《隐秘的角落》20万条弹幕的爬取与分析
一部火爆的电视剧 + 最近复习的Pandas => 想爬取弹幕来分析观众对电视剧的看法
提出疑问
- 弹幕数据哪里来的?怎么下载的?
- 高赞的弹幕一般都是些什么内容?弹幕中使用emoji的情况如何?
- 演员的关注度?观众讨论较多的演员是谁呢?
- 随着集数增加,观众的情绪是怎样的?
- 有没有水军?有多少人发弹幕啊?
- 电视剧是哪天开始爆火的?能否从弹幕数据中看出来?
- 是否能较模糊地推断出深度使用和轻度使用爱奇艺看这部剧用户的占比?能否简单推断二刷的人数?
爬取数据
- 编程语言:Python
- 使用的库:
bs4 zlib lxml csv后续用到的库re snownlp wordcloud jieba PIL matplotlib emoji - 分析网页:异步加载弹幕 分析弹幕URL地址格式(包含12个tvid+1个albumid) 文件格式(.z压缩包)
https://cmts.iqiyi.com/bullet/{}/{}/{}_300_{}.z - 执行爬取:
open('xxx.xml','w',encoding='utf-8').write(zlib.decompress(bytearray(requests.get(myUrl).content), 15+32).decode('utf-8')) - 得到数据:203667条弹幕 xml数据文件143M csv清洗后的数据 30M
细节此处不展开来讨论
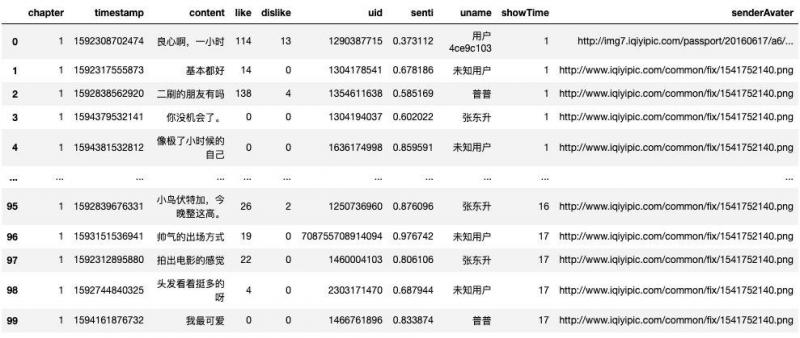
最后读取CSV文件pd.read_csv('data2/iqiyi_dark_2.csv',encoding='utf-8').head(100)得如下数据
有没有水军?有多少人发弹幕啊?
df['uid'].unique().shape
对用户ID去重计数,结果发现有120692 个用户发弹幕,平均每个用户都会发 203667/120692 ≈ 1.6875 条
哪些用户发弹幕较多呢?
# 对用户ID分个组,计算一下每个ID的弹幕数量,再加个排序uid_send_counts = df.groupby('uid')['timestamp'].count().sort_values(ascending = False).reset_index()
# 加个标题
uid_send_counts.columns = ['UID','COUNT']
# 看看前面一百行
uid_send_counts.head(100)

结果发现181*** 的这个用户发了1820条弹幕,难以置信他平均一集发了1820/12≈152条...他好忙啊?
这个181***的用户都发了些什么弹幕?
# 根据点赞的数量排个序看看u_181035 = df[df['uid'] == 181*** ].sort_values(by="like",ascending = False)
u_181035[['chapter','content','like','dislike','senti','showTime','uname','senderAvater']]
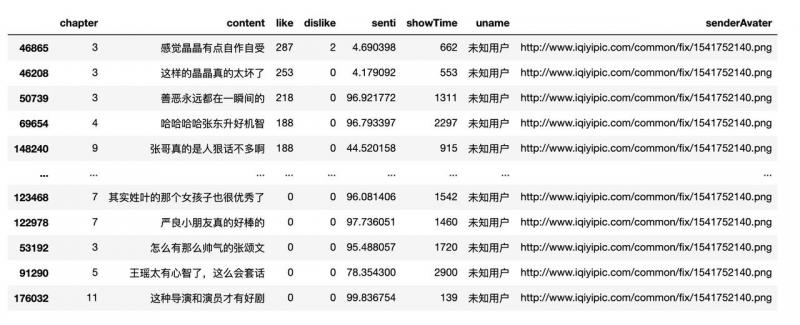
粗略一看用户名和头像都是默认的,不像是重度使用爱奇艺的用户,弹幕的内容也并无异常。
这个181***的用户是水军吗?他每一集都在发弹幕?
