一文搞懂Java8的Lambda、函数式接口、Stream用法及原理
就在今年 Java 25周岁了,可能比在座的各位中的一些少年年龄还大,但令人遗憾的是,竟然没有我大,不禁感叹,Java 还是太小了。(难道我会说是因为我老了?)

而就在上个月,Java 15 的试验版悄悄发布了,但是在 Java 界一直有个神秘现象,那就是「你发你发任你发,我的最爱 Java 8」.
据 Snyk 和 The Java Magazine 联合推出发布的 2020 JVM 生态调查报告显示,在所有的 Java 版本中,仍然有 64% 的开发者使用 Java 8。另外一些开发者可能已经开始用 Java 9、Java 11、Java 13 了,当然还有一些神仙开发者还在坚持使用 JDK 1.6 和 1.7。
尽管 Java 8 发布多年,使用者众多,可神奇的是竟然有很多同学没有用过 Java 8 的新特性,比如 Lambda表达式、比如方法引用,再比如今天要说的 Stream。其实 Stream 就是以 Lambda 和方法引用为基础,封装的简单易用、函数式风格的 API。
Java 8 是在 2014 年发布的,实话说,风筝我也是在 Java 8 发布后很长一段时间才用的 Stream,因为 Java 8 发布的时候我还在 C# 的世界中挣扎,而使用 Lambda 表达式却很早了,因为 Python 中用 Lambda 很方便,没错,我写 Python 的时间要比 Java 的时间还长。

要讲 Stream ,那就不得不先说一下它的左膀右臂 Lambda 和方法引用,你用的 Stream API 其实就是函数式的编程风格,其中的「函数」就是方法引用,「式」就是 Lambda 表达式。
Lambda 表达式
Lambda 表达式是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象,是一个匿名函数,即没有函数名的函数。Lambda表达式可以表示闭包。
在 Java 中,Lambda 表达式的格式是像下面这样
// 无参数,无返回值() -> log.info("Lambda")
// 有参数,有返回值
(int a, int b) -> { a+b }
其等价于
log.info("Lambda");private int plus(int a, int b){
return a+b;
}
最常见的一个例子就是新建线程,有时候为了省事,会用下面的方法创建并启动一个线程,这是匿名内部类的写法,new Thread需要一个 implements 自Runnable类型的对象实例作为参数,比较好的方式是创建一个新类,这个类 implements Runnable,然后 new 出这个新类的实例作为参数传给 Thread。而匿名内部类不用找对象接收,直接当做参数。
new Thread(new Runnable() {@Override
public void run() {
System.out.println("快速新建并启动一个线程");
}
}).run();
但是这样写是不是感觉看上去很乱、很土,而这时候,换上 Lambda 表达式就是另外一种感觉了。
new Thread(()->{System.out.println("快速新建并启动一个线程");
}).run();
怎么样,这样一改,瞬间感觉清新脱俗了不少,简洁优雅了不少。
Lambda 表达式简化了匿名内部类的形式,可以达到同样的效果,但是 Lambda 要优雅的多。虽然最终达到的目的是一样的,但其实内部的实现原理却不相同。
匿名内部类在编译之后会创建一个新的匿名内部类出来,而 Lambda 是调用 JVM invokedynamic指令实现的,并不会产生新类。
方法引用
方法引用的出现,使得我们可以将一个方法赋给一个变量或者作为参数传递给另外一个方法。::双冒号作为方法引用的符号,比如下面这两行语句,引用 Integer类的 parseInt方法。
Function<String, Integer> s = Integer::parseInt;Integer i = s.apply("10");
或者下面这两行,引用 Integer类的 compare方法。
Comparator<Integer> comparator = Integer::compare;int result = comparator.compare(100,10);
再比如,下面这两行代码,同样是引用 Integer类的 compare方法,但是返回类型却不一样,但却都能正常执行,并正确返回。
IntBinaryOperator intBinaryOperator = Integer::compare;int result = intBinaryOperator.applyAsInt(10,100);
相信有的同学看到这里恐怕是下面这个状态,完全不可理喻吗,也太随便了吧,返回给谁都能接盘。

先别激动,来来来,现在咱们就来解惑,解除蒙圈脸。
Q:什么样的方法可以被引用?
A:这么说吧,任何你有办法访问到的方法都可以被引用。
Q:返回值到底是什么类型?
