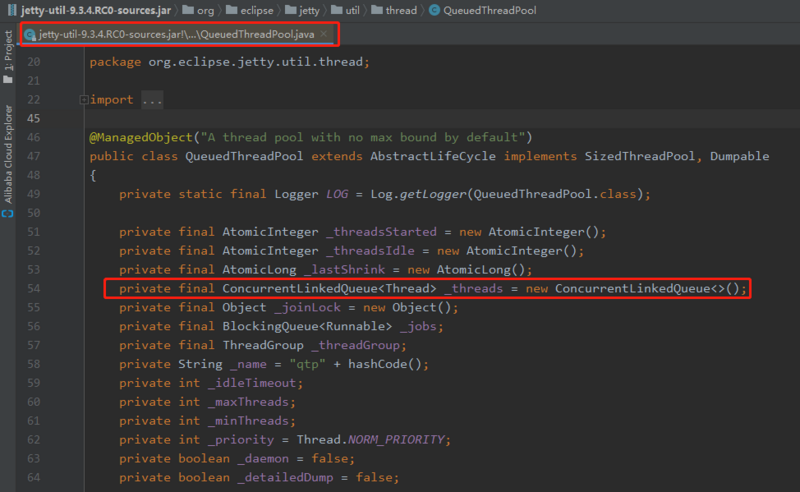
可以看到,它确实使用了 CLQ 队列。
而从这个对象所有被调用的地方来看,jetty 只使用了这个队列的 size、add、remove(obj) 方法:
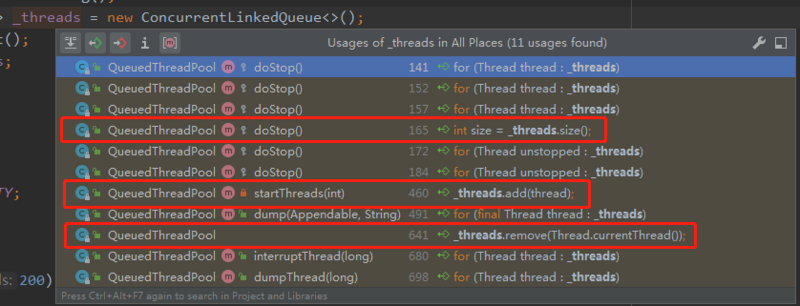
和前面 max 同学描述的一致。
然后这个 max 同学给了几张图片,来佐证他的论点:
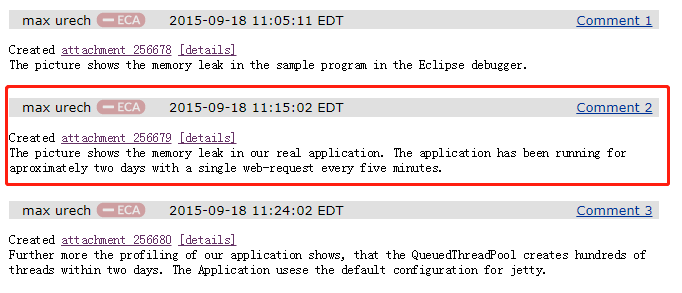
主要关注我框起来的地方,就是说他展示了一张图片。可以从这图片中看出内存泄漏的问题,而这个图片的来源是他们真实的项目。
这个项目已经运行了大约两天,每五分钟就会有一个 web 请求过来。
下面是他给出的图片:
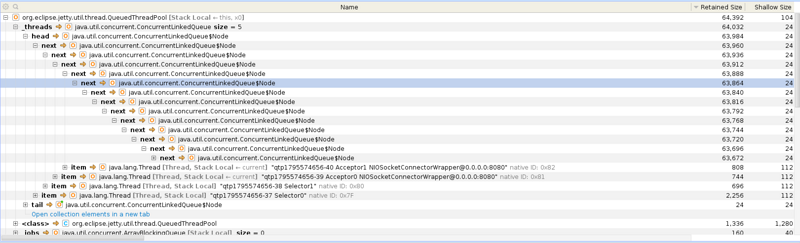
从他的这个图片中,我就只看出了 CLQ 的 node 很多。
但是他说了,他这个项目请求量并不大,用的 jetty 框架也不应该创建这么多的 node 出来。
好了,我们前面分析了 max 同学说的这个问题,接下来就是大佬出场,来解惑了:
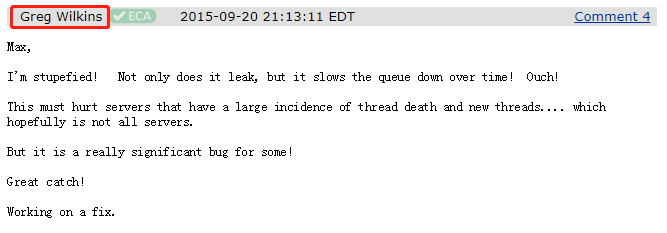
我们先不看回答,先看看回答问题的人是谁。
Greg Wilkins,何许人也?
我找到了他的领英地址:
https://www.linkedin.com/in/gregwilkins/?originalSubdomain=au
jetty 项目的领导者,短短的几个单词,就足以让你直呼牛逼。
高端的食材,往往只需要最简单的烹饪。高端的人才,往往只需要寥寥数语的介绍。
大佬的简历就是这么朴实无华,且枯燥。
而且,你看这个头像。哎,酸了酸了。果然再次印证了这句话:变秃了,也变强了,并不适用于外国的神仙。