# 对集分组,计数,画图u_181035.groupby('chapter')['timestamp'].count().plot(grid=True)
由上图可得他真的每一集都在发,前两集都发了300条左右,只是越发越少,而到了第12集几乎没发几条
这个181***的用户每时每刻都在发弹幕?
# 画直方图for i in range(12):
u_ch = u_181035[u_181035['chapter']==(i+1)]
# 弹幕发送的时间位置归一化
u_ch['showTime'] = (u_ch['showTime'] - u_ch['showTime'].min()) / (u_ch['showTime'].max() - u_ch['showTime'].min())
u_ch['showTime'].plot(bins=10,legend=True,kind='hist',label='Chapter {}'.format(i+1))
12集放在一个图显得杂乱,便取前3集观察
显然,每一集的各个时段,都有他发弹幕的身影...确实真的很忙啊?
这个181***的用户一共发了多少个字(算上了标点符号)?
u_181035['content'].str.len().sum()
结果字数:21072 ,每一条弹幕平均要发 21072 / 1820 ≈ 11.57 字
好奇的我查了一下普通人打字的平均速度如下:
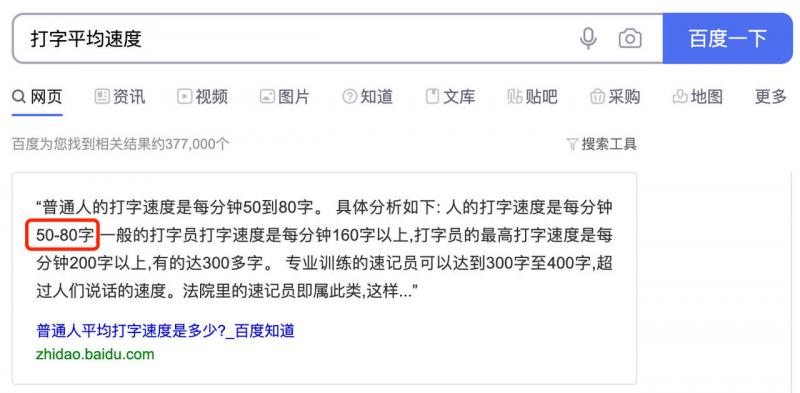
我按普通人的打字速度80字来算,21072 / 80 ≈ 263.4 min ≈ 4.39 h
那么可以判断..这个人居然在打字上面花了4个小时????Unbelievable..
高赞的弹幕一般是什么内容?
先来看看高赞弹幕
df.sort_values(by='like',ascending=False)[['content','like']].head(20)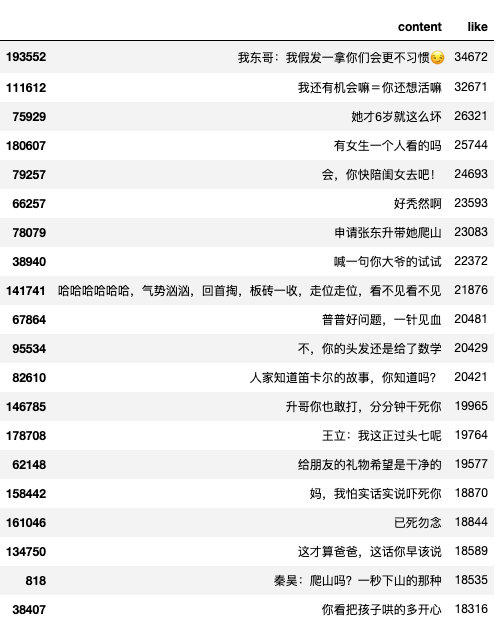
从高赞的这几条弹幕看到...果然张东升的秃头和那句“我还有机会吗”是观众关注的焦点
第四条高赞的是“有女生一个人看的吗”...感觉至少有25744的活跃女用户是自己一个人看的
相反,看看踩的最多的弹幕又是些什么?