A:这就问到点儿上了,上面又是 Function、又是Comparator、又是 IntBinaryOperator的,看上去好像没有规律,其实不然。
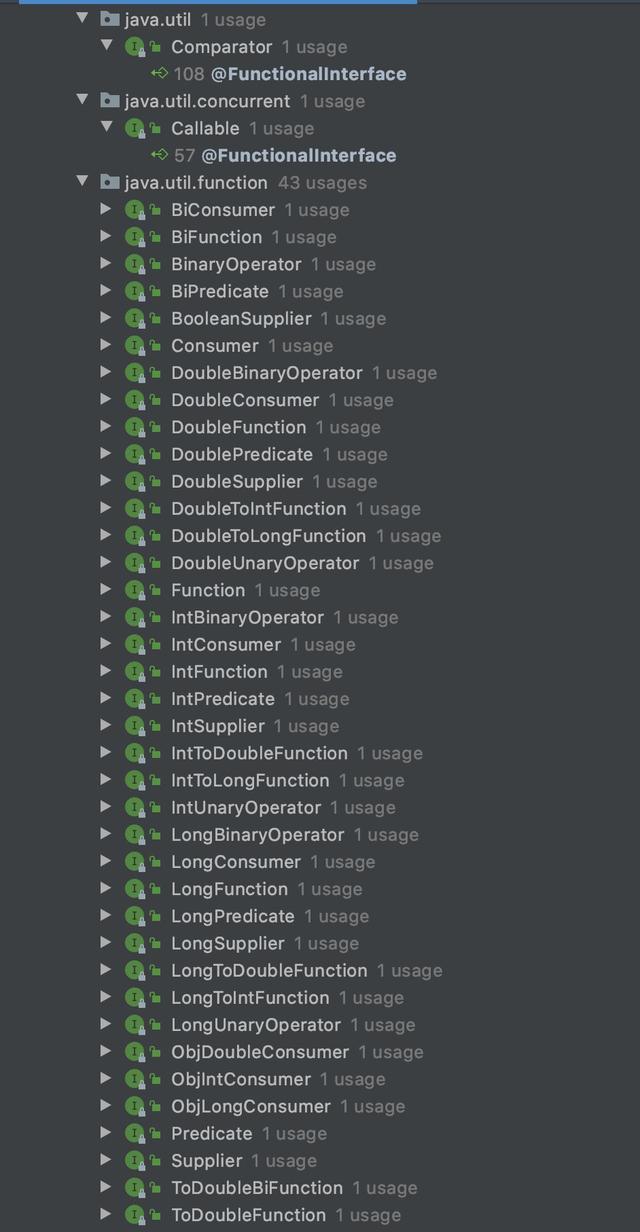
返回的类型是 Java 8 专门定义的函数式接口,这类接口用 @FunctionalInterface 注解。
比如 Function这个函数式接口的定义如下:
@FunctionalInterfacepublic interface Function<T, R> {
R apply(T t);
}
还有很关键的一点,你的引用方法的参数个数、类型,返回值类型要和函数式接口中的方法声明一一对应才行。
比如 Integer.parseInt方法定义如下:
public static int parseInt(String s) throws NumberFormatException {return parseInt(s,10);
}
首先parseInt方法的参数个数是 1 个,而 Function中的 apply方法参数个数也是 1 个,参数个数对应上了,再来,apply方法的参数类型和返回类型是泛型类型,所以肯定能和 parseInt方法对应上。
这样一来,就可以正确的接收Integer::parseInt的方法引用,并可以调用Funciton的apply方法,这时候,调用到的其实就是对应的 Integer.parseInt方法了。
用这套标准套到 Integer::compare方法上,就不难理解为什么即可以用 Comparator<Integer>接收,又可以用 IntBinaryOperator接收了,而且调用它们各自的方法都能正确的返回结果。
Integer.compare方法定义如下:
public static int compare(int x, int y) {return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
返回值类型 int,两个参数,并且参数类型都是 int。
然后来看Comparator和IntBinaryOperator它们两个的函数式接口定义和其中对应的方法:
@FunctionalInterfacepublic interface Comparator<T> {
int compare(T o1, T o2);
}
@FunctionalInterface
public interface IntBinaryOperator {
int applyAsInt(int left, int right);
}
对不对,都能正确的匹配上,所以前面示例中用这两个函数式接口都能正常接收。其实不止这两个,只要是在某个函数式接口中声明了这样的方法:两个参数,参数类型是 int或者泛型,并且返回值是 int或者泛型的,都可以完美接收。
JDK 中定义了很多函数式接口,主要在 java.util.function包下,还有 java.util.Comparator 专门用作定制比较器。另外,前面说的 Runnable也是一个函数式接口。
自己动手实现一个例子
1. 定义一个函数式接口,并添加一个方法
定义了名称为 KiteFunction 的函数式接口,使用 @FunctionalInterface注解,然后声明了具有两个参数的方法 run,都是泛型类型,返回结果也是泛型。
还有一点很重要,函数式接口中只能声明一个可被实现的方法,你不能声明了一个 run方法,又声明一个 start方法,到时候编译器就不知道用哪个接收了。而用default 关键字修饰的方法则没有影响。
@FunctionalInterfacepublic interface KiteFunction<T, R, S> {
/**
* 定义一个双参数的方法
* @param t
* @param s
* @return
*/
R run(T t,S s);
}
2. 定义一个与 KiteFunction 中 run 方法对应的方法
在 FunctionTest 类中定义了方法 DateFormat,一个将 LocalDateTime类型格式化为字符串类型的方法。
public class FunctionTest {public static String DateFormat(LocalDateTime dateTime, String partten) {
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(partten);
return dateTime.format(dateTimeFormatter);
}
}
3.用方法引用的方式调用
正常情况下我们直接使用 FunctionTest.DateFormat()就可以了。
而用函数式方式,是这样的。
KiteFunction<LocalDateTime,String,String> functionDateFormat = FunctionTest::DateFormat;String dateString = functionDateFormat.run(LocalDateTime.now(),"yyyy-MM-dd HH:mm:ss");
而其实我可以不专门在外面定义 DateFormat这个方法,而是像下面这样,使用匿名内部类。
public static void main(String[] args) throws Exception {String dateString = new KiteFunction<LocalDateTime, String, String>() {
@Override
public String run(LocalDateTime localDateTime, String s) {
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(s);
