0k05 Nagios Host Check
Nagios Host Check
Nagios Host Check
- 什么时候执行Check
- 缓存host checks
- Dependencies and checks
- 主机的并发checks
- 主机的状态
- 主机状态变化
Predictive Host Dependecy Check
- 预测性检测工作原理
本篇主要讲述主机监控的工作原理
什么时候执行Check
Check的调度配置是通过Nagios Core Deamon控制
- 定期性检测,由主机定义中的check_interval和retry_interval选项
- 按需,当一个与主机关联的服务状态发生变化时
- 按需,作为主机可达逻辑的一部分,会进行check触发
- 按需,作为predictive dependency checks的一部分,会触发check.
定期性检查:如果设置check_interval is zero 那么就不会进行定期检查。
关联服务触发的检查:该检查被触发,当一个主机关联的服务改变了状态,因为Nagios Core 需要知道是否主机已经在服务状态改变之前已经改变了状态。这个很好理解,因为通常一个服务状态发生了变化,我们很大基础上会去想知道,承载服务的基础,host是否状态已经发生变化。
作为主机可到逻辑的一部分所触发的主机检查:Nagios Core被设计用于尽可能快的发现网络断电,区分Down和Unreachable两种状态。这是非常不同的两种状态,可以帮助管理员快速定位造成网络断电的位置。这是一种parent/child关系,我们要保证这种逻辑链的健康,比如说网络ip可达,来检测这种链路是健康的。不过一旦不可达了,那么就需要快速定位是链路中哪个或者哪些节点出了问题。通常我们会从哪里开始入手呢?这就是从nagios作为网络的根节点,然后依次是nagios通过网络设备达到各个host,当然网路设备也是host。如下图,可以从nagios为root来构建的一个树结构:
当其中一个或者几个主机状态发生变化,那么逻辑可达中的所有主机将进行一个并发的check,当收到每个节点的check结果后,nagios会判定这个节点的check路径上的上峰节点的check状态是否有不正常的,如果有,那么该节点状态为Unreachable而不是down,如果上峰节点都是正常的,那么该节点状态就是Down,因为上峰不可达后,那么依赖上峰的当前节点状态是未知的,上峰节点阻塞了检查,那么就该判定为Unreachable。
当然对于down和unreachable状态监控还是都会通知到相关contact的。然后admin会根据网络拓扑图,从nagios角度出发,来发现down的设备。
作为predictive host dependecy check 逻辑的一部分被触发:
可预测的依赖检查,单独放在后面的Predictive Host Dependecy Check讲。
缓存host checks
通过实现缓存检查的使用,可以显着提高按需主机检查的性能,这使Nagios Core可以在确定相对较新的检查结果的情况下放弃执行主机检查。有关缓存检查的更多信息,请参见此处。
也就是说,常规计划性的检查结果缓存下来,可用于突发的按需检查,避免了多次价差请求,已提高性能。
Dependencies and checks
您可以定义主机执行依赖性,以防止Nagios Core根据一个或多个其他主机的状态来发起一个检查当前主机的状态。这个属于高阶知识点,有关依赖关系的更多信息,请参见此处。
主机的并发checks
计划的主机检查是并行运行的。当Nagios Core需要运行计划的主机检查时,它将启动主机检查,然后返回执行其他工作(运行服务检查等)。主机检查在从主要Nagios Core守护程序进行fork()处理的子进程中运行。主机检查完成后,子进程将把检查结果通知主Nagios Core进程(其父进程)。然后,主要的Nagios Core流程将处理检查结果并采取适当的措施(运行事件处理程序,发送通知等)。
如果需要,还可以并行运行按需主机检查。如前所述,Nagios Core如果可以使用相对较新的主机检查中的缓存结果,则可以放弃按需主机检查的实际执行。
当Nagios Core处理计划的和按需的主机检查结果时,它可能会启动(辅助)其他主机的检查。可以出于两个原因启动这些检查:预测依赖性检查和使用网络可达性逻辑确定主机的状态。启动的辅助检查通常并行运行。但是,您应该意识到一个大例外,因为它可能会对性能产生负面影响...
