第九期|前端自研文档显示有多难
前言

本期的前端早早聊主要讲师是灼翎(菜鸟)、叶斋(钉钉)、本杰(钉钉)、遇春(语雀),在web文档领域有着自己的研究与见解,因此下面和我一起来了解一下这次的前端早早聊说了些什么吧。
前置知识
什么是同构表,异构表
简单来说,异构表就是用来排版的,例如下表列出来的内容;而同构表主要关注的是对数据的展示、处理。
| 同构表 | 异构表 |
|---|---|
| 严格行列组织 | 字体字号设置 |
| 增删行 | 左右垂直对齐居中 |
| 增删列 | 边框样式 |
| 定义列类型 | 合并单元格 |
| 筛选 | 背景色 |
| 排序 | 非严格行列 |
| 分组 | |
| 聚合 | |
| 联合 |
OP(Operation)
OT(Operation Transform)
遇春(语雀)-- 异构表
一、为什么要做电子表格(改进?自研?)
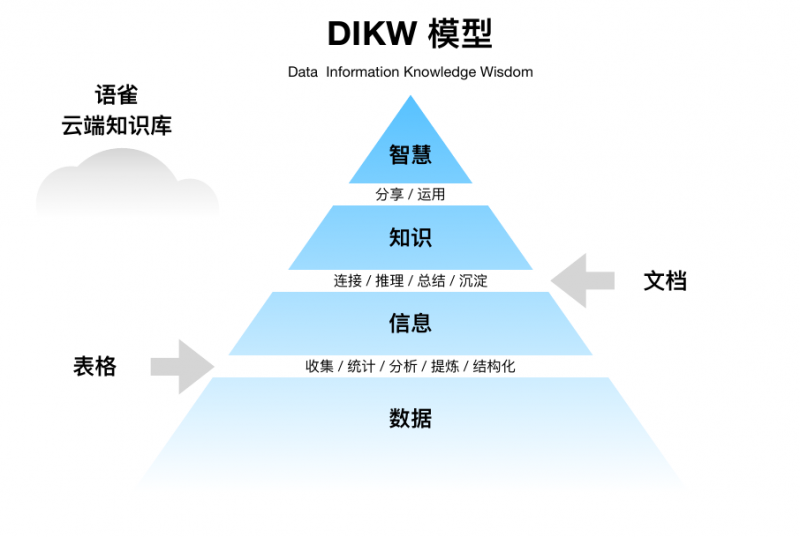
为什么要做云端知识库
什么是知识?现在的领域被分为了数据层、信息层、知识层和智慧层。数据层是大量的海量的数据;经过收集、分析、提炼之后就会成为有用的信息;然后信息与信息之间结合之后,信息就会升华更重要的知识;知识被运用之后,则会沉淀为自己的智慧。
- 为什么要选择自研
对于业务的需求当前的选型无法满足,因此需要对技术进行改进,或者向自研的方向发展
生活中的99%的产品都值得重新被创造一遍
自研前的考量:
可靠性
扩展性
成本效率
自研中的考量:
体验——切换身份至用户方向
模型——模型要被自己所掌握
业务——技术一定是服务业务的
维护
研发
性能——性能调优到覆盖大部分用户
二、怎么自研
语雀对于技术选型的考量

MVC 架构:
View
表格数据渲染
工具栏、相关面板
收集event
Model
Command操纵Model,Model体现在View上
Control
处理event --> Command
如何进行模型设计、选型
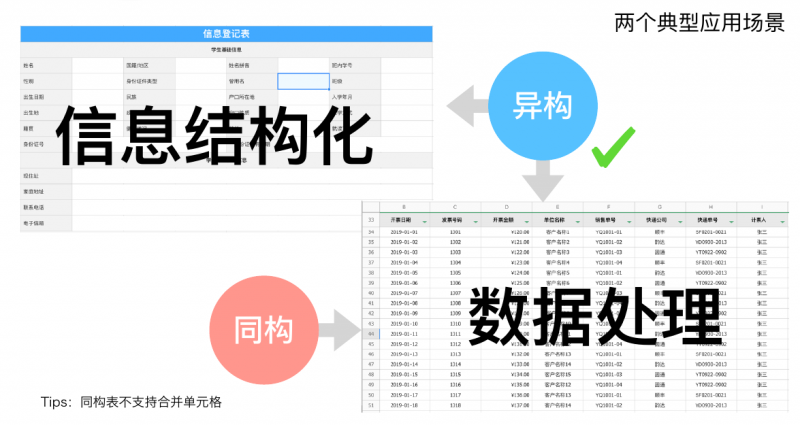
技术选型的考量(最终选择了异构):
同构(重数据):数据处理,着重于表现数据
异构(重排版):信息结构化,合并单元格
如何实现多人协同
多人协作时如何解决冲突问题?