df.sort_values(by='dislike',ascending=False)[['content','dislike']].head(20)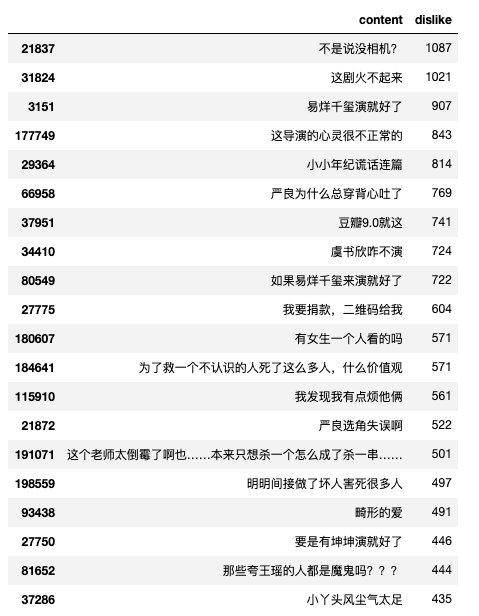
- 出现了好几个弹幕都是在说选角问题,存在偏见的弹幕貌似并不受大众的欢迎。
有点赞的弹幕数和点了踩的弹幕数?
df[df['like'] > 0],df[df['dislike'] > 0]
- 点赞的:
168366占比168366 / 203667 ≈ 82.67% - 点踩的:
37330占比37330 / 203667 ≈ 18.32% - 可见八成以上的弹幕都是有被点赞的
注意到有些人发弹幕里面含有emoji,看看其中发的最多的emoji有哪些?
import reimport emoji
defget_emoji(content):
for x in content:
if x in emoji.EMOJI_UNICODE.values():
return x
return''
df_em = df['content'].apply(get_emoji)
df_em.value_counts().to_dict()
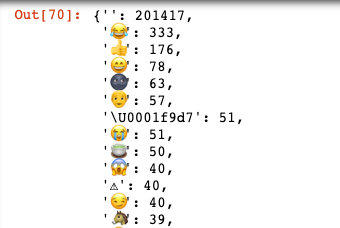
选了前面几个,发现最多的竟然是😂 其次是👍,果然该剧是值得认可的
那么弹幕的赞和踩是否和弹幕的情绪值相关?
尝试画两个散点图,并没有看出有何联系
df.plot(kind='scatter',x='dislike',y='senti',grid=True)df.plot(kind='scatter',x='like',y='senti',grid=True)
观众的情绪是怎样的?
情绪的打分这里使用了snownlp的库,分数在0-1之间,为了好看一点..我把分数*100了
df['senti'] = df['senti'] * 100整体的情绪分布如何
df['senti'].hist(density=True,bins=25)如果说[0,33]是消极,[33,66]是中立,[66,100]是积极
那么大部分人的弹幕算是积极的,其次是中立的
那么每一集的情绪(平均)又是如何的呢?
df.groupby('chapter')['senti'].mean().plot(grid=True,label='avg-line')如果中立的区间是[33,66],那么这个图看起来似乎没什么意义,因为都是处于中立状态
但是可以明显看到本剧第一集的态度相对较积极,第11集较差,也许11集的删减么?
但是最后第十二集的平均情绪值又突然上升,可能得益于开放式结尾发人深思?
随着时长的推移,情绪是否有变化?
