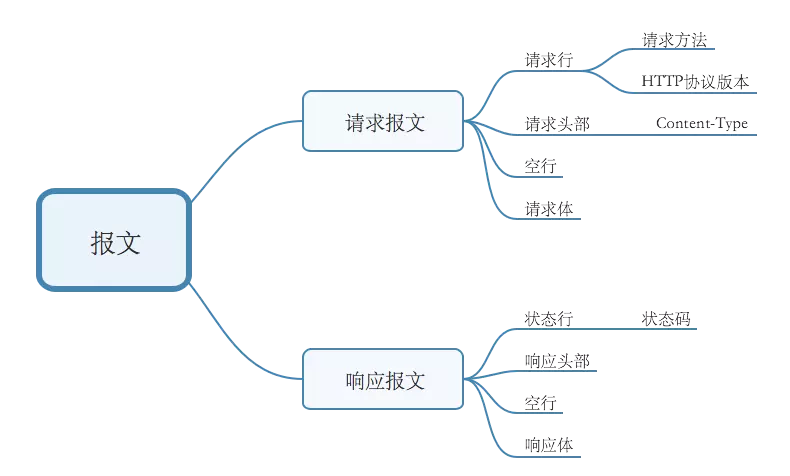
前端需要掌握的进阶知识(浏览器运行机制/前端优化/http/前端工程化模块化等)
浏览器运行机制
1.浏览器是多进程的区分进程和线程
- 进程是一个工厂,工厂有它的独立资源- 工厂之间相互独立
- 线程是工厂中的工人,多个工人协作完成任务
- 工厂内有一个或多个工人
- 工人之间共享空间
- 工厂的资源 -> 系统分配的内存(独立的一块内存)
- 工厂之间的相互独立 -> 进程之间相互独立
- 多个工人协作完成任务 -> 多个线程在进程中协作完成任务
- 工厂内有一个或多个工人 -> 一个进程由一个或多个线程组成
- 工人之间共享空间 -> 同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)
最后,再用较为官方的术语描述一遍:
进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
不同进程之间也可以通信,不过代价较大
现在,一般通用的叫法:单线程与多线程,都是指在一个进程内的单和多。(所以核心还是得属于一个进程才行)
2.浏览器是多进程的
浏览器是多进程的浏览器之所以能够运行,是因为系统给它的进程分配了资源(cpu、内存)
简单点理解,每打开一个Tab页,就相当于创建了一个独立的浏览器进程
3.浏览器都包含哪些进程?
1.Browser进程:浏览器的主进程(负责协调、主控),只有一个。作用有。负责浏览器界面显示,与用户交互。如前进,后退等
。负责各个页面的管理,创建和销毁其他进程
。将Renderer进程得到的内存中的Bitmap,绘制到用户界面上
。网络资源的管理,下载等
2.第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
3.GPU进程:最多一个,用于3D绘制等
4.浏览器渲染进程(浏览器内核)(Renderer进程,内部是多线程的):默认每个Tab页面一个进程,互不影响。主要作用为
。页面渲染,脚本执行,事件处理等
- 强化记忆:在浏览器中打开一个网页相当于新起了一个进程(进程内有自己的多线程)
4.浏览器多进程的优势
相比于单进程浏览器,多进程有如下优点:。避免单个page crash影响整个浏览器
。避免第三方插件crash影响整个浏览器
。多进程充分利用多核优势
。方便使用沙盒模型隔离插件等进程,提高浏览器稳定性
简单点理解:如果浏览器是单进程,那么某个Tab页崩溃了,就影响了整个浏览器,体验有多差;同理如果是单进程,插件崩溃了也会影响整个浏览器;而且多进程还有其它的诸多优势。。。
当然,内存等资源消耗也会更大,有点空间换时间的意思。
5.重点是浏览器内核(渲染进程)
重点来了,我们可以看到,上面提到了这么多的进程,那么,对于普通的前端操作来说,最终要的是什么呢?答案是渲染进程
可以这样理解,页面的渲染,JS的执行,事件的循环,都在这个进程内进行。接下来重点分析这个进程
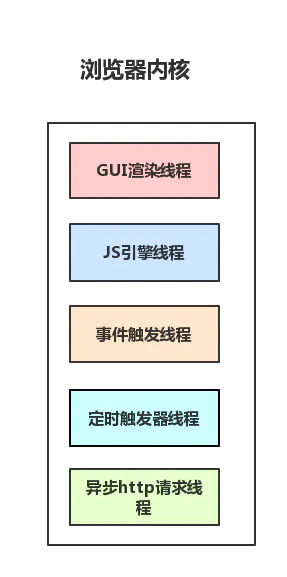
浏览器的渲染进程是多线程的
终于到了线程这个概念了😭,好亲切。那么接下来看看它都包含了哪些线程(列举一些主要常驻线程):
1.GUI渲染线程。负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
。当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
。注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行
2.JS引擎线程
。也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎)
。JS引擎线程负责解析Javascript脚本,运行代码
。JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
。同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞
3.事件触发线程
。归属于浏览器而不是JS引擎,用来控制事件循环(可以理解,JS引擎自己都忙不过来,需要浏览器另开线程协助)
。当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
。当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
。注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
4.定时触发器线程
。传说中的setInterval与setTimeout所在线程
。浏览器定时计数器并不是由JavaScript引擎计数的,(因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)
。因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
。注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
5.异步http请求线程
。在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
。将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。
6.Browser进程和浏览器内核(Renderer进程)的通信过程
如果自己打开任务管理器,然后打开一个浏览器,就可以看到:任务管理器中出现了两个进程(一个是主控进程,一个则是打开Tab页的渲染进程), 然后在这前提下,看下整个的过程:(简化了很多)
Browser进程收到用户请求,首先需要获取页面内容(譬如通过网络下载资源),随后将该任务通过RendererHost接口传递给Render进程Renderer进程的Renderer接口收到消息,简单解释后,交给渲染线程,然后开始渲染
。渲染线程接收请求,加载网页并渲染网页,这其中可能需要Browser进程获取资源和需要GPU进程来帮助渲染
。当然可能会有JS线程操作DOM(这样可能会造成回流并重绘)
。最后Render进程将结果传递给Browser进程
Browser进程接收到结果并将结果绘制出来
7.梳理浏览器内核中线程之间的关系
GUI渲染线程与JS引擎线程互斥
由于JavaScript是可操纵DOM的,如果在修改这些元素属性同时渲染界面(即JS线程和UI线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置GUI渲染线程与JS引擎为互斥的关系,当JS引擎执行时GUI线程会被挂起, GUI更新则会被保存在一个队列中等到JS引擎线程空闲时立即被执行。
JS阻塞页面加载
要尽量避免JS执行时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
WebWorker,JS的多线程?