- 可以使用时间辍来标记次序。
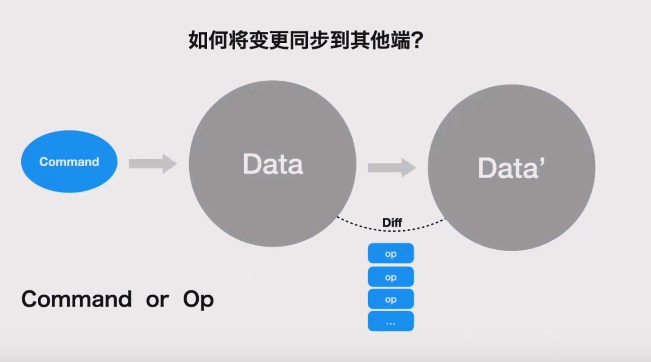
同步OP:一致性好,但是量大时性能有问题,OP越多延迟越多,延迟越多OP越多,会形成不可收拾的循环。
同步Command:是粗颗粒的操作。性能好,一致性不完备。

要支持多少单元格
首先进行技术考量:
- 竞品的支持程度:
- Lark Docs 50万单元格
- 腾讯文档 20万单元格
- google docs 500万单元格
浏览器的限制:
- localstorage的上限为5M
假设一个单元格可以存储20~200个字符,则可以存储1000~10000行x25列
如何突破限制:
对数据进行压缩。对于数据压缩现在有非常多的方案,对于语雀,是这样做的:
- 将Array映射成Map。对于稀疏数列存储会浪费大量的空间,使用Map来映射可以极大的节省空间。
- KV index压缩。将key索引化,例如大量的key都是一个值,则可以将key压缩,节省空间。
- 压缩。使用gzip压缩。
最后效果:压缩至10-20倍,语雀支持250万单元格。
复制粘贴破损修复
如果是正常格式的表格复制,则对于市面上的web表格都没有问题,但是如果表格有特殊的格式,需要对格式进行特殊的解析。例如:缺头、缺尾、缺腰。
需要对每种不同的复制结果进行深刻的实践,最终才能覆盖到所有情况。
以及
- 多种附件在线预览
- 像素级滚动(虚拟滚动)
- 导入导出
- 单元格保护
- 读写分离
- 重要的条件格式
- 公式
- 可以多选的下拉选项
- 容易操作的图表
灼翎(菜鸟)-- 同构表
一、为什么要做电子表格(改进?自研?)
- 不同的部门沟通、分析数据,需要先从报表系统之中拉去数据
- 需要把报表导出,然后汇报给领导
- ......