首先看整体的情绪占的值域
for i in range(12):df_se = df[df['chapter']==(i+1)]
df_se.groupby('showTime')['senti'].mean().plot(grid=True,label='chapter {}'.format(i+1),legend=True)
很杂乱,但是可看出情绪值都在33以上,所以基本上很少有出现消极的(例如骂人的话)出现?
如果横向拼接,如下图所示
虽然还是很杂乱,但是显然从第一集到最后一集,弹幕的情绪,并无太大的变化
下面抽出第11集来观察
若只看0-2500秒这个区间的情绪,波动不是特别的大,但是可以从第1000秒开始,即第16分钟的时候,开始有等间隔的消极情绪出现
我尝试把这部分的弹幕找出来
df_neg = df_se[(df_se['senti'] < 33.33) & (df_se['showTime'] > 1000)].sort_values(by=['senti','showTime'])df_neg[['content','senti','showTime']].head(30)
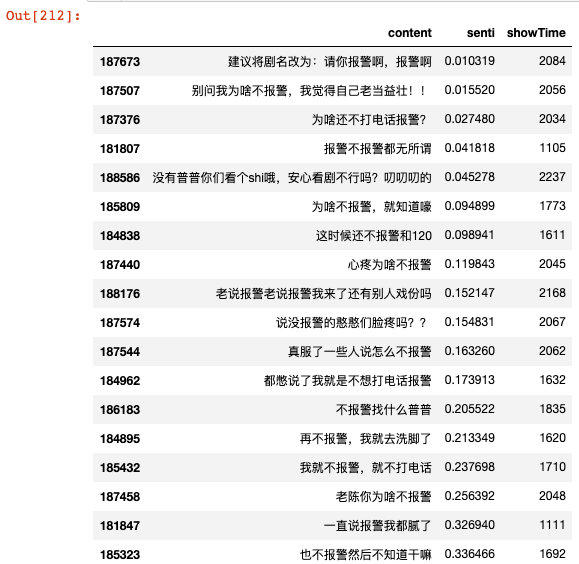
回顾剧情,这一段确实是这部剧的高潮之一,观众对剧中是否报警的问题进行了吐槽...
总结一下整12集中的情绪占比?
import matplotlib.pyplot as pltneg_count = df_total_senti[df_total_senti['senti'] < 33.3]['chapter'].count()
neu_count = df_total_senti[df_total_senti['senti'] <= 66.7]['chapter'].count() - neg_count
pos_count = df_total_senti[df_total_senti['senti'] > 66.7]['chapter'].count()
pie_x = [neg_count,neu_count,pos_count]
pie_lables = ['neg','neu','pos']
plt.figure(figsize=(20,8),dpi=80)
plt.pie(pie_x,labels=pie_lables,autopct='%1.2f%%')
plt.legend()
plt.show()
显然还是积极的言论较多呀,占了45%,接近一半
演员的热度,是怎样的呢?
首先上一个词云图
plt.figure(figsize=(144,90),dpi=40)wc = WordCloud(
font_path=font_path, # 设置字体格式
mask=mask,
max_words=3000,
max_font_size=100,
stopwords=STOPWORDS,
scale=4,
background_color='black',
random_state=40
).generate(word_str)
# 显示词云图
plt.imshow(wc)
plt.axis("off")
plt.savefig('cloud.jpg')
plt.show()

"爬山"
那么来看看爬山这个词到底出现了多少次?
df[df['content'].str.contains('爬山')==True].count()结果是5810条,占了5810/203667 ≈ 2.85 % 感觉..确实不少?
每个演员的热度值?
roles = {'朱朝阳':'朝阳|阳阳|学霸|第一名',
'严良':'严良|颜良',
'普普':'普普|岳普',
'张东升':'东升|张老师|秦昊',
'朱永平':'永平|颂文',
'周春红':'春红|刘琳|妈妈',
'王瑶':'王瑶|李梦',
'王立':'王立',
'徐静':'徐静|米依',
'陈冠声':'陈冠声|老陈|王景春',
'叶军':'叶军',
'马主任':'主任|老马',
'朱晶晶':'晶晶',
'叶驰敏':'驰敏|第二名'
}
### 省略的代码
显然热度最高的还是
张东升+3个小孩,只是没想到朱朝阳出现的字眼这么少除了4个主角,还可以看出老陈和王瑶,还有周春红也成为了讨论的热点
关注一下张东升?