前文中有提到JS引擎是单线程的,而且JS执行时间过长会阻塞页面,那么JS就真的对cpu密集型计算无能为力么?
后来HTML5中支持了 Web Worker。
MDN的官方解释是
Web Worker为Web内容在后台线程中运行脚本提供了一种简单的方法。线程可以执行任务而不干扰用户界面
一个worker是使用一个构造函数创建的一个对象(e.g. Worker()) 运行一个命名的JavaScript文件这个文件包含将在工作线程中运行的代码; workers 运行在另一个全局上下文中,不同于当前的window
因此,使用 window快捷方式获取当前全局的范围 (而不是self) 在一个 Worker 内将返回错误
这样理解下:
。创建Worker时,JS引擎向浏览器申请开一个子线程(子线程是浏览器开的,完全受主线程控制,而且不能操作DOM)。JS引擎线程与worker线程间通过特定的方式通信(postMessage API,需要通过序列化对象来与线程交互特定的数据)
所以,如果有非常耗时的工作,请单独开一个Worker线程,这样里面不管如何翻天覆地都不会影响JS引擎主线程, 只待计算出结果后,将结果通信给主线程即可,perfect!
而且注意下,JS引擎是单线程的,这一点的本质仍然未改变,Worker可以理解是浏览器给JS引擎开的外挂,专门用来解决那些大量计算问题。
8.WebWorker与SharedWorker
WebWorker只属于某个页面,不会和其他页面的Render进程(浏览器内核进程)共享
。所以Chrome在Render进程中(每一个Tab页就是一个render进程)创建一个新的线程来运行Worker中的JavaScript程序。
SharedWorker是浏览器所有页面共享的,不能采用与Worker同样的方式实现,因为它不隶属于某个Render进程,可以为多个Render进程共享使用
。所以Chrome浏览器为SharedWorker单独创建一个进程来运行JavaScript程序,在浏览器中每个相同的JavaScript只存在一个SharedWorker进程,不管它被创建多少次。
本质上就是进程和线程的区别。SharedWorker由独立的进程管理,WebWorker只是属于render进程下的一个线程9.浏览器渲染流程
- 浏览器输入url,浏览器主进程接管,开一个下载线程,然后进行 http请求(略去DNS查询,IP寻址等等操作),然后等待响应,获取内容,
随后将内容通过RendererHost接口转交给Renderer进程
- 浏览器渲染流程开始
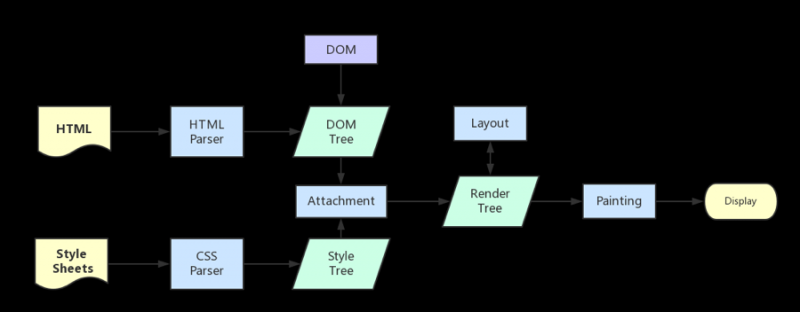
浏览器器内核拿到内容后,渲染大概可以划分成以下几个步骤:
1.解析html建立dom树
2.解析css构建render树(将CSS代码解析成树形的数据结构,然后结合DOM合并成render树)3.布局render树(Layout/reflow),负责各元素尺寸、位置的计算
4.绘制render树(paint),绘制页面像素信息
5.浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上。
load事件与DOMContentLoaded事件的先后
上面提到,渲染完毕后会触发load事件,那么你能分清楚load事件与DOMContentLoaded事件的先后么?
- 当 DOMContentLoaded 事件触发时,仅当DOM加载完成,不包括样式表,图片。 (譬如如果有async加载的脚本就不一定完成)
- 当 onload 事件触发时,页面上所有的DOM,样式表,脚本,图片都已经加载完成了。 (渲染完毕了)
- 顺序是:DOMContentLoaded -> load
css加载是否会阻塞dom树渲染?
