三、Apache Dubbo学习整理---扩展点加载机制(1)
这篇比较枯燥,先记录下来。等着理解更深后,会使用通俗易懂的语言进行描述。一、背景描述
dubbo是一个扩展性特别强的框架,基于JAVA的SPI思路改良后的Dubbo SPI,使接口和实现完全解耦。提供注册中心,通信协议,序列化等的扩展方式。而且自身在设计过程中针对不同的场景选择合理的设计模式。
二、Dubbo SPI描述
1、JAVA SPI
使用策略模式。只声明接口,具体的实现不在程序中直接确定,而且通过程序外的配置,用于具体实现的装配。
①定义一个接口以及方法。
②编写接口的实现类。
③创建
//定义SPI接口public interface HelloService {
void sayHello();
}
//定义实现类
public class ChineseHello implements HelloService {
@Override
public void sayHello() {
System.out.println("你好!!!");
}
}
//使用ServiceLoader加载接口的所有实现类
public static void main(String[] args) {
ServiceLoader<HelloService> helloServices = ServiceLoader.load(HelloService.class);
for (HelloService helloService: helloServices){
helloService.sayHello();
}
}
//输出你好!!!!
2、Dubbo SPI
官方文档的解释:
1、JDK标准的SPI会一次性实例化扩展点所有实现,如果有扩展则初始化很耗时,如果没用上也加载,则浪费资源。
2、如果扩展加载失败,则连扩展的名称都获取不到了。如果JDK标准的ScriptEngine,通过getName()获取脚本类型的名称,如果RubyScriptEngine因为所引来的jruby.jar不存在,导致RubyScriptEngine类加载失败,这个失败原因被“吃掉”了,和Ruby对应不起来,当用户执行Ruby脚本时,会报不支持Ruby,而不是真正失败的原因。
3、增加了对扩展IOC和APO的支持,一个扩展可以直接setter注入其他扩展。在Java SPI中已经看到,java.util.ServiceLoader会一次把PrintService接口下的所有实现类全部初始化,用户直接调用接口。Dubbo SPI只是加载配置文件中的类,并分成不同的种类缓存在内存中,而不全立即全部初始化,在性能上有更好的表现。
//在目录META-INF/dubbo/internal下建立HelloService的默认实现类impl=com.test.spi.ChineseHello
//定义SPI接口
public interface HelloService {
void sayHello();
}
//定义实现类
public class ChineseHello implements HelloService {
@Override
public void sayHello() {
System.out.println("你好!!!");
}
}
//调用Dubbo SPI加载配置文件的信息,并且加载默认实现类
public class SayHelloMain {
public static void main(String[] args) {
HelloService helloService = ExtensionLoader.getExtensionLoader(HelloService.class)
.getDefaultExtension();
helloService.sayHello();
}
}
//输出你好!!!!
JAVA SPI加载失败,可能会因为各种原因导致异常信息被“吞掉”,导致问题追踪比较困难。Dubbo SPI在扩展加载失败会先抛出真实异常并打印日志。扩展点在被动加载的时候,即使有部分失败,也不会影响其他扩展点和整个框架的使用。
- ①Dubbo SPI自己实现了IOC和AOP机制。
- ②一个扩展点可以通过setter方法直接注入其他扩展的方法。T injectExtension(T instace)方法实现了这个功能。
- ③Dubbo支持包装扩展类,推荐把通用的抽象逻辑放在包装类中,用于实现扩展点的AOP特性。
3、扩展点的配置规范
Dubbo SPI和JAVA SPI类似,需要在META-INF/dubbo/下放置对应的SPI配置文件,文件名称需要命名为接口的全路径名。
配置文件的呢日用为key=扩展点实现类全路径名,有多个用换行符分割。
key为Dubbo SPI注解中的传入参数。
兼容JAVA SPI的配置路径和内容配置方式。在Dubbo启动时,会默认扫META-INF/services/、META-INF/dubbo/、META-INF/dubbo/internal/三个文件。
4、扩展点的分类与缓存
分为Class缓存、实例缓存。这两种缓存又能根据扩展类的种类分为普通扩展类,包装扩展类(Wrapper)和自适应扩展类(Adaptive)等。