来看看大家对张东升的讨论,随着时间的变化,情绪是怎样的?
df_total_senti_dong = df_total_senti[df_total_senti['content'].str.contains('东升|张老师|秦昊|昊')]df_total_senti_dong.groupby('chapter')['senti'].mean().plot()
可以看到前两集关于张老师的弹幕的平均情绪较高,逐渐降低到第五集,又再次反弹
特意去看了一下第五集和第六集的剧情,好像张老师的身影比较少,再去翻看这些较为中立的言论
df_total_senti_dong[df_total_senti_dong['chapter']==5].sort_values(by='senti')[['content','senti']].head(40)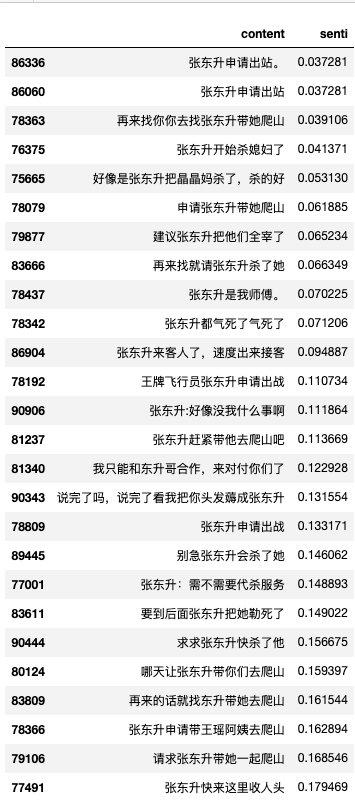
确实从这些弹幕中,可以看出第五集的张东升戏份较少,观众一直在呼唤他..显得情绪较为中立或是消极?
想通过看发弹幕的时间来看看这个剧是什么时候开始爆火的?
df['timestamp'].groupby(df['timestamp'].map(lambda x:str(x)[5:10])).count().plot(grid=True)- 显然从一开始这个电视剧的热度就一直上涨
- 可以清晰的看到有两个峰值,分别是6月19日和6月25日,翻了一下记录...25日是峰值是因为那天是大结局,所以25日之后的热度就下降了
追剧时间段?
先看看发弹幕的人,都是在哪个时段发的比较多,想知道追剧的人一般都是几点看剧?
df['timestamp'].groupby(df['timestamp'].map(lambda x:str(x)[11:13])).count().plot(grid=True)- 可以看出看剧较多的时间段是中午12点前后(中午休息)和晚上21点前后,都很符合人的作息规律
- 不可思议的是从0点到5点居然还有一部分的熬夜追剧党
是否能较模糊地推断出深度使用和轻度使用爱奇艺看这部剧用户的占比?能否简单推断二刷的人数?
注意到有些用户的昵称是初始值“未知用户”,那么这些疑似轻度用户和重度使用用户的占比是怎样的呢?
df.drop_duplicates(['uname','senderAvater']).count()
df[df['uname']=='未知用户'].count()
结果约有2229个用户名,其中有一个是重复使用多次的'未知用户' 使用'未知用户'这个默认用户名的有116102个
可以初步推断2228个重度使用的用户 有120692-2228 = 118464个轻度使用的用户
想看看大概有多少个用户是二刷的?
思路是想看看有多少条弹幕是提及二刷的,并将uid去重后计数
df[df['content'].str.contains('二刷')==True].drop_duplicates('uid').count()结果只有78条,并不理想,也许只能证明只有至少78个人是来二刷的
以上是 《隐秘的角落》20万条弹幕的爬取与分析 的全部内容, 来源链接: utcz.com/a/31924.html