
python调用图灵机器人实现微信公众号的自动回复功能(下)
图灵机器人接口调用限制的解决
昨天我们的文章中说到:使用图灵机器人作为应答机器人可以满足要求,但是每天的回复条数在不花钱的情况下只能有100条。对于我这样贫困线人口怎么可能每个月花费99元就为了自动回复呢。于是我就在想还有没有其它的方式能够快速做一个请求和应答表呢?
结合我之前工作上的经验,那我理解就是直接将请求语句的关键词和需要的回复放在一个Excel表格中,然后直接通过查询Excel表格这样也能做到自动回复,说干就干。整个流程如下图:
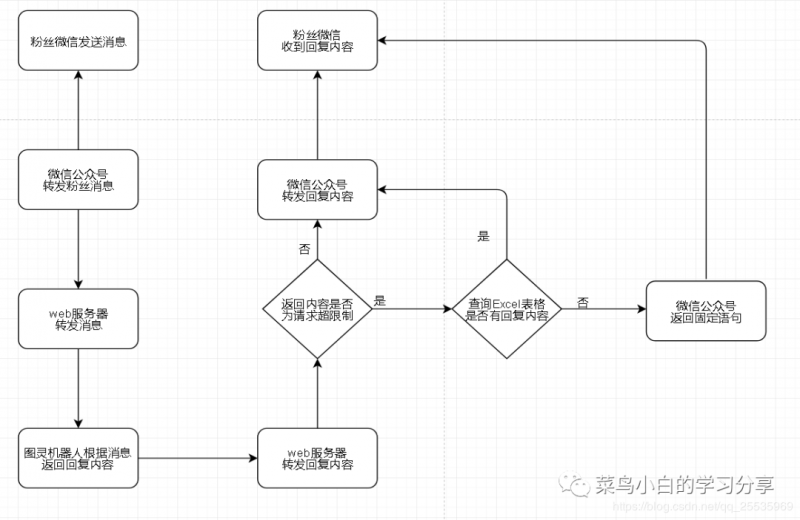
从流程图上看我们还是在昨天的整体框架上新增后续的容错处理,一旦检测到图灵机器人API请求已用完之后,我们便启动我们的容错机制,在我们的Excel表格中去查找我们需要返回的内容,若没有找到的话,我们就直接返回一个固定语句告诉粉丝朋友,我们现在可能没有听懂。
整体已经说完了,接下来我们就开始实干了。首先我们需要去读取一个Excel表格,我使用的是xlrd这个库(一样啊,安装方法参考之前的python学习三——库安装),由于之前我们已经整理了一个Excel表格的读写模块——ReadAndWriteExcel.py,所以在这里我直接将这个模块拿过来调用就好了,具体代码见下:
# _*_coding=utf-8_*_import xlwt
import xlrd
classWriteExcel:
def__init__(self, sheet_name=None):
"""初始化写表格对象
:param sheet_name: 写表格的sheet名,默认为1
"""
if sheet_name:
self.sheetname = sheet_name
else:
self.sheetname = "1"
self.workbook = xlwt.Workbook()
self.worksheet = self.workbook.add_sheet(sheetname=self.sheetname)
defwrite_values(self, row, col, values):
"""向目标sheet的某个行列写入值
:param row: 目标行
:param col: 目标列
:param values: 想要写入的值
"""
self.worksheet.write(row, col, values)
defsave_file(self, filename=None):
"""保存表格
:param filename: 保存的文件名
"""
if filename:
self.filename = filename
else:
self.filename = "test.xls"
self.workbook.save(self.filename)
classOpenExcel:
def__init__(self, file_name=None, sheet_id=None):
"""初始化读取Excel表格
:param file_name: 需要读取的表格名
:param sheet_id: 需要读取的表格sheet
"""
if file_name:
self.file_name = file_name
self.sheet_id = sheet_id
else:
self.file_name = 'example.xlsx'
self.sheet_id = 0
self.data = self.get_data()
defget_data(self):
"""读取表格数据
:return: 返回读取的表格数据
"""
data = xlrd.open_workbook(self.file_name)
tables = data.sheets()[self.sheet_id]
return tables
defget_lines(self):
"""读取表格总行数
:return: 返回表格总行数
"""
tables = self.data
return tables.nrows
defget_cols(self):
"""读取表格总行数
:return: 返回表格总列数
"""
tables = self.data
return tables.ncols
defget_value(self, row, col):
"""读取表格中具体的行、列对应的值
:param row: 目标行
:param col: 目标列
:return: 返回目标行、列的值
"""
return self.data.cell_value(row, col)
if __name__ == '__main__':
openexcel = OpenExcel(file_name="work.xls",sheet_id=0)
print (openexcel.get_lines())
write_excel = WriteExcel()
for j in range(0,openexcel.get_cols()):
for i in range(0,openexcel.get_lines()):
write_excel.write_values(i,j,openexcel.get_value(i,j))
write_excel.write_values(100,100,"我是谁")
write_excel.save_file()
接下来我们如下弄一个调用程序来调用ReadAndWriteExcel.py,实现我们根据第一列的关键词返回第二列的回复内容。代码如下:
import ReadAndWriteExcel