好了,我们看一下这个 jetty 项目的领导者是怎么回答这个问题的:
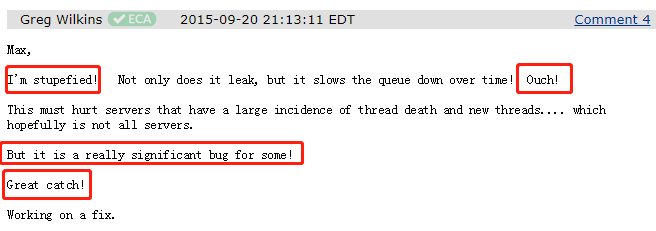
首先他用 stupefied 表示了非常的震惊!然后,用到了 Ouch 语气词。相当于我们常说的:

他说:卧槽,我发现它不仅导致内存泄漏,而且会随着时间的推移,导致队列越来越慢。太TM震惊了。

这个问题一定会对使用大量线程的服务器产生影响......希望不是所有的服务器都会有影响。
但不管是不是所有的服务器都有这个问题,只要出现了这个问题,对于某些服务器来说,它一定是一个非常严重的 BUG。
然后他说了一个 Great catch!我理解这是一个语气助词。就类似于:太牛逼了。
这个不好翻译,我贴一个例句,大家自己去体会一下吧:

我也是没想到,在技术文里面还给大家教起了英文。
最后他说:我正在修复这个问题。
然后,在 7 分 37 秒之后, Greg 又回复了一次:
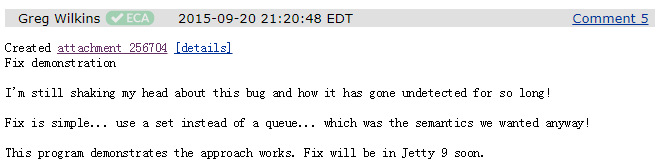
可以看出,过了快 8 分钟,他还在持续震惊。我怀疑这 8 分钟里面他一直在摇头。
他说:我还在为这个 BUG 摇头,它怎么这么久都没被发现呢!对于 jetty 来说修复起来非常的简单,使用 set 结构代替 queue 队列即可实现一样的效果。
那我们看一下修复之后的 jetty 中的 QueuedThreadPool 是怎样的,这里我用的是 2015 年 10 月 6 日发布的一个包,也就是这个 BUG 爆出之后的最近的一个包:
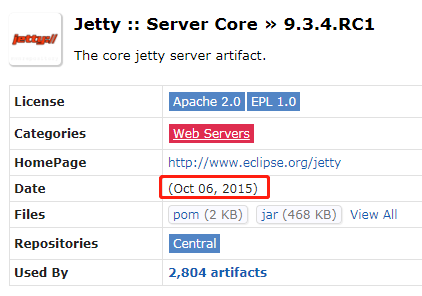
里面对应的代码是这样的:
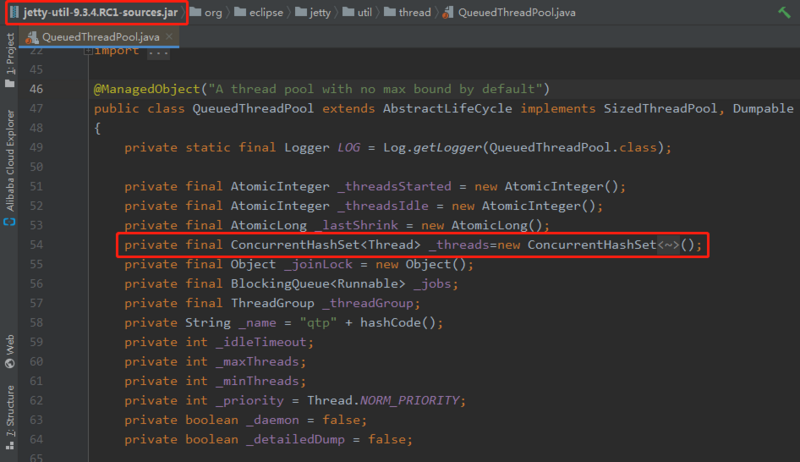
简单粗暴的用 CurrentHashSet 代替了 CLQ。
因为这个 BUG 在 JDK 中是已经修复了,出于好奇,我想看看 CLQ 还有没有机会重新站出来。