这里说的是头部引入css的情况首先,我们都知道:css是由单独的下载线程异步下载的。
- css加载不会阻塞DOM树解析(异步加载时DOM照常构建)
- 但会阻塞render树渲染(渲染时需等css加载完毕,因为render树需要css信息)
这可能也是浏览器的一种优化机制。
因为你加载css的时候,可能会修改下面DOM节点的样式,如果css加载不阻塞render树渲染的话,那么当css加载完之后,
render树可能又得重新重绘或者回流了,这就造成了一些没有必要的损耗。
所以干脆就先把DOM树的结构先解析完,把可以做的工作做完,然后等你css加载完之后,
在根据最终的样式来渲染render树,这种做法性能方面确实会比较好一点。
普通图层和复合图层
渲染步骤中就提到了composite概念。
可以简单的这样理解,浏览器渲染的图层一般包含两大类:普通图层以及复合图层
首先,普通文档流内可以理解为一个复合图层(这里称为默认复合层,里面不管添加多少元素,其实都是在同一个复合图层中)
其次,absolute布局(fixed也一样),虽然可以脱离普通文档流,但它仍然属于默认复合层。
然后,可以通过硬件加速的方式,声明一个新的复合图层,它会单独分配资源 (当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响默认复合层里的回流重绘)
可以简单理解下:GPU中,各个复合图层是单独绘制的,所以互不影响,这也是为什么某些场景硬件加速效果一级棒
可以Chrome源码调试 -> More Tools -> Rendering -> Layer borders中看到,黄色的就是复合图层信息
如何变成复合图层(硬件加速)
将该元素变成一个复合图层,就是传说中的硬件加速技术
最常用的方式:translate3d、translateZ
opacity属性/过渡动画(需要动画执行的过程中才会创建合成层,动画没有开始或结束后元素还会回到之前的状态)
will-chang属性(这个比较偏僻),一般配合opacity与translate使用(而且经测试,除了上述可以引发硬件加速的属性外,其它属性并不会变成复合层), 作用是提前告诉浏览器要变化,这样浏览器会开始做一些优化工作(这个最好用完后就释放)
video iframe canvas webgl 等元素
譬如以前的flash插件
。 absolute和硬件加速的区别可以看到,absolute虽然可以脱离普通文档流,但是无法脱离默认复合层。
所以,就算absolute中信息改变时不会改变普通文档流中render树,
但是,浏览器最终绘制时,是整个复合层绘制的,所以absolute中信息的改变,仍然会影响整个复合层的绘制。
(浏览器会重绘它,如果复合层中内容多,absolute带来的绘制信息变化过大,资源消耗是非常严重的)
。 复合图层的作用?
一般一个元素开启硬件加速后会变成复合图层,可以独立于普通文档流中,改动后可以避免整个页面重绘,提升性能
但是尽量不要大量使用复合图层,否则由于资源消耗过度,页面反而会变的更卡
。硬件加速时请使用index
使用硬件加速时,尽可能的使用index,防止浏览器默认给后续的元素创建复合层渲染
具体的原理时这样的:
webkit CSS3中,如果这个元素添加了硬件加速,并且index层级比较低,
那么在这个元素的后面其它元素(层级比这个元素高的,或者相同的,并且releative或absolute属性相同的),
会默认变为复合层渲染,如果处理不当会极大的影响性能
简单点理解,其实可以认为是一个隐式合成的概念:如果a是一个复合图层,而且b在a上面,那么b也会被隐式转为一个复合图层,这点需要特别注意
浏览器兼容性问题
普及:浏览器的兼容性问题,往往是个别浏览器(没错,就是那个与众不同的浏览器)对于一些标准的定义不一致导致的。俗话说:没有IE就没有伤害。Normalize.css
不同浏览器的默认样式存在差异,可以使用 Normalize.css 抹平这些差异。当然,你也可以定制属于自己业务的 reset.css
<link href="https://cdn.bootcss.com/normalize/7.0.0/normalize.min.css" rel="stylesheet">
简单粗暴法
* { margin: 0; padding: 0; }
html5shiv.js
解决 ie9 以下浏览器对 html5 新增标签不识别的问题。
<!--[if lt IE 9]>
<script type="text/javascript" src="https://cdn.bootcss.com/html5shiv/3.7.3/html5shiv.min.js"></script>
<![endif]-->
respond.js
解决 ie9 以下浏览器不支持 CSS3 Media Query 的问题。
<script src="https://cdn.bootcss.com/respond.js/1.4.2/respond.min.js"></script>
picturefill.js
解决 IE 9 10 11 等浏览器不支持 <picture> 标签的问题
<script src="https://cdn.bootcss.com/picturefill/3.0.3/picturefill.min.js"></script>
IE 条件注释
IE 的条件注释仅仅针对IE浏览器,对其他浏览器无效
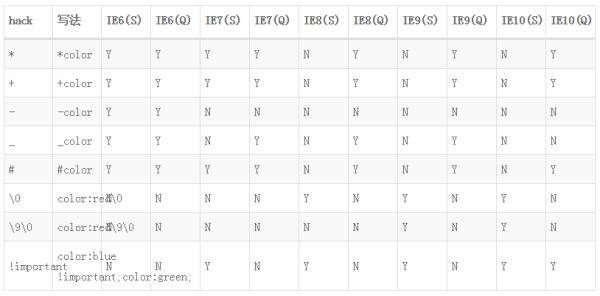
IE 属性过滤器(较为常用的hack方法)
