求教关于js内存释放的问题。
最近在写一个chrome插件
有一个简单的功能分2步是这样:
- 从站点提取链接遍历所有详情页面(目前2000+ 每天几十个递增),提取关键数据生成数组对象。
- 从生成数组对象判断是否有
other_href字段,如果有的话,请求这个other_href解析返回的html获得需要的数据,保存在对象上。
上面2步的请求都是用axios.get,请求拿到的result.data只进入一个解析函数返回解析对象,没有他用。
现在遇到的问题是第二步的other_href是从第一步的result.data解析出来,可能是这个原因导致第一步请求回来的html不能从内存中释放,只开1000多个页面插件就因为内存溢出崩溃了。
打开内存快照里面堆满了<!DOCTYPE html> ...,我测试过如果不对这个other_href进行处理,内存会自动释放维持在300M左右。
我的解析函数只是对字符串进行截取处理
function parseDetailsHtml(html) {function getOthersHref(htm) {
const index = htm.indexOf('name="description"'),
lastIndex = htm.indexOf('<', index),
match = (htm.substring(index, lastIndex + 1) || '').match(/>(.+?)</) || [];
return (match[1] || '').trim();
}
//... 其他提取函数
return {
others_href: getOthersHref(html),
...// 同getOthersHref的[字段名]:[函数名](html)
};
}
难道这样也能产生引用造成不能释放吗?
现在完全搞不懂应该怎么做了。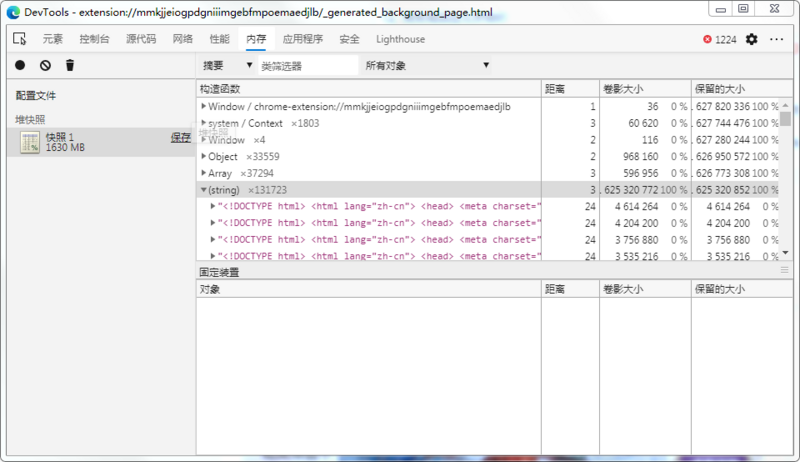
回答
还真有可能是返回的字符串在底层对原字符串进行了引用导致未被 GC。参见这篇文章 奇技淫巧学 V8 之六,字符串在 V8 内的表达,文中提到,对原 string 进行 substring/slice 底层依然会保留完整的原字符串在堆上的。
就这个问题有一个办法可以规避,用 String.fromCharCode(str.charCodeAt(i)) 转成每个字符的 unicode 再转回去。
function getOthersHref(htm) { const index = htm.indexOf('name="description"'),
lastIndex = htm.indexOf('<', index),
match = (htm.substring(index, lastIndex + 1) || '').match(/>(.+?)</) || [];
return cloneStr((match[1] || '').trim());
}
function cloneStr(str) {
let copied = '';
for(let i=0; i<str.length; i++) {
copied += String.fromCharCode(str.charCodeAt(i));
}
return copied;
}
还好你的 href 也不会很长,这样并不会影响性能。
以上是 求教关于js内存释放的问题。 的全部内容, 来源链接: utcz.com/a/23898.html