于是我看了一下今年发布的最新版本里面的代码:
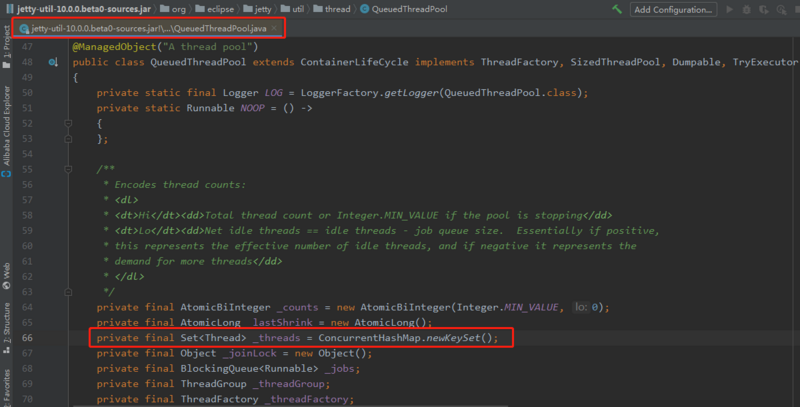
既不是用的 CurrentHashSet ,也没有给 CLQ 机会。
而是 JDK 8 的 ConcurrentHashMap 里面的 newKeySet 方法,C 位出道:
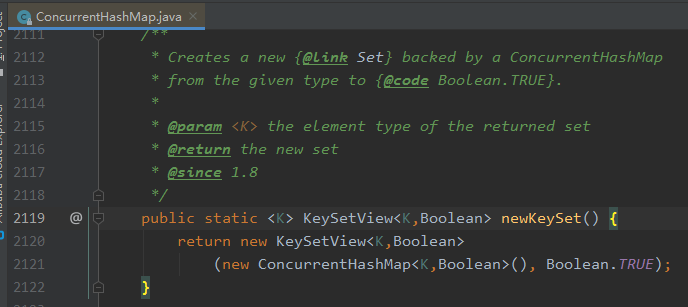
这是一个小小的 jetty 线程池的演变过程。恭喜你,又学到了一个基本上不会用到的知识点。
回到 Greg 的回复中,这次的回复里面,他还给了一个修复的演示实例,下一小节我会针对这个实例进行解读。
在 23 分钟之后,他就提交代码修复完成了。

从第一次回复帖子,到定位问题,再到提交代码,用了 30 分钟的时间。

然后在凌晨 2 点 57 分(这个时间点,大佬都是不用睡觉的吗?还是说刚修完福报,下班了), max 回复到:

我不敢相信 CLQ 使用起来会有这样的问题,他们至少应该在 API 文档里面说明一下。
这里的他们,应该指的是 JDK 团队的成员,特指 Doug Lea,毕竟是他老爷子的作品。
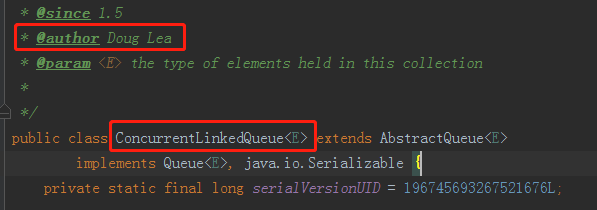
为什么没有在 API 文档里面说明呢?
因为他们自己也不知道有这个 BUG 啊。
Greg 连着回复了两条,并且直接指出了解决方案:
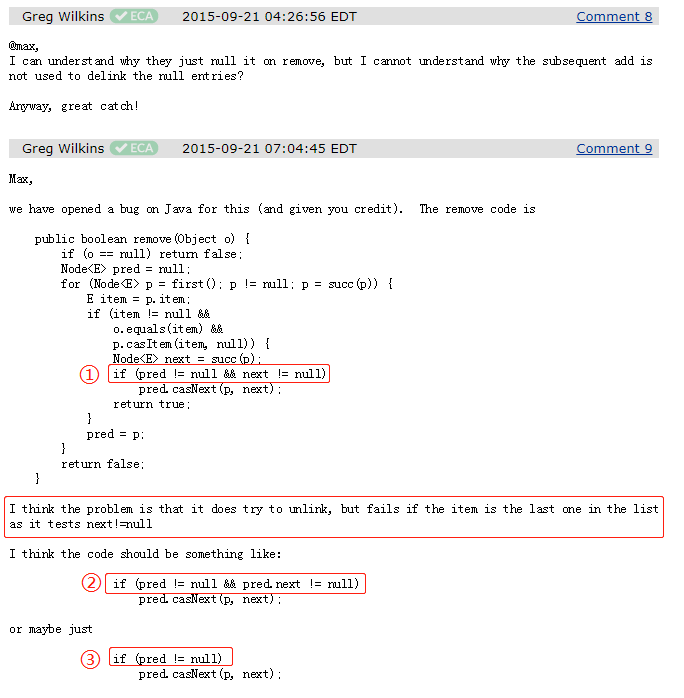
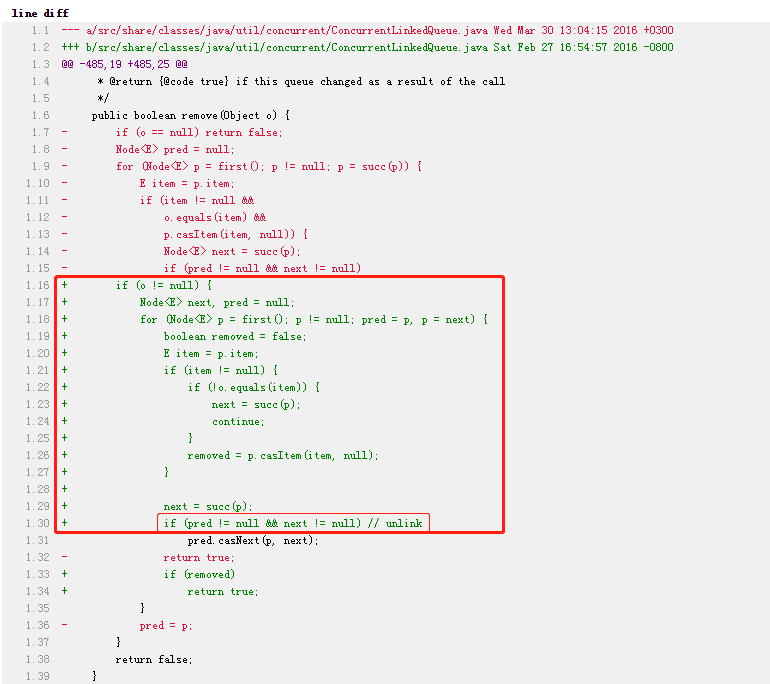
问题的原因是 remove 方法的源码里面,有上图中标号为 ① 的这样一行代码。
这行代码会去取消被移除的这个 node (其值已经被替换为 null)和 list 之间的链接,然后可以让 GC 回收这个 node。
但是,当集合里面只有一个元素的时候, next != null 这个判断是不成立的。
所以就会出现这个需要移除的节点已经被置为 null 了,但却没有取消和队列之间的连接,导致 GC 线程不会回收这个节点。
他给出的解决方案也很简单,就是标号为②、③的地方。总之,只需要让代码执行 pred.casNext 方法就行。
总之一句话,导致内存泄漏的原因是一个被置为 null 的 node,由于代码问题,导致该 node 节点,既不会被使用,也不会被 GC 回收掉。
如果你还没理解到这个 BUG 的原因,说明你对 CLQ 这个队列的结构还不太清晰。
那么我建议你读一下《Java并发编程的艺术》这一本书,里面有一小节专门讲这个队列的,图文并茂,写的还是非常清晰。