针对不同的 IE 浏览器,可以使用不同的字符来对特定的版本的 IE 浏览器进行样式控制

浏览器 CSS 兼容前缀-o-transform:rotate(7deg); // Opera
-ms-transform:rotate(7deg); // IE
-moz-transform:rotate(7deg); // Firefox
-webkit-transform:rotate(7deg); // Chrome
transform:rotate(7deg); // 统一标识语句
a 标签的几种 CSS 状态的顺序
很多新人在写 a 标签的样式,会疑惑为什么写的样式没有效果,或者点击超链接后,hover、active 样式没有效果,其实只是写的样式被覆盖了
正确的a标签顺序应该是:==love hate==
. link:平常的状态
. visited:被访问过之后
. hover:鼠标放到链接上的时候
. active:链接被按下的时候
完美解决 Placeholder
<input type="text" value="Name *" onFocus="this.value = '';" onBlur="if (this.value == '') {this.value = 'Name *';}">
清除浮动 最佳实践
.fl { float: left; }
.fr { float: right; }
.clearfix:after { display: block; clear: both; content: ""; visibility: hidden; height: 0; }
.clearfix { zoom: 1; }
BFC 解决边距重叠问题
当相邻元素都设置了 margin 边距时,margin 将取最大值,舍弃小值。为了不让边距重叠,可以给子元素加一个父元素,并设置该父元素为 BFC:overflow: hidden;
<div class="box" id="box">
<p>Lorem ipsum dolor sit.</p>
<div>
<p>Lorem ipsum dolor sit.</p>
</div>
<p>Lorem ipsum dolor sit.</p>
</div>
IE6 双倍边距的问题
设置 ie6 中设置浮动,同时又设置 margin,会出现双倍边距的问题
display: inline;
解决 IE9 以下浏览器不能使用 opacity
opacity: 0.5;
filter: alpha(opacity = 50);
filter: progid:DXImageTransform.Microsoft.Alpha(style = 0, opacity = 50);
解决 IE6 不支持 fixed 绝对定位以及IE6下被绝对定位的元素在滚动的时候会闪动的问题
*html, *html body {
background-image: url(about:blank);
background-attachment: fixed;
}
*html #menu {
position: absolute;
top: expression(((e=document.documentElement.scrollTop) ? e : document.body.scrollTop) + 100 + 'px');
}
IE6 背景闪烁的问题
问题:链接、按钮用 CSSsprites 作为背景,在 ie6 下会有背景图闪烁的现象。原因是 IE6 没有将背景图缓存,每次触发 hover 的时候都会重新加载
解决:可以用 JavaScript 设置 ie6 缓存这些图片:
document.execCommand("BackgroundImageCache", false, true);
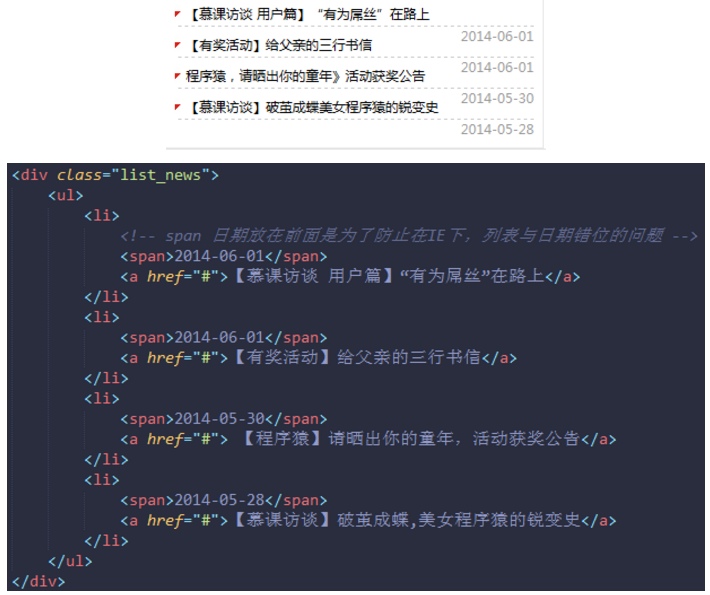
解决在 IE6 下,列表与日期错位的问题
日期<span> 标签放在标题 <a> 标签之前即可
解决 IE6 不支持 min-height 属性的问题min-height: 350px;
_height: 350px;
让 IE7 IE8 支持 CSS3 background-size属性
由于 background-size 是 CSS3 新增的属性,所以 IE 低版本自然就不支持了,但是老外写了一个 htc 文件,名叫
background-size polyfill,使用该文件能够让 IE7、IE8 支持 background-size 属性。其原理是创建一个 img
元素插入到容器中,并重新计算宽度、高度、left、top 等值,模拟 background-size 的效果。
html {
height: 100%;
}
body {
height: 100%;
margin: 0;
padding: 0;
background-image: url('img/37.png');
background-repeat: no-repeat;
background-size: cover;
-ms-behavior: url('css/backgroundsize.min.htc');
behavior: url('css/backgroundsize.min.htc');
}
IE6-7 line-height 失效的问题
问题:在ie 中 img 与文字放一起时,line-height 不起作用
解决:都设置成 float
width:100%
width:100% 这个东西在 ie 里用很方便,会向上逐层搜索 width 值,忽视浮动层的影响.
