容器附加存储(CAS)是云原生存储
客座文章作者:Evan Powell,CEO @MayaData
或者,云服务怎么会不是云原生的呢?
欧洲KubeCon在很多方面都很伟大。一个惊喜是,因为KubeCon是一个虚拟活动,这导致我与各种存储供应商和项目的对话比之前的KubeCon更多。KubeCon存储的交流频道召集了许多聪明的供应商,他们通常合作,试图为最终用户解决问题;我受到了鼓舞,试着尽我的一份力来跟上。
这就是本文起点,作为容器附加存储(Container Attached Storage,CAS)定义的原始作者,接下来为更广泛的社区创建一个博客是有意义的。
引发这次更新的问题来自一个传统存储供应商的工程师,他问--我稍微引用一下:“如果松散耦合对于云原生架构如此重要,这是否意味着,依赖于一个给定的云本身就不是云原生的?换句话说,云服务本身不是云原生的吗?”我不得不回答--是的--但故事还有更多内容。
回顾--什么是CAS?
容器附加存储是一种模式,它非常符合数据分解的趋势,以及运行小型、松散耦合的工作负载的小型、自治团队。换句话说,我的团队可能需要为我们的微服务使用Postgres,而你的团队可能依赖于Redis和MongoDB。我们的一些用例可能需要性能,一些可能在20分钟内就用完,其他的是写密集型的,其他的是读密集型的等等。在大型组织中,团队依赖的技术,会随着组织规模的增长,和组织越来越信任团队选择他们自己的工具,而变得越来越多。Kubernetes支持这种模式--有时被讨论为数据网格(data mesh)和多语言数据(polyglot data)的兴起--来自ThoughtWorks的Zhamak Dehghani和其他人有相关的讨论。
了解更多关于CAS:
- 早在2018年4月,我在CNCF的网站上创建了CAS一词的博客:
https://www.cncf.io/blog/2018...
- 7月的CNCF网络研讨会,由OpenEBS项目负责人Kiran Mova主持:
https://www.cncf.io/webinars/...
这是来自Kiran社区网络研讨会的一张规范图片,并附有一些解释:
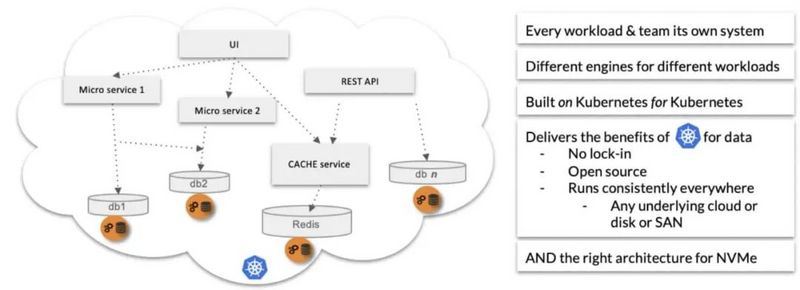
CAS意味着开发者,可以在不考虑其组织存储架构的底层需求的情况下工作。对于CAS,云磁盘与SAN相同,SAN与裸机或虚拟主机相同。我们没有召开会议来选择下一个存储供应商,或讨论设置来支持我们的用例,我们使用我们需要的存储或localPV管理来启动我们自己的CAS容器,然后继续前进。
好的,^^这就是CAS,但是云有什么不是原生云的呢?
Kubernetes的一个被忽视的方面是,它最初创建的目的,是确保我们可以以云原生方式运行云。让我来解释一下。
在Kubernetes之前,很难宣布意图(intent),并知道将要执行此意图,而不论其部署环境是本地部署,还是A、B或C云。相反,企业被建议选择一家主要的云,并且加倍他们与该云的专业知识和关系。
因此,整个组织和他们编写的所有软件都隐式地依赖于该云,因此与云耦合。这种紧密耦合通常并不重要,直到它变得重要为止。只有像Netflix这样的组织,他们的系统架构既能解决AWS的漏洞,又能通过混沌工程积极地、不懈地验证自己的容错性,才能挺过各种各样的AWS宕机。据推测,他们转移至少一部分工作负载的能力,比如基于Spinnaker的CI/CD,也有助于他们与AWS协商更好的价格。
简而言之,如果你将云原生定义为能够在底层云中断时存活,那么与云紧密耦合本身就是一种反模式。
Kubernetes之所以成为我们这个时代最重要的开源项目之一,部分原因在于它意识到了这种紧密耦合的风险和阻抗挑战。而且,对于一个传统的共享一切的存储硬件供应商来说,这里有些敏感,这种逻辑在他们销售的系统上双倍适用。
如果你想构建松散耦合的系统,就像你不能简单地在一个云上,并且只在那个云上运行一样,你也不能假设一个声称可扩展到数千个节点的存储系统在所有情况下都能工作。
如果我们接受云原生核心的“构建失败”信条,我们必须承认共享的所有存储将会崩溃。它的行为方式并不适合每个团队的工作负载。它将以非Kubernetes原生方式运行,所有这些依赖关系将超出我们控制的风险引入到我们的环境中,这对我们的团队来说是不透明的。
好的,那么CAS有什么新东西呢?