这个 BUG 在 jetty 里面的来龙去脉算是说清楚了。
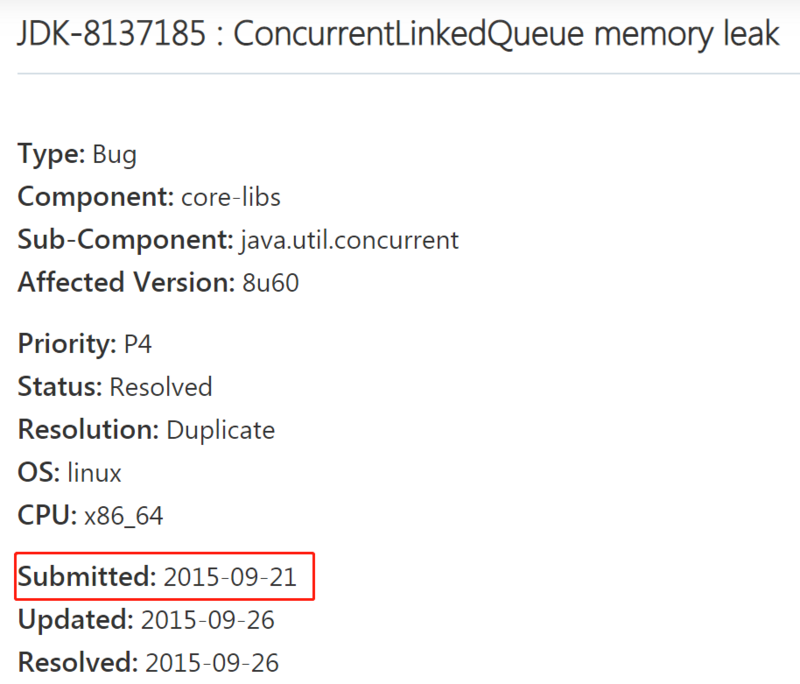
然后,我们再回到 JDK BUG 的这个链接中去:
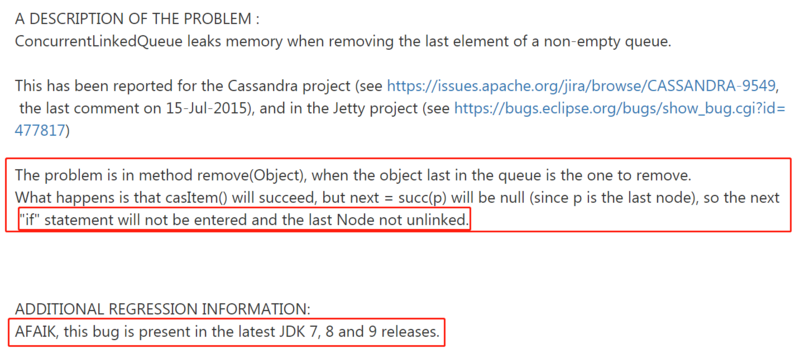
他这里写的原因就是我前面说的原因,没有 unlink,所以不能被回收。
而且他说到:这个 BUG 在最新的JDK 7、8和9版本中都存在。
他说的最新是指截止这个 BUG 被提出来之前:
Demo跑起来
这一小节里面,我们跑一下 Greg 给的那个修复 Demo,亲手去摸一下这个 BUG 的样子。
https://bugs.eclipse.org/bugs/attachment.cgi?id=256704
你可以打开上面那个链接,直接复制粘贴到你的 IDEA 里面去:
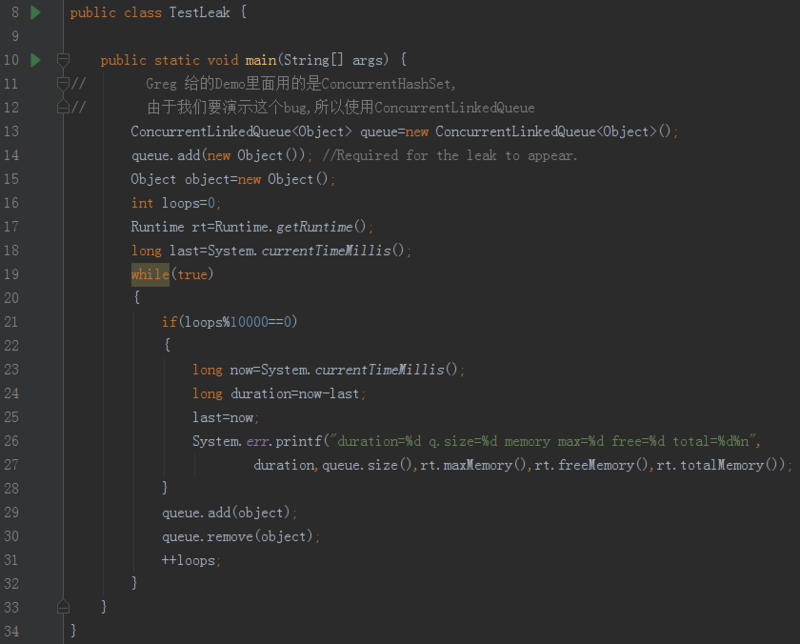
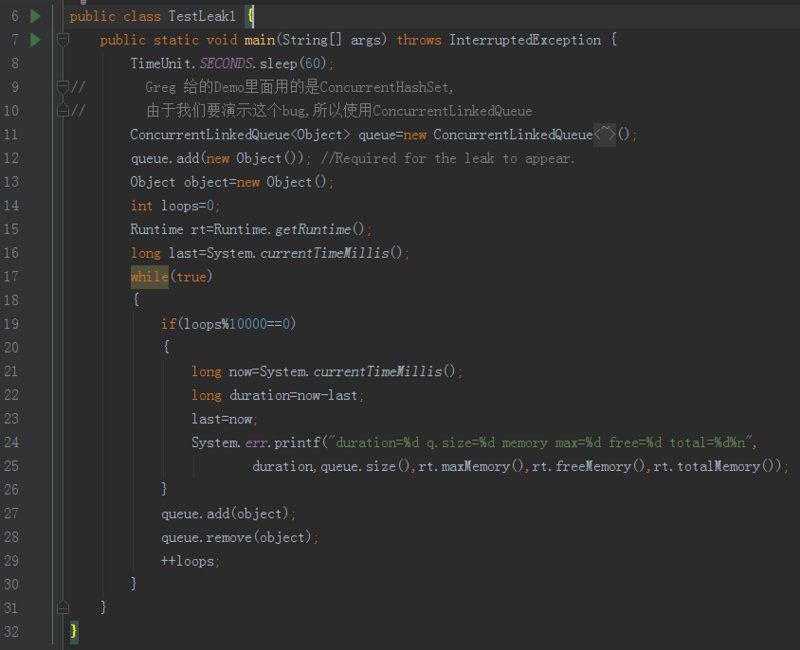
注意第 13 行,因为 Greg 给的是修复 Demo,所以用的是 ConcurrentHashSet,由于我们要演示这个bug,所以使用 CLQ。
这个 Demo 就是在死循环里面调用 queue 的 add(obj) 和 remove(obj) 方法。每循环 10000 次,就打印出时间间隔、队列大小、最大内存、剩余内存、总内存的值。
最终运行起来的效果是这样的(JDK 版本是 1.7.0_71):