Firefox 下搜索至浮动层结束,如此,只能给中间的所有浮动层加 width:100%才行,累啊。
opera 这点倒学乖了,跟了 ie
cursor:hand
显示手型 cursor: hand,ie6/7/8、opera 都支持,但是safari 、 ff 不支持
cursor: pointer;
td 自动换行的问题
问题:table 宽度固定,td 自动换行
解决:设置 Table 为 table-layout: fixed,td 为 word-wrap: break-word
键盘事件 keyCode 兼容性写法
var inp = document.getElementById('inp')
var result = document.getElementById('result')
function getKeyCode(e) {
e = e ? e : (window.event ? window.event : "")
return e.keyCode ? e.keyCode : e.which
}
inp.onkeypress = function(e) {
result.innerHTML = getKeyCode(e)
}
求窗口大小的兼容写法
// 浏览器窗口可视区域大小(不包括工具栏和滚动条等边线)
// 1600 * 525
var client_w = document.documentElement.clientWidth || document.body.clientWidth;
var client_h = document.documentElement.clientHeight || document.body.clientHeight;
// 网页内容实际宽高(包括工具栏和滚动条等边线)
// 1600 * 8
var scroll_w = document.documentElement.scrollWidth || document.body.scrollWidth;
var scroll_h = document.documentElement.scrollHeight || document.body.scrollHeight;
// 网页内容实际宽高 (不包括工具栏和滚动条等边线)
// 1600 * 8
var offset_w = document.documentElement.offsetWidth || document.body.offsetWidth;
var offset_h = document.documentElement.offsetHeight || document.body.offsetHeight;
// 滚动的高度
var scroll_Top = document.documentElement.scrollTop||document.body.scrollTop;
DOM 事件处理程序的兼容写法(能力检测)
var eventshiv = {
// event兼容
getEvent: function(event) {
return event ? event : window.event;
},
// type兼容
getType: function(event) {
return event.type;
},
// target兼容
getTarget: function(event) {
return event.target ? event.target : event.srcelem;
},
// 添加事件句柄
addHandler: function(elem, type, listener) {
if (elem.addEventListener) {
elem.addEventListener(type, listener, false);
} else if (elem.attachEvent) {
elem.attachEvent('on' + type, listener);
} else {
// 在这里由于.与'on'字符串不能链接,只能用 []
elem['on' + type] = listener;
}
},
// 移除事件句柄
removeHandler: function(elem, type, listener) {
if (elem.removeEventListener) {
elem.removeEventListener(type, listener, false);
} else if (elem.detachEvent) {
elem.detachEvent('on' + type, listener);
} else {
elem['on' + type] = null;
}
},
// 添加事件代理
addAgent: function (elem, type, agent, listener) {
elem.addEventListener(type, function (e) {
if (e.target.matches(agent)) {
listener.call(e.target, e); // this 指向 e.target
}
});
},
// 取消默认行为
preventDefault: function(event) {
if (event.preventDefault) {
event.preventDefault();
} else {
event.returnValue = false;
}
},
// 阻止事件冒泡
stopPropagation: function(event) {
if (event.stopPropagation) {
event.stopPropagation();
} else {
event.cancelBubble = true;
}
}
};
网站前端性能优化
1.浏览器渲染页面的过程CSS为什么要放到<head>里面、js放到</body>前面,以及js的异步加载(async、defer)等优化。
2.减少HTTP请求
. CSS/JS 合并打包
. 小图标等用iconfont代替
. 使用base64格式的图片:有些小图片,可能色彩比较复杂,这个时候再用iconfont就有点不合适了,此时可以将
其转化为base64格式(不能缓存),直接嵌在src中,比如webpack的url-loader设置limit参数即可
. 减少静态资源的体积
3.减少静态资源的体积
压缩静态资源:合并打包的js、css文件体积一般会比较大,一些图片也会比较大,这个时候必须要压缩处理。前后端
分离项目,不论是gulp还是webpack,都有相应的工具包。针对个别图片,有时候也可以单独拿出来处理,我个人经常
使用这个网站 tinypng.com/ 在线压缩
编写高效率的CSS:因为现在项目里面基本上都在使用CSS预处理器,Less、SaaS、Stylus等等,这导致了某些初级前端的
