
💥记一次简单JS爬虫
一、近况
最近很烦,干啥啥不行,吃喝玩乐第一名。可是自己又不是富家子弟!!!所以还得学习!!!在公司日常划水中,这时,我的领导走了过来,难道是有新需求了。我的心里还是很期待的,毕竟已经很久没活了。这时领导丢过来一个网址。

宝哥你看看这个网站,能不能把上面的信息给我扒下来?一听到扒这个字我就觉得事情并没有那么简单,这不是爬虫吗?以前对于爬虫,只是听过没见过,心里还是有点虚的,只是说了一句我先看看。

二、什么是爬虫?
我们打开网站
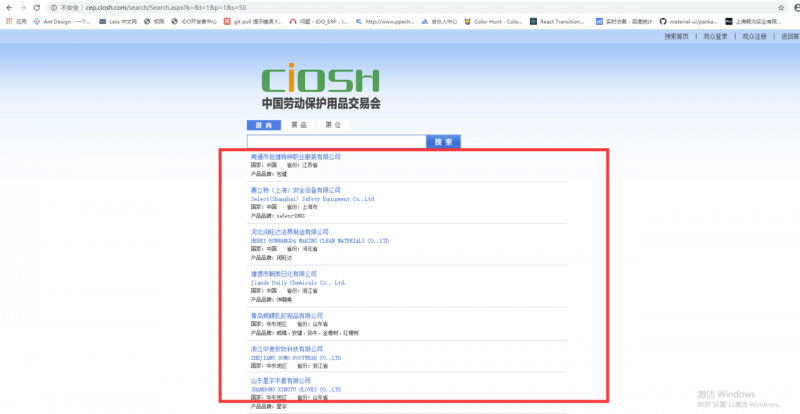
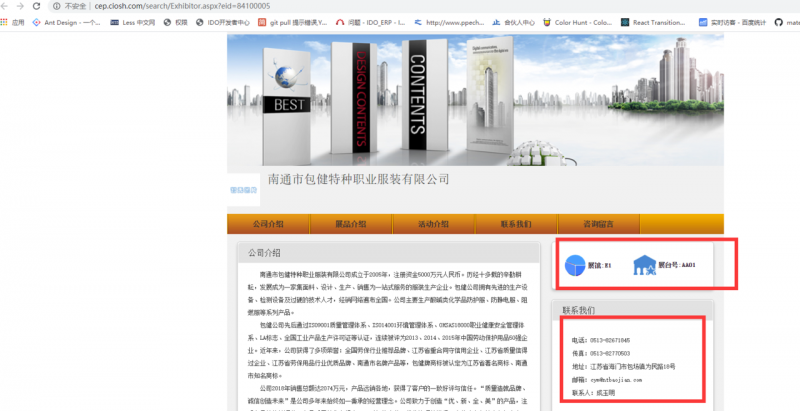
公司希望将这三部分的信息扒下来,以excel的形式导出。我熟练的按下F12,点开network。

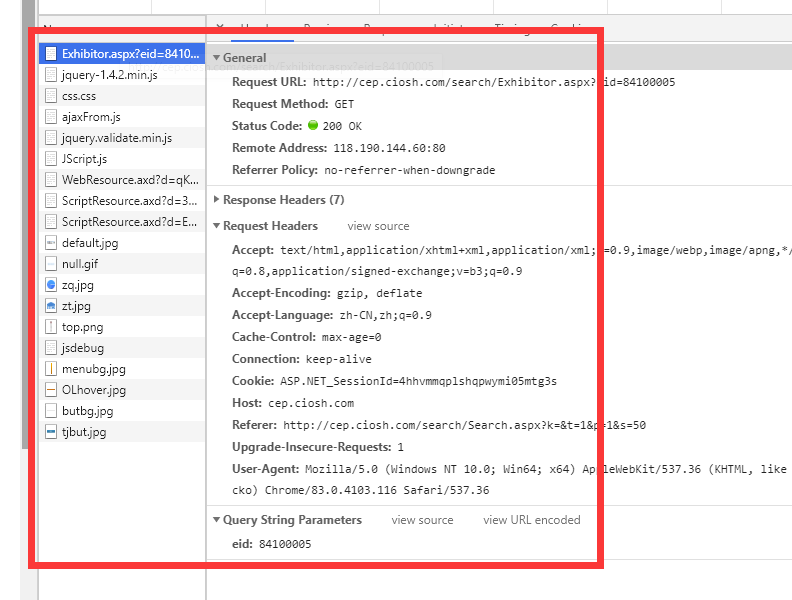
由接口我们分析出来
t -1、2、3分别代表展商、展品、展位、s为每页的大小、p为分页、至于k尚未得知
通过分析,我们得出了其实就是2个接口,接口返回的是
html,而且这些数据都是包含在Html里面的。所以就可以很轻松的拿出我们想要的数据,此时我开始疑惑了?这就是传说中的爬虫?把html的数据拿下来!!
个人理解,希望大佬能更深入的解释爬虫!
三、百度+解答
本着
js天下第一和啥都能做的原则,我搜索了js爬虫导出excel,大量的资料映入眼帘,node真牛逼!