returnlocalDateTime.format(dateTimeFormatter);
}
}.run(LocalDateTime.now(), "yyyy-MM-dd HH:mm:ss");
System.out.println(dateString);
}
前面第一个 Runnable的例子也提到了,这样的匿名内部类可以用 Lambda 表达式的形式简写,简写后的代码如下:
public static void main(String[] args) throws Exception {KiteFunction<LocalDateTime, String, String> functionDateFormat = (LocalDateTime dateTime, String partten) -> {
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(partten);
return dateTime.format(dateTimeFormatter);
};
String dateString = functionDateFormat.run(LocalDateTime.now(), "yyyy-MM-dd HH:mm:ss");
System.out.println(dateString);
}
使用(LocalDateTime dateTime, String partten) -> { } 这样的 Lambda 表达式直接返回方法引用。
Stream API
为了说一下 Stream API 的使用,可以说是大费周章啊,知其然,也要知其所以然吗,追求技术的态度和姿势要正确。
当然 Stream 也不只是 Lambda 表达式就厉害了,真正厉害的还是它的功能,Stream 是 Java 8 中集合数据处理的利器,很多本来复杂、需要写很多代码的方法,比如过滤、分组等操作,往往使用 Stream 就可以在一行代码搞定,当然也因为 Stream 都是链式操作,一行代码可能会调用好几个方法。
Collection接口提供了 stream()方法,让我们可以在一个集合方便的使用 Stream API 来进行各种操作。值得注意的是,我们执行的任何操作都不会对源集合造成影响,你可以同时在一个集合上提取出多个 stream 进行操作。
我们看 Stream 接口的定义,继承自 BaseStream,机会所有的接口声明都是接收方法引用类型的参数,比如 filter方法,接收了一个 Predicate类型的参数,它就是一个函数式接口,常用来作为条件比较、筛选、过滤用,JPA中也使用了这个函数式接口用来做查询条件拼接。
public interface Stream<T> extends BaseStream<T, Stream<T>> {Stream<T> filter(Predicate<? super T> predicate);
// 其他接口
}
下面就来看看 Stream 常用 API。
of
可接收一个泛型对象或可变成泛型集合,构造一个 Stream 对象。
private static void createStream(){Stream<String> stringStream = Stream.of("a","b","c");
}
empty
创建一个空的 Stream 对象。
concat
连接两个 Stream ,不改变其中任何一个 Steam 对象,返回一个新的 Stream 对象。
private static void concatStream(){Stream<String> a = Stream.of("a","b","c");
Stream<String> b = Stream.of("d","e");
Stream<String> c = Stream.concat(a,b);
}
max
一般用于求数字集合中的最大值,或者按实体中数字类型的属性比较,拥有最大值的那个实体。它接收一个 Comparator<T>,上面也举到这个例子了,它是一个函数式接口类型,专门用作定义两个对象之间的比较,例如下面这个方法使用了 Integer::compareTo这个方法引用。
private static void max(){Stream<Integer> integerStream = Stream.of(2, 2, 100, 5);
Integer max = integerStream.max(Integer::compareTo).get();
System.out.println(max);
}
当然,我们也可以自己定制一个 Comparator,顺便复习一下 Lambda 表达式形式的方法引用。
private static void max(){Stream<Integer> integerStream = Stream.of(2, 2, 100, 5);
Comparator<Integer> comparator = (x, y) -> (x.intValue() < y.intValue()) ? -1 : ((x.equals(y)) ? 0 : 1);
Integer max = integerStream.max(comparator).get();
System.out.println(max);
}
min
与 max 用法一样,只不过是求最小值。
findFirst
获取 Stream 中的第一个元素。
findAny
获取 Stream 中的某个元素,如果是串行情况下,一般都会返回第一个元素,并行情况下就不一定了。
count
返回元素个数。
Stream<String> a = Stream.of("a", "b", "c");long x = a.count();
peek
建立一个通道,在这个通道中对 Stream 的每个元素执行对应的操作,对应 Consumer<T>的函数式接口,这是一个消费者函数式接口,顾名思义,它是用来消费 Stream 元素的,比如下面这个方法,把每个元素转换成对应的大写字母并输出。