滥用:嵌套5、6层,甚者能达到7、8层,吓死个人!嵌套这么深,影响浏览器查找选择器的速度不说,这也一定程度上
产出了很多冗余的字节,这个要改、要提醒,一般建议嵌套3层即可。
服务端开启gzip压缩:大招,最近刚知晓,真是太牛逼了,一般的css、js文件能压缩60、70%,当然,这个比率可以设定
的。前后端分离,如果前端部署用node、express作服务器的话,使用中间件compression即可开启gzip压缩:
// server.js
var express = require('express');
var compress = require('compression');
var app = express();
app.use(compress());
4.使用缓存
设置Http Header里面缓存相关的字段,做进一步的优化。
5.脚本加载的优化
<1>动态加载
所谓动态加载脚本就是利用javascript代码来加载脚本,通常是手工创建script元素,然后等到HTML文档解析
完毕后插入到文档中去。这样就可以很好地控制脚本加载的时机,从而避免阻塞问题。
function loadJS(src) {
const script = document.createElement('script');
script.src = src;
document.getElementsByTagName('head')[0].appendChild(script);
}
loadJS('http://example.com/scq000.js');
<2>异步加载
我们都知道,在计算机程序中同步的模式会产生阻塞问题。所以为了解决同步解析脚本会阻塞浏览器渲染的问题,
采用异步加载脚本就成为了一种好的选择。利用脚本的async和defer属性就可以实现这种需求:
<script type="text/javascript" src="https://juejin.im/post/a.js" async></script>
<script type="text/javascript" src="https://juejin.im/post/b.js" defer></script>
虽然利用了这两个属性的script标签都可以实现异步加载,同时不阻塞脚本解析。但是使用async属性的脚本执行
顺序是不能得到保证的。而使用defer属性的脚本执行顺序可以得到保证。另一方面,defer属性是在html文档解
析完成后,DOMContentLoaded事件之前就会执行js。async一旦加载完js后就会马上执行,最迟不超过window.onload
事件。所以,如果脚本没有操作DOM等元素,或者与DOM时候加载完成无关,直接使用async脚本就好。如果需要DOM,
就只能使用defer了。
<3>解决异步加载脚本的问题
上面介绍的异步加载脚本并不是十分完美的。如何处理加载过程中这些脚本的互相依赖关系,就成了实现异步加载
过程中所需要考虑的问题。一方面,对于页面中那些独立的脚本,如用户统计等插件就可以放心大胆地使用异步加载
。而另一方面,对于那些确实需要处理依赖关系的脚本,业界已经有很成熟的解决方案了。如采用AMD规范的RequireJS
,甚至有采用了hack技术(通过欺骗浏览器下载但不执行脚本)的labjs(已过时)。如果你熟悉promise的话,就知道
这是在JS中处理异步的一种强有力的工具。下面以promise技术来实现处理异步脚本加载过程中de的依赖问题:
// 执行脚本
function exec(src) {
const script = document.createElement('script');
script.src = src;
// 返回一个独立的promise
return new Promise((resolve, reject) => {
var done = false;
script.onload = script.onreadystatechange = () => {
if (!done && (!script.readyState || script.readyState === "loaded" || script.readyState === "complete")) {
done = true;
// 避免内存泄漏
script.onload = script.onreadystatechange = null;
resolve(script);
}
}
script.onerror = reject;
document.getElementsByTagName('head')[0].appendChild(script);
});
}
function asyncLoadJS(dependencies) {
return Promise.all(dependencies.map(exec));
}
asyncLoadJS(['https://code.jquery.com/jquery-2.2.1.js', 'https://cdn.bootcss.com/bootstrap/3.3.7/js/bootstrap.min.js']).then(() => console.log('all done'));
可以看到,我们针对每个脚本依赖都会创建一个promise对象来管理其状态。采用动态插入脚本的方式来管理脚本,然后
利用脚本onload和onreadystatechange(兼容性处理)事件来监听脚本是否加载完成。一旦加载完毕,就会触发promise的
resovle方法。最后,针对依赖的处理,是promise的all方法,这个方法只有在所有promise对象都resolved的时候才会触
发resolve方法,这样一来,我们就可以确保在执行回调之前,所有依赖的脚本都已经加载并执行完毕。
<4>懒加载(lazyload)
懒加载是一种按需加载的方式,也通常被称为延迟加载。主要思想是通过延迟相关资源的加载,从而提高页面的加载
和响应速度。在这里主要介绍两种实现懒加载的技术:虚拟代理技术以及惰性初始化技术。
a.虚拟代理加载
所谓虚拟代理加载,即为真正加载的对象事先提供一个代理或者说占位符。最常见的场景是在图片的懒加载中,
先用一种loading的图片占位,然后再用异步的方式加载图片。等真正图片加载完成后就填充进图片节点中去。
// 页面中的图片url事先先存在其data-src属性上
const lazyLoadImg = function() {
const images = document.getElementsByTagName('img');
for(let i = 0; i < images.length; i++) {
if(images[i].getAttribute('data-src')) {
images[i].setAttribute('src', images[i].getAttribute('data-src'));