可以看到每次打印 duration 这个时间间隔是越来越大,队列大小始终为 1。
后面三个内存相关的参数可以先不关心,下一小节我们用图形化工具来看。
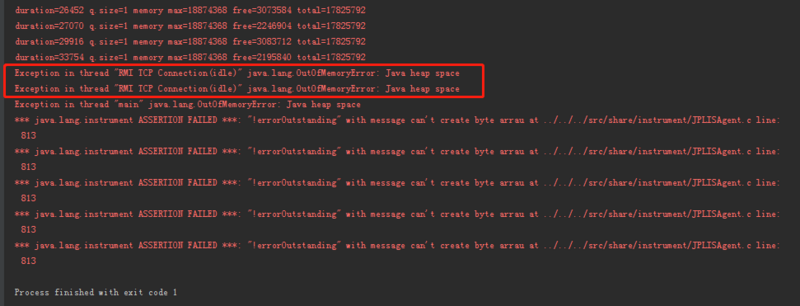
你知道上面这个程序,到我写文章写到这里的时候,我跑了多久了吗?
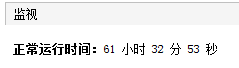
61 小时 32 分 53 秒。
最新一次循环 10000 次所需要的时间间隔是 575615ms,快接近 10 分钟:
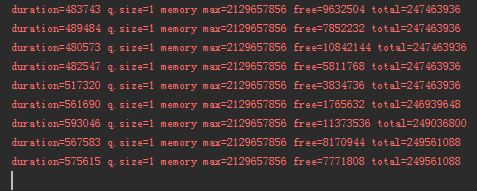
这就是 Greg 说的:不仅仅是内存泄漏,而且越来越慢。

但是,同样的程序,我用 JDK 1.8.0_212 版本跑的时候情况却是这样的:

时间间隔很稳定,不会随着时间的推移而增加。
说明这个版本是修复了这个 BUG 的,我带大家看看源码:
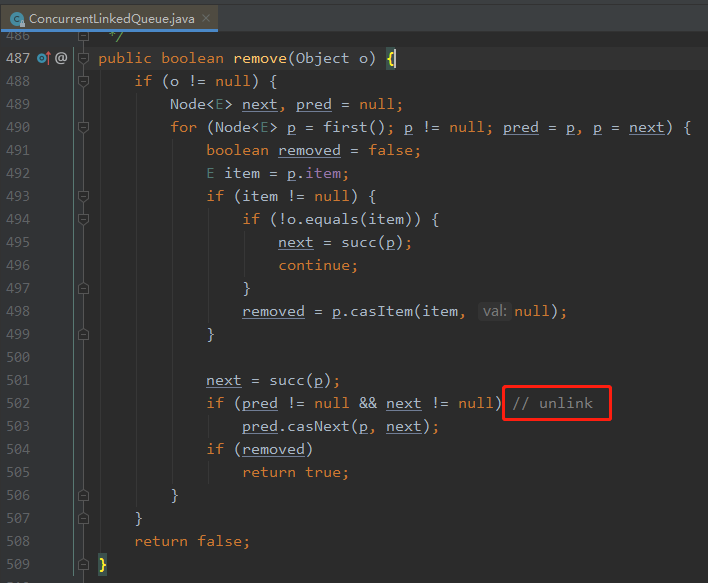
JDK 1.8.0_212 版本的源码里面,在 CLQ 的 remove(obj) 方法的 502 行末尾注释了一个 unlink。
官方的修复方法可以看这里:
http://hg.openjdk.java.net/jdk8u/jdk8u-dev/jdk/rev/8efe549f3c87
改动比较多,但是原理还是和之前分析的一样:
我仅仅在两个 JDK 版本中跑过示例代码。
在 JDK 1.8.0_212 没有发现内存泄漏的问题,我看了对应的 remove(obj) 方法的源码确实是修复了。
在 JDK 1.7.0_71 中可以看到内存泄漏的问题。
unlink,一个简简单单的词,背后原来藏了这么多故事。