将max_check_attempts值设置为1的主机可能会导致严重的性能问题。原因?如果Nagios Core需要使用网络可达性逻辑来确定其真实状态(以查看它们是DOWN还是UNREACHABLE),则它将必须启动对主机的所有直接父级的串行检查。重申一下,这些检查是串行运行的,而不是并行运行的,因此可能会严重影响性能。因此,我建议您始终在主机定义中为max_check_attempts指令使用大于1的值。
主机的状态
- UP
- DOWN
- UNREACHABLE
主机状态变化
如您所知,主机并非总是保持一种状态。 事情中断了,补丁被应用了,服务器需要重启。 当Nagios Core检查主机状态时,它将能够检测到主机何时在UP,DOWN和UNREACHABLE状态之间切换,并采取适当的措施。 这些状态更改导致不同的状态类型(HARD或SOFT),这可以触发事件处理程序的运行和通知的发送。 检测并处理状态更改是Nagios Core的全部目的。
当主机更改状态的频率太高时,它们被视为“拍动”。 主机波动的一个很好的例子是服务器,一旦操作系统加载,该服务器就会自发重启。 这总是很有趣的情况。 Nagios可以检测主机何时开始震荡,并且可以抑制通知,直到震荡停止并且主机的状态稳定为止。 可以在此处找到有关襟翼检测逻辑的更多信息。
Predictive Host Dependecy Check
预测依赖性检测
主机和服务的依赖可以被定义来允许你更好的控制,什么时候checks被执行和什么时候通知被发送。由于依赖关系用于控制监视过程的基本方面,因此至关重要的是,确保依赖关系逻辑中使用的状态信息尽可能最新。
Nagios Core 允许你进行预测性的依赖检测,针对hosts和service用于去确定依赖逻辑有最新新的状态信息,当我们需要这些信息去确定是否发送通知或允许触发一次主机或服务检测。
预测性检测工作原理
白话说就是,当检测到一个主机或者服务有问题时。会去预测性的发出它说依赖的依赖服务主机和有直接网络逻辑的父和子的进行一次check。
下图显示了Nagios Core监视的主机的基本示意图,以及它们的父/子关系和依赖关系。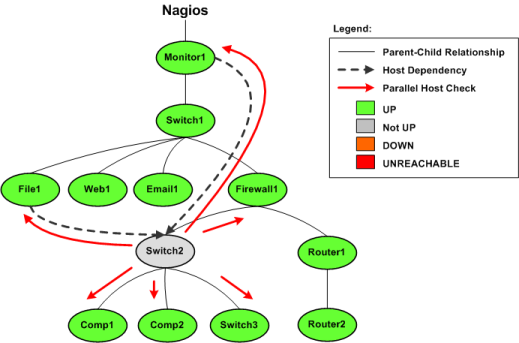
在此示例中,Switch2主机刚刚将状态从UP状态更改为问题状态。 Nagios Core需要确定主机是DOWN还是UNREACHABLE,因此它将启动对Switch2的直接父代(Firewall1)和子代(Comp1,Comp2和Switch3)的并行检查。这是主机可达性逻辑的正常功能。
您还将注意到,Switch2依赖于Monitor1和File1来进行通知或检查执行(在此示例中,哪个不重要)。如果启用了预测性主机依赖性检查,则Nagios Core将同时启动Monitor1和File1的并行检查,并启动Switch2的直系父母和孩子的检查。 Nagios Core之所以这样做是因为它知道在不久的将来(例如出于通知目的)必须测试依赖关系逻辑,并且它想确保它具有参与依赖关系的主机的最新状态信息。
以上是 0k05 Nagios Host Check 的全部内容, 来源链接: utcz.com/a/46388.html