images[i].onload = () => images[i].removeAttribute('data-src');
}
}
}
b.惰性初始化
惰性初始模式是在程序设计过程中常用的一种设计模式。顾名思义,这个模式就是一种将代码初始化的时机推迟
(特别是那些初始化消耗较大的资源),从而来提升性能的技术。
jQuery中大名鼎鼎的ready方法就用到了这项技术,其目的是为了在页面DOM元素加载完成后就可以做相应的操作,
而不需要等待所有资源加载完毕后。与浏览器中原生的onload事件相比,可以更加提前地介入对DOM的干涉。当
页面中包含大量图片等资源时,这个方法就显出它的好处了。在jQuery内部的实现原理上,它会设置一个标志位
来判断页面是否加载完毕,如果没有加载完成,会将要执行的函数缓存起来。当页面加载完毕后,再一一执行。
这样一来,就将原本应该马上执行的代码,延迟到页面加载完毕后再执行。
6.利用webpack实现脚本加载优化
针对懒加载,webpack也提供了十分友好的支持。这里主要介绍两种方式。
<1 .import()方法
我们知道,在原生es6的语法中,提供了import和export的方式来管理模块。而其import关键字是被设置成静态
的,因此不支持动态绑定。不过在es6的stage3规范中,引入了一个新的方法import()使得动态加载模块成为
可能。所以,你可以在项目中使用这样的代码:
$('#button').click(function() {
import('./dialog.js')
.then(dialog => {
//do something
})
.catch(err => {
console.log('模块加载错误');
});
});
//或者更优雅的写法
$('#button').click(async function() {
const dialog = await import('./dialog.js');
//do something with dialog
});
由于该语法是基于promise的,所以如果需要兼容旧浏览器,请确保在项目中使用es6-promise或者
promise-polyfill。同时,如果使用的是babel,需要添加syntax-dynamic-import插件。
<2 .require.ensure
require.ensure与import()类似,同样也是基于promise的异步加载模块的一种方法。这是在
webpack 1.x时代官方提供的懒加载方案。现在,已经被import()语法取代了。为了文章的完整性,
这里也做一些介绍。
在webpack编译过程中,会静态地解析require.ensure中的模块,并将其添加到一个单独的chunk中,
从而实现代码的按需加载。
语法如下:
require.ensure(dependencies: String[], callback: function(require), errorCallback:
function(error), chunkName: String)
一个十分常见的例子是在写单页面应用的时候,使用该技术实现基于不同路由的按需加载:
const routes = [
{path: '/comment', component: r => require.ensure([], r(require('./Comment')), 'comment')}
];
6.预加载
用户在具体的页面使用过程中的体验也很重要。如果能够通过预判用户的行为,提前加载所需要的资源,则可以快速地
响应用户的操作,从而打造更加良好的用户体验。另一方面,通过提前发起网络请求,也可以减少由于网络过慢导致的
用户等待时间。因此,“预加载”的技术就闪亮登场了。
<1>preload规范
preload 是w3c新出的一个标准。利用link的rel属性来声明相关“proload",从而实现预加载的目的。就像这样:
<link rel="preload" href="https://juejin.im/post/5ee8c5ec5188251fa130f63b/example.js" as="script">
其中rel属性是用来告知浏览器启用preload功能,而as属性是用来明确需要预加载资源的类型,这个资源类型
不仅仅包括js脚本(script),还可以是图片(image),css(style),视频(media)等等。浏览器检测到这个属性
后,就会预先加载资源。
这个规范目前兼容性方面还不是很好,所以可以先稍微了解一下。webpack现在也已经有相关的插件,如果感兴趣
的话,请移步preload-webpack-plugin。
<2>DNS Prefetch 预解析
还有一个可以优化网页速度的方式是利用dns的预解析技术。同preload类似,DNSPrefetch在网络层面上优化了
资源加载的速度。我们知道,针对DNS的前端优化,主要分为减少DNS的请求次数,还有就是进行DNS预先获取。
DNS prefetch就是为了实现这后者。其用法也很简单,只要在link标签上加上对应的属性就行了。
<meta http-equiv="x-dns-prefetch-control" content="on" /> /* 这是用来告知浏览器当前页面要做DNS预解析 */
<link rel="dns-prefetch" href="https://example.com">
前端SEO
为什么要做优化:提高网站的权重,增强搜索引擎友好度,以达到提高排名,增加流量,改善(潜在)用户体验,促进销售的作用。
怎么实现:
1、网站结构布局优化:尽量简单、开门见山,提倡扁平化结构一般而言,建立的网站结构层次越少,越容易被“蜘蛛”抓取,也就容易被收录。一般中小型网站目录结构超过三级
,“蜘蛛”便不愿意往下爬了。并且根据相关数据调查:如果访客经过跳转3次还没找到需要的信息,很可能离开。
因此,三层目录结构也是体验的需要。为此我们需要做到:
(1)控制首页链接数量
网站首页是权重最高的地方,如果首页链接太少,没有“桥”,“蜘蛛”不能继续往下爬到内页,直接影响网站收录
数量。但是首页链接也不能太多,一旦太多,没有实质性的链接,很容易影响用户体验,也会降低网站首页的权
重,收录效果也不好。
(2)扁平化的目录层次
尽量让“蜘蛛”只要跳转3次,就能到达网站内的任何一个内页
(3)导航优化
导航应该尽量采用文字方式,也可以搭配图片导航,但是图片代码一定要进行优化,<img>标签必须添加“alt”
和“title”属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字。其次,在
每一个网页上应该加上面包屑导航,好处:从用户体验方面来说,可以让用户了解当前所处的位置以及当前页面
在整个网站中的位置,帮助用户很快了解网站组织形式,从而形成更好的位置感,同时提供了返回各个页面的接
口,方便用户操作;对“蜘蛛”而言,能够清楚的了解网站结构,同时还增加了大量的内部链接,方便抓取,降低