jconsole、VisualVM、jmc
既然都说到内存泄漏了,那必须得介绍几个可视化的故障排除工具。
前面说了,这个程序跑了 61 个小时了,给大家看一下这个时间段里面堆内存的使用情况:
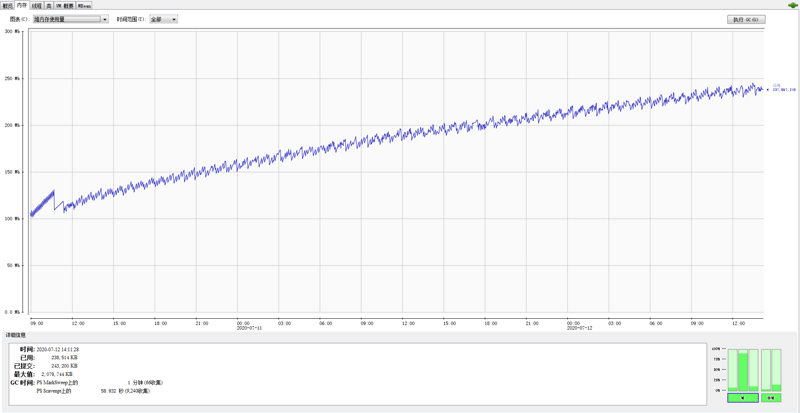
可以看到整个堆内存的使用量是一个明显的、缓慢的上升趋势。
上面这个图就是来自 jconsole。
结合程序,通过图片我们可以分析出,这种情况一定是内存泄漏了,这是一个非常经典的内存泄漏的走势。
接下来,我们再看一下 jmc 的监控情况:
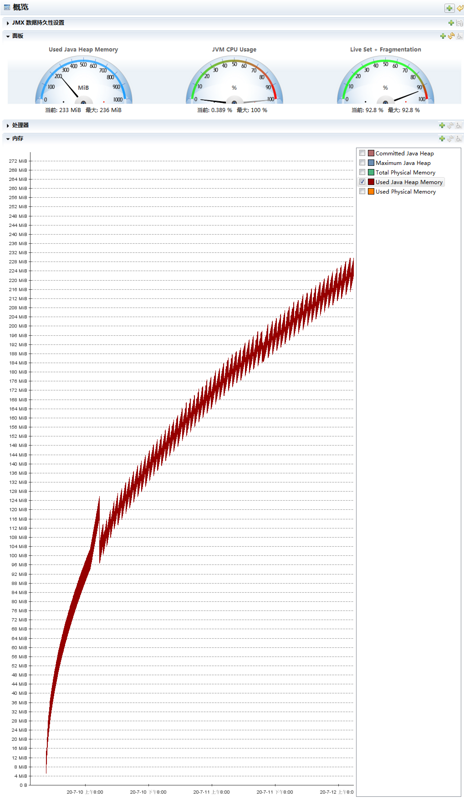
上面展示的是已经使用的堆内存的大小,走势和 jconsole 的走势一样。
然后再看看 VisualVM 的图:
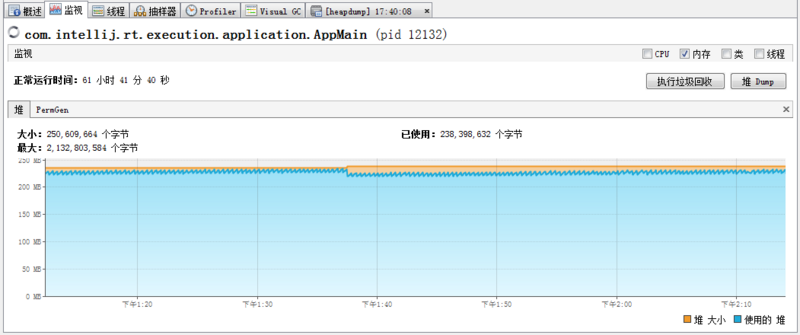
VisualVM 的图,我不知道怎么看整个运行了 60 多小时的走势图,但是从上面的图也是能看出是有上升趋势的。
在 VisualVM 里面,我们可以直接 Dump 堆,然后进行分析:
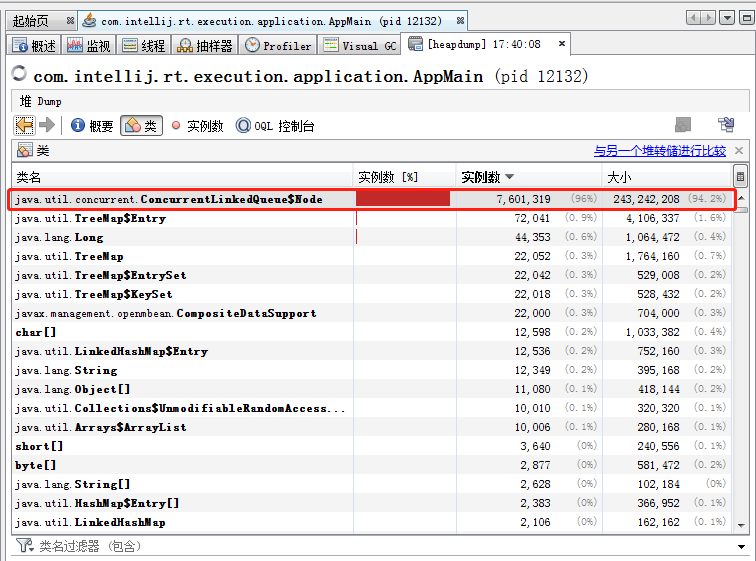
可以清楚的看到, CLQ 的 Node 的大小占据了 94.2%。
但是,从我们的程序来看,我们根本就没有用到这么多 Node。我们只是用了一个而已。
你说,这不是内存泄漏是什么。
内存泄漏最终会导致 OOM。
所以当发生 OOM 的时候,我们需要分析是不是有内存泄漏。也就是看内存里面的对象到底应不应该存活,如果都应该存活那就不是内存泄漏,是内存不足了。需要检查一下 JVM 的参数配置(-Xmx/-Xms),根据机器内存情况,判断是否还能再调大一点。
同时,也需要检查一下代码,是否存在生命周期过程的对象,是否有数据结构使用不合理的地方,尽量减少程序运行期的内存消耗。
我们可以通过把堆内存设置的小一点,来模拟一下内存泄漏导致的 OOM。
还是用之前的测试案例,但是我们指定 -Xmx 为 20m,即最大可用的堆大小为 20m。
然后把代码跑起来,同时通过 VisualVM 、jconsole、jmc 这三个工具监控起来,为了我们有足够的时候准备好检测工具,我在第 8 行加入休眠代码,其他的代码和之前的一样:
加入 -Xmx20m 参数:
运行起来之后,我们同时通过工具来查看内存变化,下面三个图从上到下的工具分别是 VisualVM、jconsole、jmc:
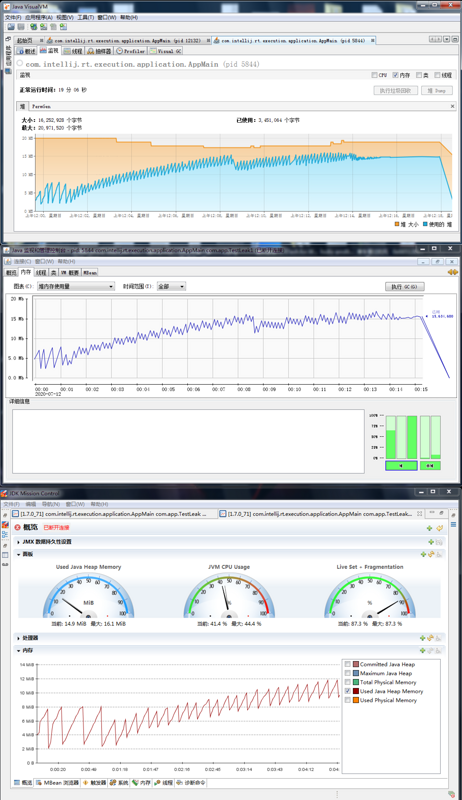
从图片的走势来看,和我们之前分析的是一样的,内存一直在增长。
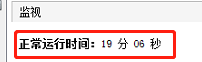
程序运行 19 分 06 秒后,发生 OOM 异常:
那正常的走势图应该是怎么样的呢?
我们在 JDK 1.8.0_121 版本中(已经修复了 remove 方法),用相同的 JVM 参数(-Xmx20m)再跑一下:
首先从上面的日志中可以看出,时间间隔并没有递增,程序运行的非常的快。
然后用 VisualVM 检测内存,同样跑 19 分钟后截图如下:
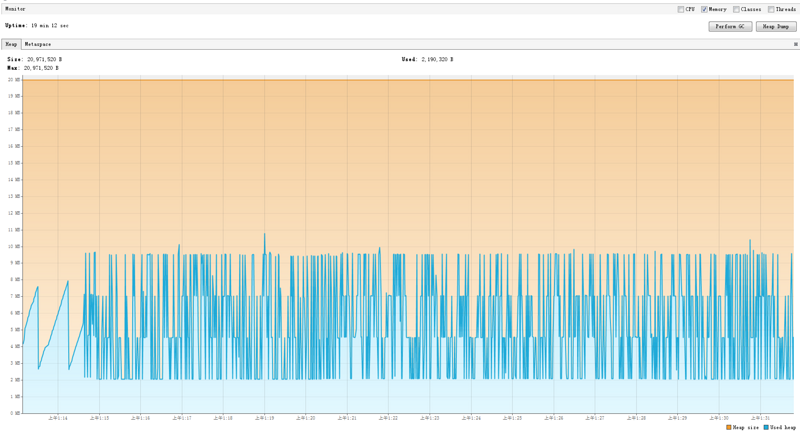
可以看到堆内存的使用量并没有随着时间的推移而越来越高。但是还是有非常频繁的 GC 操作。
这个不难理解,因为 CLQ 的数据结构用的是链表。而链表又是由不同的 node 节点组成。
由于调用 remove 方法后,node 节点具备被回收的条件,所以频繁的调用 remove 方法对节点进行删除,会触发 JVM 的 min GC。
这种 JDK BUG 导致的内存泄漏其实挺让人崩溃的。首先你第一次感知到它是因为程序发生了 OOM。
也许你会先无脑的加大堆内存空间,恰好你的程序运行了一周之后又要上线了,所以涉及到重启应用。
然后很长一段时间内没有发生 OOM 了。你就想这个问题可能解决了。
但是它还是在继续发生着,很可能由于节假日前后不能上线,比如国庆七天,加上前后几天,大概有半个月的样子应用没有上线,所以没有重启,程序越来越慢,最终导致第二次 OOM 的出现。
这个时候,你觉得可能不是内存溢出这么简单了。
会不会是内存泄漏了?
然后你再次重启。这次重启之后,你开始时不时的 Dump 一下内存,拿出来分析分析。
突然发现,这个 node 怎么这么多呢?
最终,找到这个问题的原因。
原来是 JDK 的 BUG。
你就会发出和 Greg 一样的感叹:卧槽,震惊,这么牛皮!?