Class缓存:Dubbo SPI获取扩展类时,会先从缓存中读取。如果缓存中不存在,则加载配置文件,根据配置把Class缓存在内存中,并不会直接全部初始化。
实例缓存:基于性能考虑,Dubbo框架不仅缓存Class,也会缓存Class实例化后的对象。每次获取的时候,会先从缓存中读取,如果缓存中读不到,则重新加载并缓存起来。因为缓存的Class并不会全部实例化,而是根据需求实例化并缓存,因此性能更好。
普通扩展类:
最基础的,配置在SPI配置文件中的扩展类实现。
包装扩展类:
Wrapper类没有具体的实现,只是做了通用逻辑的抽象,并且需要在构造方法中传入一个具体的扩展接口的实现。属于Dubbo的自动包装特性。
自适应扩展类:
一个扩展接口会有多种实现类,具体使用哪个可以不写死在配种或者代码中,在运行时,通过传入URL中的某些参数动态来确定。属于扩展点的自适应特性。
其他缓存:
如扩展类加载器缓存、扩展名缓存等。
5、扩展点的特性
自动包装、自动加载、自适应和自动激活。
①自动包装:
自动包装是上面提到的包装扩展类,ExtensionLoader在加载扩展时,如果发现这个扩展类包含其他扩展点作为构造函数的参数,则这个扩展类就会被认为是Wrapper类。
public class ProteocolFilterWrapper implements Protocol{
private final Protocol protocol;
//实现了Protocol,但在构造函数中又传入了一个Protocol类型的参数,框架会自动注入
public ProteocolFilterWrapper (Protocol protocol){
if(protocol == null){
throw new IllegalArgumentException("protocol == null");
}
this.protocol = protocol
}
}
ProteocolFilterWrapper 实现了Protocol接口,但是构造函数中又传入了Protocol类型的参数。因此ProteocolFilterWrapper会被认定为Wrapper类。这是一种装饰器模式,把通用的抽象逻辑封装或者对子类进行增强,让子类可以更加专注具体的实现。
②自动加载:
除了在构造函数中传入其他扩展实例,我们还经常使用setter方法设置属性值。如果某个扩展类是另外一个扩展点类的成员属性,并且拥有setter方法,那么框架也会自动注入对应的扩展点实例。ExtensionLoader在执行扩展点出初始化的时候,会自动通过setter方法注入对应的实现类。如果扩展类属性是一个接口,有多种实现,那么具体注入哪一个呢?涉及第三特性---自适应。
③自适应:
在Dubbo SPI中,我们使用@Adaptive注解,可以动态通过URL中的参数来确定要使用哪个具体的实现类。从而解决自动加载中的实例注入问题。
@SPI("netty")
public interface Transporter{
@Adaptive({Constants.SERVER_KEY,Constants.TRANSPORTER_KEY}})
Server bind(URL url,ChannelHandler handler);
@Adaptive({Constants.CLIENT_KEY,Constants.TRANSPORTER_KEY}})
Client connect(URL url,ChannelHandler handler);
}
@Adaptive传入两个参数,外部调用Transporter#bin方法的时候,会动态从传入参数“URL”中提取key参数“server”的value值,如果能匹配上某个扩展实现类则直接使用对应的实现类;如果未匹配上,则继续通过第二个key。如果都没匹配上,则抛出异常。也就是说@Adaptive传入多个参数,依次进行实现类的匹配,直到最后抛出异常。
如果一个类的多个实现类都要加载怎么办?涉及最后一个特性---自动激活。
④自动激活:
使用@Activate注解,可以标记对应的扩展点默认被激活启用。该注解还可以通过传入不同的参数,设置扩展点在不同的条件下被自动激活。主要的使用场景是某个扩展点的多个实现类需要同时启动(如Filter扩展点)
二、扩展点注解
1、扩展点注解:@SPI
可以作用在类,接口和枚举上,Dubbo框架都使用在接口上。作用为标记这个接口是Dubbo SPI接,即是一个扩展点,可以有多个不同的实现。运行时需要通过配置找到具体的实现类。
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
String value() default "";
}
SPI有个value属性,通过这个属性,可以传入不同的参数来设置这个接口的默认实现类。
例如Protocol的默认为dubbo。
@SPI("dubbo")public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> var1) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> var1, URL var2) throws RpcException;