private static void peek() {Stream<String> a = Stream.of("a", "b", "c");
List<String> list = a.peek(e->System.out.println(e.toUpperCase())).collect(Collectors.toList());
}
forEach
和 peek 方法类似,都接收一个消费者函数式接口,可以对每个元素进行对应的操作,但是和 peek 不同的是,forEach 执行之后,这个 Stream 就真的被消费掉了,之后这个 Stream 流就没有了,不可以再对它进行后续操作了,而 peek操作完之后,还是一个可操作的 Stream 对象。
正好借着这个说一下,我们在使用 Stream API 的时候,都是一串链式操作,这是因为很多方法,比如接下来要说到的 filter方法等,返回值还是这个 Stream 类型的,也就是被当前方法处理过的 Stream 对象,所以 Stream API 仍然可以使用。
private static void forEach() {Stream<String> a = Stream.of("a", "b", "c");
a.forEach(e->System.out.println(e.toUpperCase()));
}
forEachOrdered
功能与 forEach是一样的,不同的是,forEachOrdered是有顺序保证的,也就是对 Stream 中元素按插入时的顺序进行消费。为什么这么说呢,当开启并行的时候,forEach和 forEachOrdered的效果就不一样了。
Stream<String> a = Stream.of("a", "b", "c");a.parallel().forEach(e->System.out.println(e.toUpperCase()));
当使用上面的代码时,输出的结果可能是 B、A、C 或者 A、C、B或者A、B、C,而使用下面的代码,则每次都是 A、 B、C
Stream<String> a = Stream.of("a", "b", "c");a.parallel().forEachOrdered(e->System.out.println(e.toUpperCase()));
limit
获取前 n 条数据,类似于 MySQL 的limit,只不过只能接收一个参数,就是数据条数。
private static void limit() {Stream<String> a = Stream.of("a", "b", "c");
a.limit(2).forEach(e->System.out.println(e));
}
上述代码打印的结果是 a、b。
skip
跳过前 n 条数据,例如下面代码,返回结果是 c。
private static void skip() {Stream<String> a = Stream.of("a", "b", "c");
a.skip(2).forEach(e->System.out.println(e));
}
distinct
元素去重,例如下面方法返回元素是 a、b、c,将重复的 b 只保留了一个。
private static void distinct() {Stream<String> a = Stream.of("a", "b", "c","b");
a.distinct().forEach(e->System.out.println(e));
}
sorted
有两个重载,一个无参数,另外一个有个 Comparator类型的参数。
无参类型的按照自然顺序进行排序,只适合比较单纯的元素,比如数字、字母等。
private static void sorted() {Stream<String> a = Stream.of("a", "c", "b");
a.sorted().forEach(e->System.out.println(e));
}
有参数的需要自定义排序规则,例如下面这个方法,按照第二个字母的大小顺序排序,最后输出的结果是 a1、b3、c6。
private static void sortedWithComparator() {Stream<String> a = Stream.of("a1", "c6", "b3");
a.sorted((x,y)->Integer.parseInt(x.substring(1))>Integer.parseInt(y.substring(1))?1:-1).forEach(e->System.out.println(e));
}
为了更好的说明接下来的几个 API ,我模拟了几条项目中经常用到的类似数据,10条用户信息。
private static List<User> getUserData() {Random random = new Random();
List<User> users = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
User user = new User();
user.setUserId(i);
user.setUserName(String.format("古时的风筝 %s 号", i));
user.setAge(random.nextInt(100));
user.setGender(i % 2);
user.setPhone("18812021111");
user.setAddress("无");
users.add(user);
}
return users;
}
filter
用于条件筛选过滤,筛选出符合条件的数据。例如下面这个方法,筛选出性别为 0,年龄大于 50 的记录。