1.新建文件夹
新建文件夹creeper来开启我们的爬虫征程
2.npm init
npm init初始化node项目
3.新建index.js文件
const xlsx = require('node-xlsx')//xlsx 库
const fs = require('fs') //文件读写库
const request = require("request-promise-native");//request请求库
const cheerio = require("cheerio");
let data = [] // 把这个数组写入excel
request({
url: "http://cep.ciosh.com/search/Search.aspx?k=&t=1&p=1&s=1050",//你要请求的地址
method: "get",//请求方法 post get
headers: {
"content-type": "text/html",
"Cookie": ""//如果携带了cookie
},
}, asyncfunction (error, response, body) {
if (!error && response.statusCode == 200) {
$ = cheerio.load(body, {
withDomLvl1: true,
normalizeWhitespace: false,
xmlMode: false,
decodeEntities: true
});
let title = ['展商名称', '国家','省份', '产品品牌','展馆','展台','电话', '传真', '地址', '邮箱', '联系人']//设置表头
data.push(title) // 添加完表头 下面就是添加真正的内容了
let items = $(".c_result").children(".item");
for (let i = 0; i < items.length; i++) {
let arrInner = []
let list=$(items[i]).children(".t").text();
arrInner.push(list)
arrInner.push($(items[i]).children(".c").text()?$(items[i]).children(".c").text().trim().split("省份")[0].trim().replace("国家:",""):"")
arrInner.push($(items[i]).children(".c").text().trim().split("省份")[1]?$(items[i]).children(".c").text().trim().split("省份")[1].slice(1):"")
arrInner.push($(items[i]).children(".d").text()?$(items[i]).children(".d").text().trim().slice(5):"")
let id = $(items[i]).children(".t").children("a").attr("href").split("?")[1].split("=")[1]
functiontest(ms){
let _request=request.get(`http://cep.ciosh.com/search/Exhibitor.aspx?eid=${id}`).then(response=>response).catch(err=>err)
returnnewPromise((resolve, reject) => {
setTimeout(() => {
try{
resolve(_request)
}catch{
reject([])
}
}, ms);
})
}