没有一个可以方便的人机交互的报表系统,这些功能都是及其让人头痛的。而且还带来了许多问题,例如:
- 人与人之间的沟通效率问题
- 人与人之间数据协同管理问题
- 数据与业务平台协同问题
传统的报表生产流程:
- 首先前端后端约定接口,确定API。
- 前端写静态页面、接口调用。
- 后端写SQL,包装一个专门的接口,注册到网关。
- 前后端联调,然后发布上线
这时我们发现了一个问题:
无论是简单的报表还是复杂的报表,我们的工程师都需要遵循上面的流程才可以展现一张报表出来。在这个基础上,才可以做一些更高阶的功能,例如可视化等等。所有的这些事情都是有规律的,而又繁琐的。而做一张报表又需要花费很多的时间。作为有时效性的报表,等待的时间越久,他的作用也就越少。因此,开发出一个简洁而又高效的报表系统则刻不容缓。
电子表格:
所有的数据可以轻松的在线编辑,分享也变得更加简单,只需要将权限给到,然后分享链接就可以了。
数据提取变得更加简单,可以直接在web中生成数据分析表,也可以导出在本地电脑打开,大大地节省了开发时间。
二、如何研发
研发目标:沟通即协作,协作即创作
技术选型(同构表?异构表?)
菜鸟的选择是同构表,目的:
- 解决线下业务数据快速线上化
- 解决业务数据管理以及线下数据对接业务平台
技术接入
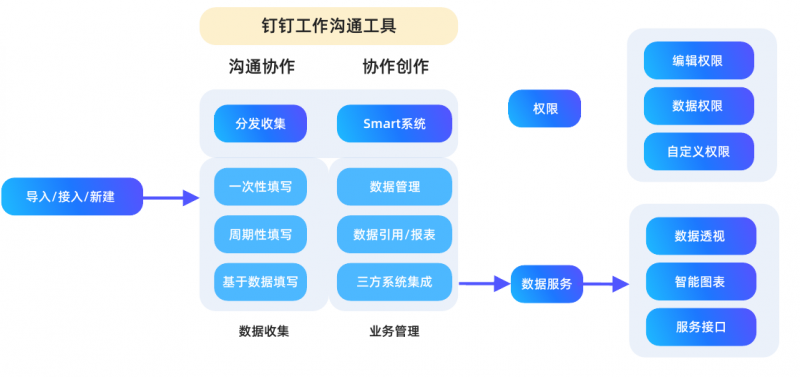
与钉钉接入,通过与钉钉的集成,使沟通协作,协作创作。
总结
解决的问题:
- 代码研发
- 重复劳动
- 无人维护
创新:
无代码或低代码产品
将操作尽可能的图形化、形象化,降低使用难度
- 无代码workflow
- 跨端操作
- 多维度数据分析
- 架构与权限控制
智能机器人ROBOT
依靠与钉钉的连通服务,可以用钉钉机器人实现下列功能
- 简单易学
- 打通通知
- 账号安全
- 交互简洁
连通业务服务
提供多种服务接口,快速对接各种业务,不再存在数据孤岛。
叶斋(钉钉)-- 同构表
钉钉的整体架构
开发指南
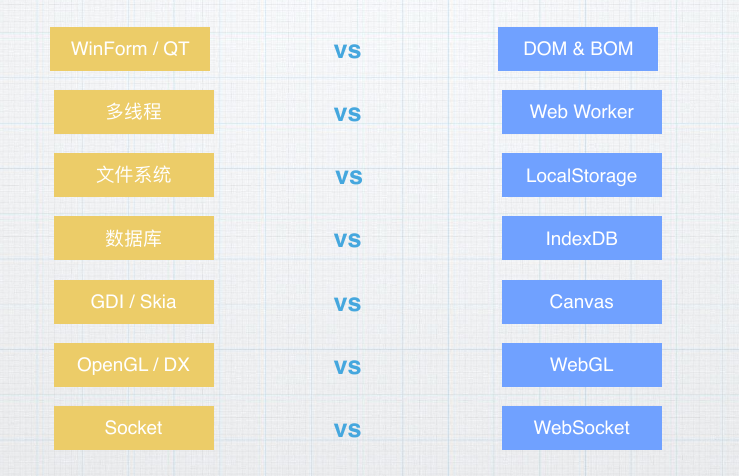
桌面端技术非常的成熟,因此可以在技术上,架构上借鉴桌面端的技术。
性能优化
问题:
数据量大
一个同构表支持大至十万行的数据,如果同时把他们渲染出来,则需要上百万个div,是一个很大的性能开销;
解决方案:
虚拟滚动
使用
javascript来控制元素、维护滚动偏移量。目前github也有很多的开源框架,是选择自己自研还是现有方案,需要团队做技术调研。使用Worker来计算
众所周知,javascript是单线程的,如果将所有的计算code写在UI层,就会造成页面的卡死。使用Worker可以将其独立出来,但是里面有大量的坑需要踩踩。
数据切片
请求数据的时候不是请求所有的数据,而是只请求在一个range内的数据,避免与Worker传输大量数据,造成性能问题。
用户体验提升
- 从选中到编辑,以及敏感的键盘响应
- 对于中文输入法在表格中的使用体验
- 移动设备键盘弹起之后对页面的影响
要是想让用户体验提升,就要让用户的体验尽可能的贴近桌面端的使用,例如基础的,对上下左右箭头的响应,对于tab,enter按键的监听;进阶的对于一些冷门API的使用;对于不同的浏览器平台和使用设备,都需要做不同的适配。
问题解答:
使用React吗?