private static void filter(){List<User> users = getUserData();
Stream<User> stream = users.stream();
stream.filter(user -> user.getGender().equals(0) && user.getAge()>50).forEach(e->System.out.println(e));
/**
*等同于下面这种形式 匿名内部类
*/
// stream.filter(new Predicate<User>() {
// @Override
// public boolean test(User user) {
// return user.getGender().equals(0) && user.getAge()>50;
// }
// }).forEach(e->System.out.println(e));
}
map
map方法的接口方法声明如下,接受一个 Function函数式接口,把它翻译成映射最合适了,通过原始数据元素,映射出新的类型。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);而 Function的声明是这样的,观察 apply方法,接受一个 T 型参数,返回一个 R 型参数。用于将一个类型转换成另外一个类型正合适,这也是 map的初衷所在,用于改变当前元素的类型,例如将 Integer 转为 String类型,将 DAO 实体类型,转换为 DTO 实例类型。
当然了,T 和 R 的类型也可以一样,这样的话,就和 peek方法没什么不同了。
@FunctionalInterfacepublic interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
}
例如下面这个方法,应该是业务系统的常用需求,将 User 转换为 API 输出的数据格式。
private static void map(){List<User> users = getUserData();
Stream<User> stream = users.stream();
List<UserDto> userDtos = stream.map(user -> dao2Dto(user)).collect(Collectors.toList());
}
private static UserDto dao2Dto(User user){
UserDto dto = new UserDto();
BeanUtils.copyProperties(user, dto);
//其他额外处理
return dto;
}
mapToInt
将元素转换成 int 类型,在 map方法的基础上进行封装。
mapToLong
将元素转换成 Long 类型,在 map方法的基础上进行封装。
mapToDouble
将元素转换成 Double 类型,在 map方法的基础上进行封装。
flatMap
这是用在一些比较特别的场景下,当你的 Stream 是以下这几种结构的时候,需要用到 flatMap方法,用于将原有二维结构扁平化。
- Stream<String[]>
- Stream<Set<String>>
- Stream<List<String>>
以上这三类结构,通过 flatMap方法,可以将结果转化为 Stream<String>这种形式,方便之后的其他操作。
比如下面这个方法,将List<List<User>>扁平处理,然后再使用 map或其他方法进行操作。
private static void flatMap(){List<User> users = getUserData();
List<User> users1 = getUserData();
List<List<User>> userList = new ArrayList<>();
userList.add(users);
userList.add(users1);
Stream<List<User>> stream = userList.stream();
List<UserDto> userDtos = stream.flatMap(subUserList->subUserList.stream()).map(user -> dao2Dto(user)).collect(Collectors.toList());
}
flatMapToInt
用法参考 flatMap,将元素扁平为 int 类型,在 flatMap方法的基础上进行封装。
flatMapToLong
用法参考 flatMap,将元素扁平为 Long 类型,在 flatMap方法的基础上进行封装。
flatMapToDouble
用法参考 flatMap,将元素扁平为 Double 类型,在 flatMap方法的基础上进行封装。
collection
在进行了一系列操作之后,我们最终的结果大多数时候并不是为了获取 Stream 类型的数据,而是要把结果变为 List、Map 这样的常用数据结构,而 collection就是为了实现这个目的。
就拿 map 方法的那个例子说明,将对象类型进行转换后,最终我们需要的结果集是一个 List<UserDto >类型的,使用 collect方法将 Stream 转换为我们需要的类型。
下面是 collect接口方法的定义:
<R, A> R collect(Collector<? super T, A, R> collector);下面这个例子演示了将一个简单的 Integer Stream 过滤出大于 7 的值,然后转换成 List<Integer>集合,用的是 Collectors.toList()这个收集器。
private static void collect(){Stream<Integer> integerStream = Stream.of(1,2,5,7,8,12,33);
