python爬虫requests库无法获得网页上的某个标签的信息
学习爬虫的时候发现自己某个标签无法获得
本人是爬虫初学者,在学习爬取爬虫的时候发现某个标签无法获得,想要爬取的网站叫优书网,网址为https://www.yousuu.com/bookst...
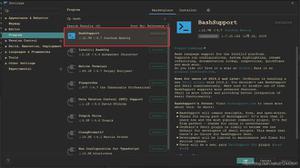
爬取的内容主要是图上的一些网文信息,具体可以看图:
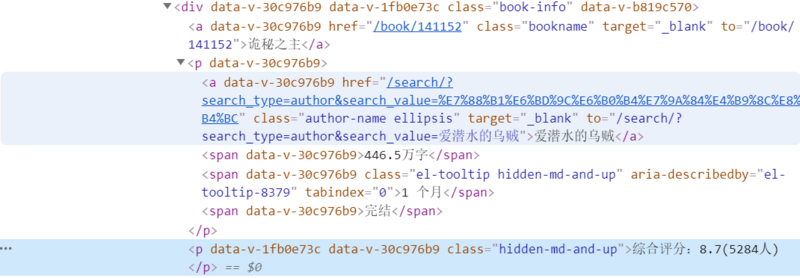
但是发现自己使用request库的时候没有找到 <a>"爱潜水的乌贼"</a>的内容,但是其他的信息都能查到,使用debug调试可以看到我获得的网页代码
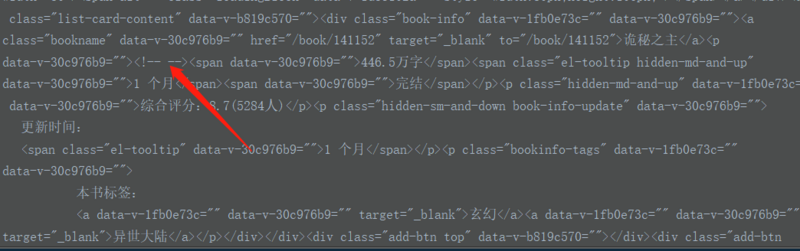
其中看到想要爬取的<a>此标签中包含的数据都在soup中变成了<!-- -->
此外我在soup的下面还是看到了我想看到的数据
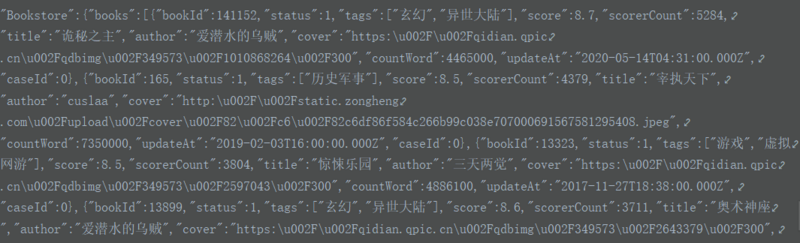
但和我想的差距比较大,爬取数据并不是目的,相比数据(我还可以爬取json也能获得想要的数据),我更希望知道这是什么原因,希望能够得到您的~~~~解答
回答
1.代码问题
没有放上代码,不好判断你写的xpath或regex语法是否正确
2.页面渲染问题
看图能知道这个接口返回的是html页面。那么内部的a标签有可能不在返回的html页面中,而是通过其他的手段,比如动态请求返回数据,然后通过js渲染到html页面中。这个要具体分析,你给的地址不全,也不好判断
以上是 python爬虫requests库无法获得网页上的某个标签的信息 的全部内容, 来源链接: utcz.com/a/26106.html