我这个运行了 60 多小时的程序到现在堆内存使用了 233m,但是我整个堆的大小是接近 2G。
通过 jmc 同时展示堆的整体大小和已经使用的堆大小你可以发现,距离内存泄漏可以说是道阻且长了:
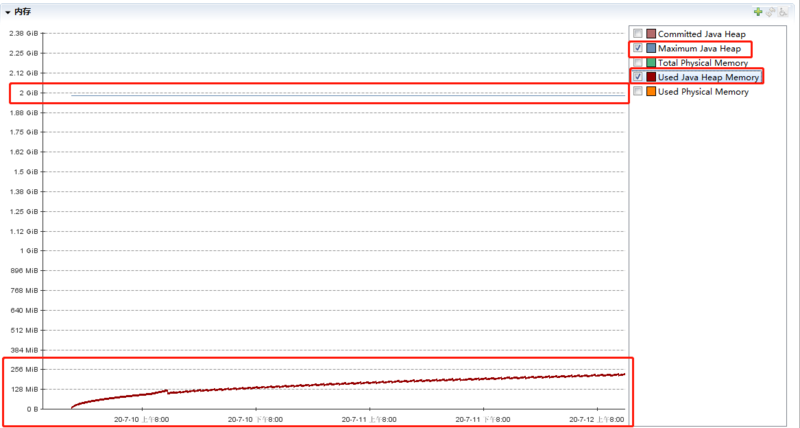
我粗略的算了一下,这个程序大概还得运行 475 个小时左右,也就是 19 天之后才会出现由于内存泄漏,导致的 OOM。
我会尽量跑下去,但是听到我电脑嗡嗡嗡的风扇声,我不知道它还能不能顶得住。

如果它顶住了,我在后面的文章里面通知大家。
好了,图形化工具这一小节就到这里了。
我们只是展示了它们非常小的一个功能,合理的使用它们常常能达到事半功倍的作用。
如果你不太了解它们的功能,建议你看看《深入理解JVM虚拟机(第3版)》,里面有一章节专门讲这几个工具的。

最后说一句(求关注)
这是我昨天晚上写文章的时候拍的 ,女朋友说一眼望去感觉我是一个盯盘的人,在看股票走势图,这只股票太牛逼了。
要是股市的总体走势也像内存泄露那么单纯而直接就好了。
只要在 OOM 之前落袋为安就行。可惜有的人就是在 OOM 的前一刻满仓杀入,真是个悲伤的故事。
文中提到的两本书,都是非常优秀的值得学习的书籍。作为一个 Java 程序员,如果你还没有拥有这两本书,我强烈建议你买来看看。
买不了吃亏,买不了上当,只会觉得相见恨晚。你会发现原来这么多 JVM、多线程相关的面试题都是出自这两本书:
才疏学浅,难免会有纰漏,如果你发现了错误的地方,还请你留言指出来,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。
我是 why,一个被代码耽误的文学创作者,不是大佬,但是喜欢分享,是一个又暖又有料的四川好男人。
以上是 我的程序跑了60多小时,就是为了让你看一眼JDK的BUG导致的内存泄漏。 的全部内容, 来源链接: utcz.com/a/48720.html