当CAS首次出现时,它被用于较少任务关键型工作负载,这并不奇怪。很好的例子包括各种“半永久性”工作负载,其中你希望数据在CI/CD运行期间保留,或者用于一些数据科学工作,然后你希望它消失。对于这些示例,CAS允许工作负载快速且一致地启动非常重要。第二个也是重要的需求是,无论底层环境如何,CAS的行为方式都是相同的。
当Kubernetes调度工作负载时,即使是相当典型的32秒的EBS附加时间,如果运行时间为5分钟,而你每天运行它几十次,则需要不少时间。你可以在早期OpenEBS采纳者列表中看到这种模式,早期的公共引用往往倾向于持续时间相对较短的工作负载。
几年前,Kubernetes上的较长持续时间的工作负载以两种方式之一处理。
- 要么通过云中的托管服务,或
- 增加额外弹性级别的NoSql数据库。
一开始我们认为CAS在这两种情况下都不适用,因为传统的共享存储肯定不适用;然而,我们很快意识到NoSQL数据库和Kafka这样的解决方案,可以在我们称为动态LocalPV的地方得到帮助。
通过保持对底层环境(包括可用的云卷和物理磁盘)的了解,像OpenEBS的LocalPV这样的CAS解决方案,降低了在Kubernetes上运行这些工作负载的操作工作量。CAS解决方案这样做的方式,减少了对给定底层云或存储系统的锁定或依赖。
第一个新的CAS要求
因此,我们可以相应地更新CAS定义。我们现在知道CAS解决方案需要包括LocalPV支持。同样,帮助使用LocalPV运行数据应用程序的相关Kubernetes操作器也是如此。
最近,我们看到许多工作负载都在增加,对于这些工作负载,本地节点性能非常重要。
性能问题同样可以通过使用LocalPV来解决。一个挑战是,许多工作负载现在既需要性能又需要多节点HA。仅仅通过Restic或其他项目或产品备份节点是不够的。
考虑运行在PostgreSQL或MySql上的高性能工作负载--例如运行在MySql上的Magento。仅仅备份数据是不够的,MySql通常希望能够立即访问另一个节点上的数据。也许不足为奇的是,许多这些工作负载在云出现之前就存在了。传统的SQL,如MySql、PostgreSQL和其他SQL,几乎总是部署故障转移和副本。有时,这些传统的工作负载甚至可以通过Kafka或类似的方式整合在一起,以交付一个统一的数据网格,就像前面ThoughtWorks的文章中提到的那样。我们的梦想是为企业提供关注点,比如从所有数据中学习,同时也允许小型独立团队的自治和敏捷性。
第二个新的CAS要求
因此,我们可以用第二种方式更新CAS定义。我们现在知道CAS解决方案需要以LocalPV速度包含多节点HA。
这个需求的唯一问题是,到目前为止,能够满足这个需求的解决方案非常少。据我所知,致力于满足这一需求的唯一CAS解决方案是OpenEBS Mayastor;它将在2020年9月达到测试版0.4。
第三和第四项附加的CAS要求
第三个更新在这两个更新之后的逻辑上进行。CAS解决方案在其架构中应该是云原生的。如果我们想成功地支持所有类型的工作负载,比如NoSql工作负载的LocalPV,以及对许多性能敏感的PostgreSQL等部署具有弹性的高性能,那么CAS必须提供多种存储数据的方法。
在OpenEBS的情况,该项目利用云原生架构提供了不少于4个“数据引擎”(如果计算可用的所有不同风格的LocalPV,会更多)。早期的CAS解决方案在本质上更加单一。我认为所有的CAS都需要以Kubernetes作为基底的思想来构建,从而实现可插拔的非单体架构。
最后,开源似乎是明显的。理性的人可能不同意这一点,因为有一些明显的CAS模式的早期贡献者依赖于专有软件。但是,专有软件引入了供应商依赖,这与云原生固有的“可移植性”精神相冲突。
综上所述,从成千上万的容器附加存储用户那里,我们可以自信地说,CAS的定义应该扩展到包括:
- CAS必须支持pass-through模式(我们在Kubernetes生态系统中称之为LocalPV)
- CAS必须支持LocalPV速度的多节点HA
- CAS软件在架构上应该是云原生的--根据工作负载支持多个数据引擎
- CAS应该是开源的,以避免引入供应商依赖关系。
总结
在过去的几年里,我们看到了来自更广泛的云原生社区的大量反馈和支持,这些社区致力于如何在处理数据时最大限度地利用Kubernetes和云原生方法。我们必须付出才能得到。而且,我比以往任何时候都高兴,因为MayaData将OpenEBS捐赠给了CNCF。我们很自然地将Litmus也捐赠给了关注有状态工作负载的混沌工程。我们非常自豪的是,根据这篇来自CNCF的DevStats报告,截止到2020年8月底,MayaData是CNCF项目的第5大主要贡献者:
https://all.devstats.cncf.io/...
最近,我们帮助启动了Data on Kubernetes社区项目,在这供应商中立空间中讨论操作人员、数据库、用例等等。来自使用Kubernetes组织的工程师像Optoro和Arista等,以及Kafka/Confluent和Cassandra/DataStax等项目进行了发言。欢迎并鼓励所有人与独立组织者取得联系,以任何你想要的方式参与。
CAS现在被看作是把Kubernetes转换成数据平面的关键部分。CAS补充了底层云存储服务、本地CSI可访问存储,甚至是本地节点中可用的原始磁盘和内存。
我们使用CAS(特别是OpenEBS)的经验表明,用户已经熟悉了这种模式。CAS的新需求反映了这模型的增长和成熟度。
我对未来几年我们将走向何方感到兴奋。当我们在Kubernetes上探索更多数据密集型的工作负载时,我们的需求将如何发展?不管是什么,我们都渴望和你一起找出答案。我们在MayaData这里倾听,并继续发展CAS模式以满足新的需求。
点击阅读网站原文。
CNCF (Cloud Native Computing Foundation)成立于2015年12月,隶属于Linux Foundation,是非营利性组织。
CNCF(云原生计算基金会)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。扫描二维码关注CNCF微信公众号。
以上是 容器附加存储(CAS)是云原生存储 的全部内容, 来源链接: utcz.com/a/46414.html