List<Integer> list = integerStream.filter(s -> s.intValue()>7).collect(Collectors.toList());
}
很多同学表示看不太懂这个 Collector是怎么一个意思,来,我们看下面这段代码,这是 collect的另一个重载方法,你可以理解为它的参数是按顺序执行的,这样就清楚了,这就是个 ArrayList 从创建到调用 addAll方法的一个过程。
private static void collect(){Stream<Integer> integerStream = Stream.of(1,2,5,7,8,12,33);
List<Integer> list = integerStream.filter(s -> s.intValue()>7).collect(ArrayList::new, ArrayList::add,
ArrayList::addAll);
}
我们在自定义 Collector的时候其实也是这个逻辑,不过我们根本不用自定义, Collectors已经为我们提供了很多拿来即用的收集器。比如我们经常用到Collectors.toList()、Collectors.toSet()、Collectors.toMap()。另外还有比如Collectors.groupingBy()用来分组,比如下面这个例子,按照 userId 字段分组,返回以 userId 为key,List 为value 的 Map,或者返回每个 key 的个数。
// 返回 userId:List<User>Map<String,List<User>> map = user.stream().collect(Collectors.groupingBy(User::getUserId));
// 返回 userId:每组个数
Map<String,Long> map = user.stream().collect(Collectors.groupingBy(User::getUserId,Collectors.counting()));
toArray
collection是返回列表、map 等,toArray是返回数组,有两个重载,一个空参数,返回的是 Object[]。
另一个接收一个 IntFunction<R>类型参数。
@FunctionalInterfacepublic interface IntFunction<R> {
/**
* Applies this function to the given argument.
*
* @param value the function argument
* @return the function result
*/
R apply(int value);
}
比如像下面这样使用,参数是 User[]::new也就是new 一个 User 数组,长度为最后的 Stream 长度。
private static void toArray() {List<User> users = getUserData();
Stream<User> stream = users.stream();
User[] userArray = stream.filter(user -> user.getGender().equals(0) && user.getAge() > 50).toArray(User[]::new);
}
reduce
它的作用是每次计算的时候都用到上一次的计算结果,比如求和操作,前两个数的和加上第三个数的和,再加上第四个数,一直加到最后一个数位置,最后返回结果,就是 reduce的工作过程。
private static void reduce(){Stream<Integer> integerStream = Stream.of(1,2,5,7,8,12,33);
Integer sum = integerStream.reduce(0,(x,y)->x+y);
System.out.println(sum);
}
另外 Collectors好多方法都用到了 reduce,比如 groupingBy、minBy、maxBy等等。
并行 Stream
Stream 本质上来说就是用来做数据处理的,为了加快处理速度,Stream API 提供了并行处理 Stream 的方式。通过 users.parallelStream()或者users.stream().parallel() 的方式来创建并行 Stream 对象,支持的 API 和普通 Stream 几乎是一致的。
并行 Stream 默认使用 ForkJoinPool线程池,当然也支持自定义,不过一般情况下没有必要。ForkJoin 框架的分治策略与并行流处理正好契合。
虽然并行这个词听上去很厉害,但并不是所有情况使用并行流都是正确的,很多时候完全没这个必要。
什么情况下使用或不应使用并行流操作呢?
- 必须在多核 CPU 下才使用并行 Stream,听上去好像是废话。
- 在数据量不大的情况下使用普通串行 Stream 就可以了,使用并行 Stream 对性能影响不大。
- CPU 密集型计算适合使用并行 Stream,而 IO 密集型使用并行 Stream 反而会更慢。
- 虽然计算是并行的可能很快,但最后大多数时候还是要使用 collect合并的,如果合并代价很大,也不适合用并行 Stream。
- 有些操作,比如 limit、 findFirst、forEachOrdered 等依赖于元素顺序的操作,都不适合用并行 Stream。
最后
Java 25 周岁了,有多少同学跟我一样在用 Java 8,还有多少同学在用更早的版本,请说出你的故事。
以上是 一文搞懂Java8的Lambda、函数式接口、Stream用法及原理 的全部内容, 来源链接: utcz.com/a/22888.html