let info = await test(0.1).catch(err=>{
console.log('请求失败');
});
$info = cheerio.load(info, {
withDomLvl1: true,
normalizeWhitespace: false,
xmlMode: false,
decodeEntities: true
});
let table_info=$info(".OL_Booth table:nth-child(1) table:nth-child(1) tr:nth-child(1) td:nth-child(2)").text().trim();
arrInner.push(table_info?table_info.split("展台号")[0].slice(3):"")
arrInner.push(table_info?table_info.split("展台号:")[1]:"");
arrInner.push($info(".OL_Contactus p:nth-child(1)").text().trim().slice(3))
arrInner.push($info(".OL_Contactus p:nth-child(2)").text().trim().slice(3))
arrInner.push($info(".OL_Contactus p:nth-child(3)").text().trim().slice(3))
arrInner.push($info(".OL_Contactus p:nth-child(4)").text().trim().slice(3))
arrInner.push($info(".OL_Contactus p:nth-child(5)").text().trim().slice(4))
data.push(arrInner)
}
writeXls(data)
}
});
process.on('unhandledRejection', error => {
console.error('unhandledRejection', error);
process.exit(1) // To exit with a 'failure' code
});
// 写xlsx文件
functionwriteXls(datas) {
let buffer = xlsx.build([
{
name: 'sheet1',
data: datas
}
]);
fs.writeFileSync('./data.xlsx', buffer, { 'flag': 'w' });//生成excel data是excel的名字
}
4.核心内容讲解
1.node-xlsx
生成excel的2.request-promise-native
请求库3.cheerio
轻量级cheerio,用过jq都说好4.过程
通过分析我们得出列表的接口http://cep.ciosh.com/search/Search.aspx?k=&t=1&p=1&s=1050,然后得出总列表的节点,循环遍历出列表节点的a标签下的id,再请求http://cep.ciosh.com/search/Exhibitor.aspx?eid=${id},将相对应数据推进数组,即可。
四、总结
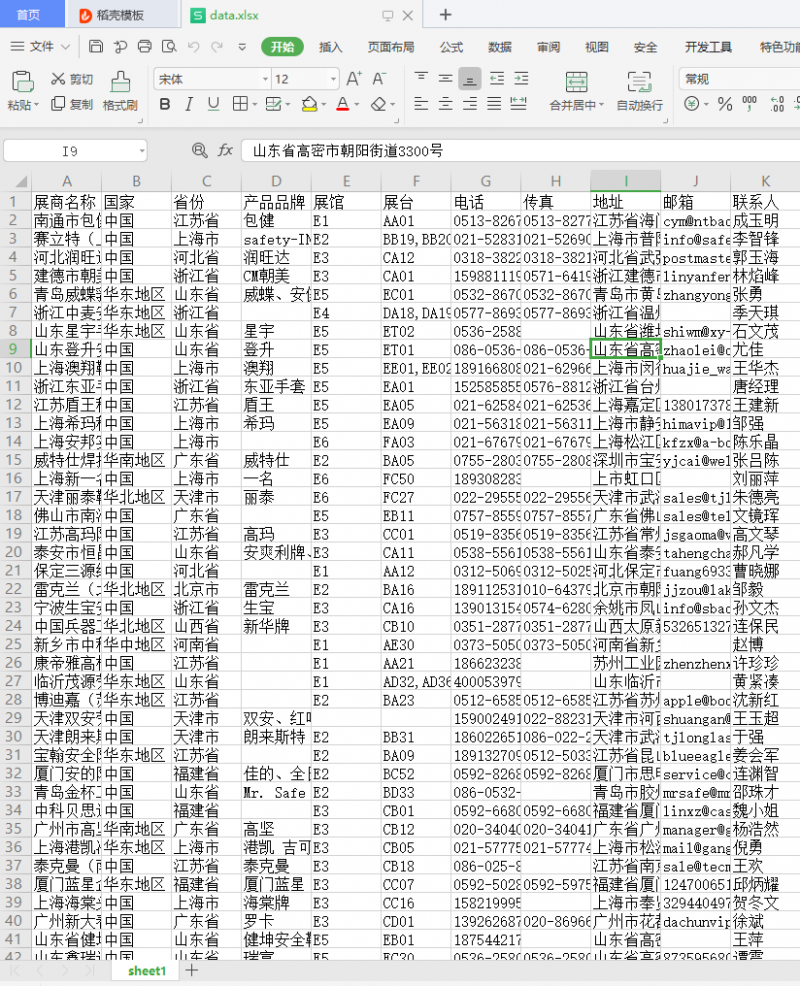
代码已写完,我们执行node index.js命令,最终会生成一个xlsx文件。
五、待完善细节
我们的思路是没问题的,但是在请求第二个接口的时候,不知道是请求频繁还是什么缘故会经常报请求超时错误,我这里写的是如果请求报错直接跳过,所以我们在导出的excel中会有信息不是很完善,我们希望在请求接口报错的时候再次请求这个接口。
文章代码git仓库

以上是 💥记一次简单JS爬虫 的全部内容, 来源链接: utcz.com/a/28979.html