跳出率。
(4)网站的结构布局---不可忽略的细节
页面头部:logo及主导航,以及用户的信息。
页面主体:左边正文,包括面包屑导航及正文;右边放热门文章及相关文章,好处:留住访客,让访客多停留,
对“蜘蛛”而言,这些文章属于相关链接,增强了页面相关性,也能增强页面的权重。
页面底部:版权信息和友情链接。
(5)利用布局,把重要内容HTML代码放在最前
搜索引擎抓取HTML内容是从上到下,利用这一特点,可以让主要代码优先读取,广告等不重要代码放在下边。
(6)控制页面的大小,减少http请求,提高网站的加载速度。
一个页面最好不要超过100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,留不住访客,并且一旦
超时,“蜘蛛”也会离开。
2、网页代码优化
(1)突出重要内容---合理的设计title、description和keywords
<title>标题:只强调重点即可,尽量把重要的关键词放在前面,关键词不要重复出现,尽量做到每个页面的
<title>标题中不要设置相同的内容。
<meta keywords>标签:关键词,列举出几个页面的重要关键字即可,切记过分堆砌。
<meta description>标签:网页描述,需要高度概括网页内容,切记不能太长,过分堆砌关键词,每个页面也要有所不同。
(2)语义化书写HTML代码,符合W3C标准
尽量让代码语义化,在适当的位置使用适当的标签,用正确的标签做正确的事。让阅读源码者和“蜘蛛”都一目了然。
比如:h1-h6 是用于标题类的,<nav>标签是用来设置页面主导航,列表形式的代码使用ul或ol,重要的文字使用
span等。
(3)<a>标签:页内链接,要加 “t知道。而外部链接,链接到其他网站的,则需要加上 el="nofollow" 属性,
告诉 “蜘蛛” 不要爬,因为一旦“蜘蛛”爬了外部链接之后,就不会再回来了。
<a href="https://www.360.cn" title="360安全中心" class="logo"></a>
(4)正文标题要用<h1>标签:h1标签自带权重“蜘蛛” 认为它最重要,一个页面有且最多只能有一个H1标签,放在该页面最重要的标题上面,如首页的logo上可以加H1标签。
副标题用<h2>标签, 而其它地方不应该随便乱用 h 标题标签。
(5)<img>应使用 "alt" 属性加以说明
<img src="https://juejin.im/post/5ee8c5ec5188251fa130f63b/cat.jpg" width="300" height="200" alt="猫" />
(6)表格应该使用<caption>表格标题标签
caption 元素定义表格标题。caption 标签必须紧随 table 标签之后,您只能对每个表格定义一<table border='1'>
<caption>表格标题</caption>
<tbody>
<tr>
<td>apple</td>
<td>100</td>
</tr>
<tr>
<td>banana</td>
<td>200</td>
</tr>
</tbody>
</table>
(7)<br>标签:只用于文本内容的换行,比如:
<p>
第一行文字内容<br/>
第二行文字内容<br/>
第三行文字内容
</p>
(8)重要内容不要用JS输出,因为“蜘蛛”不会读取JS里的内容,所以重要内容必须放在HTML里。
(9)尽量少使用iframe框架,因为“蜘蛛”一般不会读取其中的内容。
(10)谨慎使用 display:none :对于不想显示的文字内容,应当设置z-index或缩进设置成足够大的负数偏离出浏览器之外。因为搜索引擎会过滤掉display:none其中的内容。
3、前端网站性能优化
(1)减少http请求数量
a.CSS Sprites
国内俗称CSS精灵,这是将多张图片合并成一张图片达到减少HTTP请求的一种解决方案,可以通过CSS的
background属性来访问图片内容。这种方案同时还可以减少图片总字节数。
b.合并CSS和JS文件
现在前端有很多工程化打包工具,如:grunt、gulp、webpack等。为了减少 HTTP
请求数量,可以通过这些工具再发布前将多个CSS或者多个JS合并成一个文件。
c.采用lazyload
称懒加载,可以控制网页上的内容在一开始无需加载,不需要发请求,等到用户操作真正需要的时候立即加载
出内容。这样就控制了网页资源一次性请求数量。
(2)控制资源文件加载优先级
浏览器在加载HTML内容时,是将HTML内容从上至下依次解析,解析到link或者script标签就会加载href或者src对应
链接内容,为了第一时间展示页面给用户,就需要将CSS提前加载,不要受 JS 加载影响。
(3)尽量外链CSS和JS(结构、表现和行为的分离),保证网页代码的整洁,也有利于日后维护
<link rel="stylesheet" href="https://juejin.im/post/5ee8c5ec5188251fa130f63b/asstes/css/style.css" />
<script src="https://juejin.im/post/5ee8c5ec5188251fa130f63b/assets/js/main.js"></script>
(4)利用浏览器缓存
浏览器缓存是将网络资源存储在本地,等待下次请求该资源时,如果资源已经存在就不需要到服务器重新请求该资源,
直接在本地读取该资源。
(5)减少重排(Reflow)
基本原理:重排是DOM的变化影响到了元素的几何属性(宽和高),浏览器会重新计算元素的几何属性,会使渲染树
中受到影响的部分失效,浏览器会验证DOM树上的所有其它结点的visibility属性,这也是Reflow低效的原因。如果
Reflow的过于频繁,CPU使用率就会急剧上升。
减少Reflow,如果需要在DOM操作时添加样式,尽量使用 增加class属性,而不是通过style操作样式。
(6)减少 DOM 操作
(7)图标使用IconFont替换
(8)不使用CSS表达式,会影响效率
(9)使用CDN网络缓存,加快用户访问速度,减轻服务器压力
(10)启用GZIP压缩,浏览速度变快,搜索引擎的蜘蛛抓取信息量也会增大
(11)伪静态设置
如果是动态网页,可以开启伪静态功能,让蜘蛛“误以为”这是静态网页,因为静态网页比较合蜘蛛的胃口,如果url中带有关键词效果更好。
动态地址:http://www.360.cn/index.php
伪静态地址:http://www.360.cn/index.html
正确认识SEO,不过分SEO,网站还是以内容为主。
http协议
前端组件化、工程化、模块化开发
面向对象编程
以上是 前端需要掌握的进阶知识(浏览器运行机制/前端优化/http/前端工程化模块化等) 的全部内容, 来源链接: utcz.com/a/25238.html