defexcel_reply(msg):
"""关键字回复"""
keyword_read = ReadAndWriteExcel.OpenExcel(file_name="KeyWord.xlsx",sheet_id=0)
for i in range(0,keyword_read.get_lines()):
if msg in keyword_read.get_value(i,0):
return keyword_read.get_value(i,1)
if'你叫啥'in msg or'你叫啥名字'in msg:
return'沃德天·维森莫·拉莫帅·帅德布耀'
elif'我爱你'in msg:
return"我也爱你"
elif'早安'in msg:
return"早安啊,朋友"
else:
return'我没有听懂你在说什么,n或许我休息一天,n明天就能智商上线了~'
pass
这里我们不仅仅是通过读取Excel,也将一些固定的回复放在代码中进行调试了。接下来我们来看看主程序的代码。
# -*- coding:utf-8 -*-from flask import Flask
from flask import request
import hashlib
import tyuling_replay
import time
import re
import ReplayFromExcel
import xml.etree.ElementTree as ET
app = Flask(__name__)
@app.route("/")
defindex():
return"Hello World!"
@app.route("/wechat", methods=["GET","POST"])
defweixin():
if request.method == "GET": # 判断请求方式是GET请求
my_signature = request.args.get('signature') # 获取携带的signature参数
my_timestamp = request.args.get('timestamp') # 获取携带的timestamp参数
my_nonce = request.args.get('nonce') # 获取携带的nonce参数
my_echostr = request.args.get('echostr') # 获取携带的echostr参数
# my_token = request.args.get('token')
print(my_signature)
print(my_timestamp)
print(my_nonce)
print(my_echostr)
# print(my_token)
token = '123456'# 一定要跟刚刚填写的token一致
# 进行字典排序
data = [token,my_timestamp ,my_nonce ]
data.sort()
# 拼接成字符串,进行hash加密时需为字符串
data = ''.join(data)
#创建一个hash对象
s = hashlib.sha1()
#对创建的hash对象更新需要加密的字符串
s.update(data.encode("utf-8"))
#加密处理
mysignature = s.hexdigest()
print("handle/GET func: mysignature, my_signature: ", mysignature, my_signature)
# 加密后的字符串可与signature对比,标识该请求来源于微信
if my_signature == mysignature:
return my_echostr
else:
return""
else:
# 解析xml
xml = ET.fromstring(request.data)
toUser = xml.find('ToUserName').text
fromUser = xml.find('FromUserName').text
msgType = xml.find("MsgType").text
createTime = xml.find("CreateTime")
# 判断类型并回复
if msgType == "text":
content = xml.find('Content').text
#根据公众号粉丝的ID生成符合要求的图灵机器人userid
if len(fromUser)>31:
tuling_userid = str(fromUser[0:30])
else:
tuling_userid = str(fromUser)
tuling_userid=re.sub(r'[^A-Za-z0-9]+', '', tuling_userid)
#调用图灵机器人API返回图灵机器人返回的结果
tuling_replay_text = tyuling_replay.get_message(content,tuling_userid)
#将图灵机器人返回的内容发送给粉丝
if'4003'in tuling_replay_text:
return reply_text(fromUser, toUser,ReplayFromExcel.excel_reply(content))
else:
return reply_text(fromUser, toUser, tuling_replay_text)
else:
return reply_text(fromUser, toUser, "我只懂文字")
defreply_text(to_user, from_user, content):