void destroy();
}
Dubbo中很多地方通过getExtension(Class type,String name)来获取扩展点接口的具体实现。此时会对class做校验,判断是否是接口,以及是否有@SPI注解,两者缺一不可。
2、扩展点自适应注解:@Adaptive
@Adaptive注解可以表示在类,接口,枚举和方法上,但是在整个Dubbo框架中,只有几个地方使用到了类级别上。其他都标注在方法上。如果标注在方法上,为方法级别注解,则可以通过参数动态获取实现类,这一点在自适应特性中已经说明。方法级别注解,在第一次getExtension时,会自动生成和编译一个动态的Adaptive类,从而达到动态实现类的效果。
例如:Protocol接口在export和refer两个接口上添加了@Adaptive注解。Dubbo在初始化扩展点时,会生成Protocol$Adaptive类,里面会实现两个方法,方法里会有一些抽象的通用逻辑,通过@Adaptive中传入的参数,找到并调用真正的实现类。和装饰器模式比较类似。
@Adaptive注解的代码@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Adaptive {
String[] value() default {};
}
该注解也可以传入value值,并且是一个数组。
- 1、在初始化Adaptive注解的接口时,会对先传入的URL进行key值匹配,
- 2、第一个key没匹配上继续匹配后续的key,直到所有的key匹配完毕,
- 3、如果还没有匹配到,则会使用“驼峰规则”匹配,
- 4、如果还没匹配到,则抛出IllegalStateException异常。
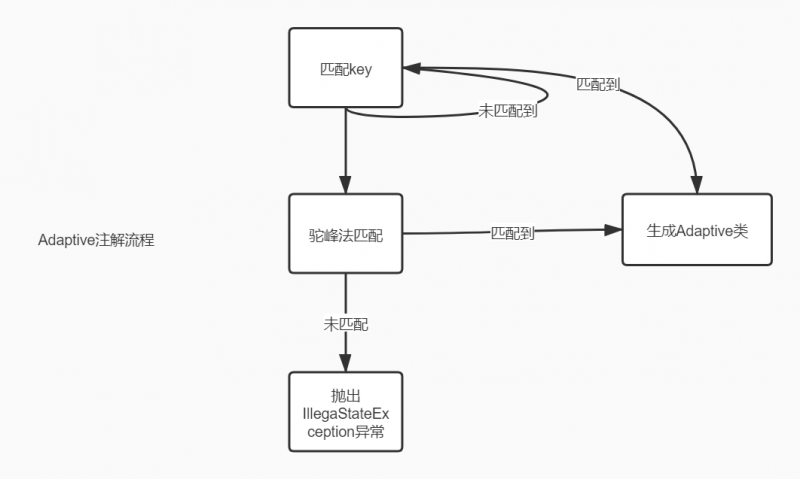
驼峰规则:
如果包装类(wrapper)没有用Adaptive匹配到key值,则Dubbo会自动把接口名称根据驼峰大小写分开,并且用“.”符号连接起来,以此来作为默认实现类的名称,如org.apache.dubbo.xxx.HelloInovkerWrapper中HelloInvokerWrapper会被转移为hello.invoker.wrapper。
为什么有些实现类会标注@Adaptive注解?
- 1、放在实现类上,主要是为了直接固定对应的实现而不需要动态生成代码实现,就像策略模式直接确定实现类。
- 2、在代码中的实现方式是:ExtensionLoader中会缓存两个与@Adaptive有关的对象,一个缓存在cachedAdaptiveClass中,即Adaptive具体的实现类的Class类型;
- 3、另一个缓存在cachedAdaptiveInstance中,Class的具体实例化对象。
- 4、在扩展点初始化时,如果发现实现类中有@Adaptive注解,则直接赋值给cachedAdaptiveClass,后续实例化类的时候,就不会在动态生成代码,直接实例化cachedAdaptiveClass,并把实力缓存到cachedAdaptiveInstance中。
- 5、 如果注解在接口方法上,会根据参数,动态获得扩展点的实现,会生成Adaptive类,在缓存到cachedAdaptiveInstance中。
public class ExtensionLoader<T> {//实现类类型cachedAdaptiveClass
private volatile Class<?> cachedAdaptiveClass = null;
private final ConcurrentMap<String, Holder<Object>> cachedInstances = new ConcurrentHashMap();
private String cachedDefaultName;
//实例化对象cachedAdaptiveInstance
private final Holder<Object> cachedAdaptiveInstance = new Holder();
3、扩展点自动激活注解:@Activate
@Activate可以标识在类、接口、枚举类和方法上。主要使用在多个扩展点实现、需要根据不同条件被激活的场景上。如Filter需要多个同时激活,因为每个Filter的实现是不同的功能。
@Documented@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Activate {
//URL中的分组如果匹配则激活,可以设置多个
String[] group() default {};
//查找URL中如果含有该key值,则激活
String[] value() default {};
//标识哪些扩展点要在本扩展点之前
String[] before() default {};
//标识哪些扩展点要在本扩展点之前
String[] after() default {};
//排序信息
int order() default 0;
}
以上是 三、Apache Dubbo学习整理---扩展点加载机制(1) 的全部内容, 来源链接: utcz.com/a/34203.html