react没有经历过复杂文档应用的考验,对于优化有许多的坑,因此react虽然目前大热,但是不是银弹,要根据现况来进行技术选型。
表格选择dom还是canvas?
选择:同构表选择dom;异构表选择canvas。
解释:同构表与异构表相比没有这么复杂的操作,而且比较规范,所以选择dom比较简单方便。而异构表每个单元格都可以有自己的样式,所以用canvas来开发简单一点。
本杰(钉钉)-- 编辑器的前行之路
文字编辑器的发展
打字机时代
文本编辑器时代
富文本编辑器时代
web编辑器时代
所见即所得(WYSIWYG)
- DOM内容 <-> 可视化内容
- DOM选区 <-> 可视化选区
- 所有的可视化编辑都可以映射到一个代数上来说封闭和完整的可视化内容集合上
怎么做?
- 一个文档模型,并且能够确保2个模型在视觉上相等
- 一种映射关系,DOM和文档模型的映射
- 基于文档模型的良好编辑操作指令
- 可以将DOM的事件转化为编辑操作
不只一个编辑器
打造一个编辑器不仅要做好表面的一些东西,例如基本格式的支持(加粗、斜体、字体、字号、代码快、列表),以及交互上的附件传输,图文排版,超链接等等;也有交互上的复制、粘贴,以及复制粘贴时格式的管理;更有底层更复杂的内存模型,多人交互。
笔墨纸砚
钉钉把文档编辑器分为笔墨纸砚四个部分:
笔:
- 用户界面
- 事件处理
墨:
- 数据的转化
纸:
- 富文本
- 富交互
- 业务扩展
砚:
- 数据序列化
- 反序列化算法
- 操作变换算法(diff)
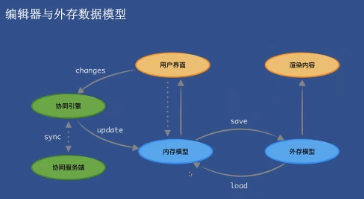
运行时编辑器与多人实时编辑
内存模型非常重要,数据的操纵都是作用于内存模型,然后表现在View上的。
编辑器与外存数据模型
最后打一个前端早早聊 的广告
前端早早聊大会目标成为用得上、听得懂、抄得走的技术大会,计划 2020 年办 >= 15 期,由前端早早聊与 掘金联合举办,前端早早聊大会行程动态、录播视频/PPT/讲稿资料下载请关注 「前端早早聊」 公众号跟进。
6 月 20 日举办第十届 - 前端跨域跨栈,报名请戳 ,海报及讲师行程如下:

6 月 27 日举办第十一届 - 前端跳槽的新攻略,报名请戳 ,海报及讲师行程如下:

读完了
如果大家觉得文章写的还不错,就为我点一下赞吧。移动端在最下面,PC端在文章左边。比心💖💖。
以上是 第九期|前端自研文档显示有多难 的全部内容, 来源链接: utcz.com/a/24544.html