"""
以文本类型的方式回复请求
"""
return"""
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[{}]]></Content>
</xml>
""".format(to_user, from_user, int(time.time() * 1000), content)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
我们在查看图灵机器人的API文档发现返回码为4003时为API接口调用次数已用完,所以我们之前判断4003是否在API接口的返回信息中,若存在,则图灵机器人API调用已用完,需要使用Excel备选方案进行答复。
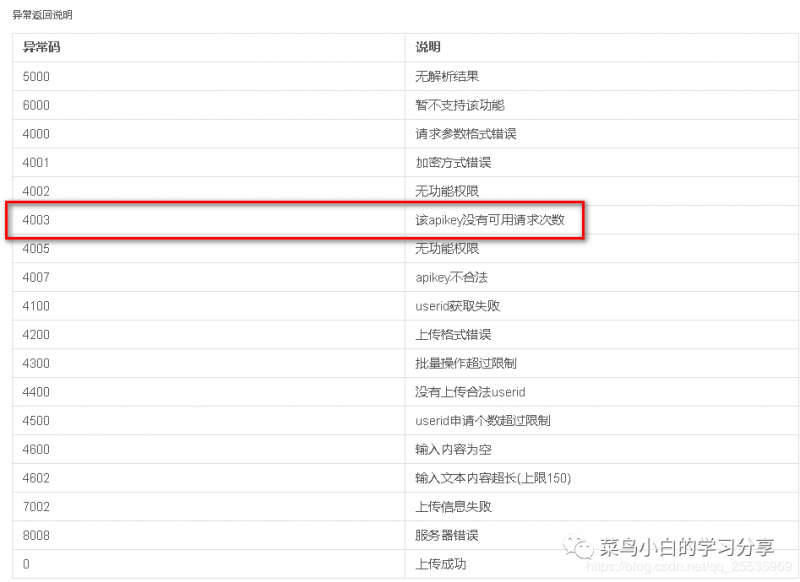
这样我们的微信公众号就再也不会出现服务器异常的报错了。
图片和关注的自动回复
这样配置了之后,我们还发现了一些问题,如:由于使用了API开发接口,导致公众号默认的自动化回复无法使用了。一、同样的关注的自动回复也不能同时使用了;二、上面我们的回复也一直都是针对的文字,对于图片消息无法进行应答。针对这两个问题,我们再次对我们的程序进行了优化,新增了关注自动回复和图片回复原图的情况。先上代码:
if msgType == "text":content = xml.find('Content').text
#根据公众号粉丝的ID生成符合要求的图灵机器人userid
if len(fromUser)>31:
tuling_userid = str(fromUser[0:30])
else:
tuling_userid = str(fromUser)
tuling_userid=re.sub(r'[^A-Za-z0-9]+', '', tuling_userid)
#调用图灵机器人API返回图灵机器人返回的结果
tuling_replay_text = tyuling_replay.get_message(content,tuling_userid)
#将图灵机器人返回的内容发送给粉丝
if'4003'in tuling_replay_text:
return reply_text(fromUser, toUser,ReplayFromExcel.excel_reply(content))
else:
return reply_text(fromUser, toUser, tuling_replay_text)
#关注公众号的自动答复
elif msgType == "event":
Event = xml.find('Event').text
if Event == "subscribe":
subscribe_reply = "菜鸟小白终于等到你~n"
"我们可以一起学习打卡,n"
"一起努力成长。n"
"你烦闷时,我还可以陪你聊天解闷哦~"
return reply_text(fromUser, toUser, subscribe_reply)
elif msgType == "image":
mediaId = xml.find('MediaId').text
return reply_image(fromUser, toUser, mediaId)
else:
return reply_text(fromUser, toUser, "我只懂文字")
defreply_text(to_user, from_user, content):
"""
以文本类型的方式回复请求
return"""<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[{}]]></Content>
</xml>
"""
.format(to_user, from_user, int(time.time() * 1000), content)defreply_image(to_user, from_user, mediaId):
以图片类型的方式回复请求,返回原图片
return"""<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[{}]]></MediaId>
</Image>
</xml>
"""
.format(to_user, from_user, int(time.time() * 1000), mediaId)通过对微信公众号开发文档的阅读,我们发现文字类消息和图片类消息的区分在于msgType,文字类型消息为text,图片类消息为image。对于图片类的消息图片是保存在MediaId字段中,我们只需要将这个在返回给粉丝就好了,就是原图返给粉丝。
我们也发现新增粉丝关注时,我们收到的是一个msgType是event,当event中的包含的内容是subscribe时为粉丝关注,我们判断收到这样的消息,就返回需要回复粉丝的内容即可。
当然这样还会有一些其他的问题,如怎么回复音频、视频。这个方法都是类似的,你们可以参考微信公众号的开发手册,自己想想该如何解决。
关注微信公众号“菜鸟小白的学习分享”回复“101”获取微信公众号自动回复机器人源码哦。
关注微信公众号“菜鸟小白的学习分享”回复“100”获取微信公众号自动回复机器人可执行程序哦。
关注微信公众号——菜鸟小白的学习分享
妈妈再也不用担心我找不到路了
一个人的学习——孤单
一群人的学习——幸福
以上是 python调用图灵机器人实现微信公众号的自动回复功能(下) 的全部内容, 来源链接: utcz.com/a/30680.html




